목차
앞서 대표적인 심층 생성 모델인 AutoRegressive Models (ARMs), Flow-based Models와 Latent variable models 중 VAE까지 살펴보았다. 최근 내가 연구하고 있는 주제에서는 VAE, Diffusion, GAN 기반의 모델이 활발하게 이용된다. 특히 diffusion의 우수한 성능은 따로 설명이 필요 없을 정도로 유명하고(실제로 세계적인 학회에 가면 과장 조금 보태서 30~40% 정도는 diffusion 관련 논문이 쏟아지고 있다.), VAE와 GAN을 기반으로 하는 다양한 우수한 성능을 보이는 모델이 나오고 있다.
이번 포스팅에서는 GAN을 수식과 함께 깊이있게 다뤄보려 한다. 내용은 이전 글과 마찬가지로 대부분 'Deep Generative Modeling' 책을 참고하였다.
Latent variable model 중 하나인 VAE는 이전에 아래 글에서 다루었다.
Variational Auto-Encoder (VAE) 파헤치기! (1)
목차 앞서 대표적인 심층 생성 모델인 AutoRegressive Models (ARMs), Flow-based Models 두 가지를 살펴보았다. 하지만, (적어도 내가 연구하고 있는 분야에서는) 최근에는 VAE, Diffusion, GAN 기반의 모델이 활발
jjuke-brain.tistory.com
Variational Auto-Encoder (VAE) 파헤치기! (2)
목차 앞서 대표적인 심층 생성 모델인 AutoRegressive Models (ARMs), Flow-based Models 두 가지를 살펴보았다. 하지만, (적어도 내가 연구하고 있는 분야에서는) 최근에는 VAE, Diffusion, GAN 기반의 모델이 활발
jjuke-brain.tistory.com
Introduction
우선, deep generative models의 분류 그림과 비교 표를 한 번 살펴보고 넘어가자.
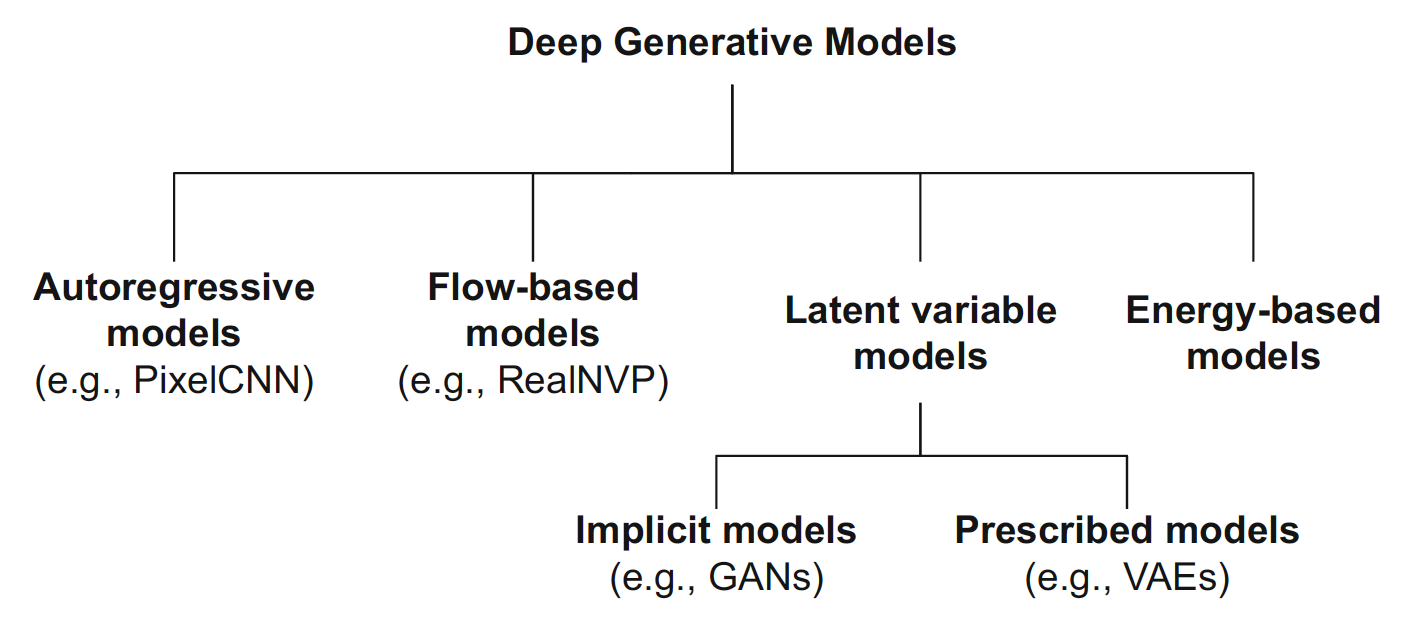
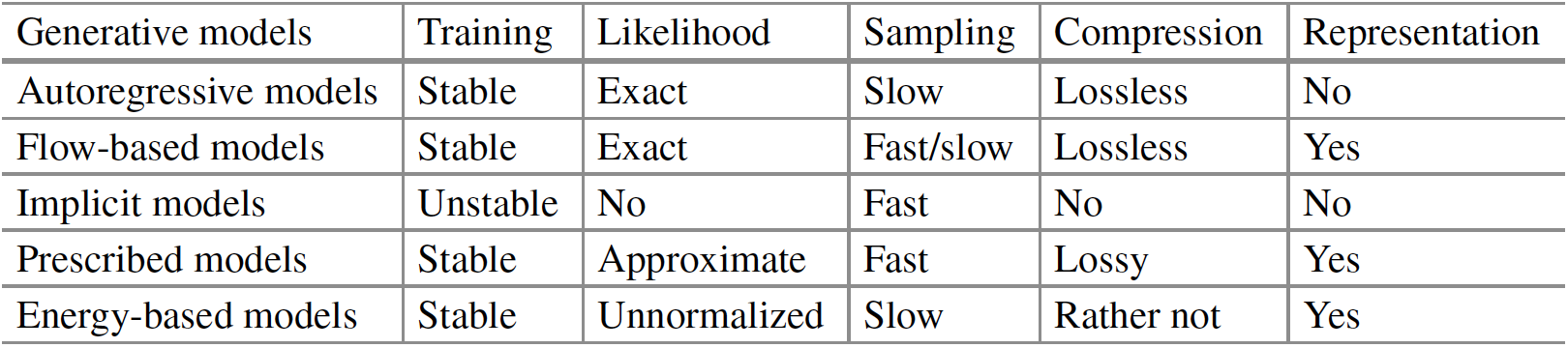
이 포스팅에서 다룰 GAN은 이전에 다룬 VAE와 latent variable model이라는 점에서 같고, 데이터, latent variable 등과 관련된 distribution을 사전에 formulate해주지 않고 implicit하게 모델링한다는 점에서 차이가 있다.
Latent Variable Models (Recap VAEs)
우선 latent variable model, 특히 Variational Autoencoders (VAEs)를 간단하게 다시 살펴보자. VAE의 Generative process는 아래와 같다.
- Latent sampling \( \mathbf{z} \sim p(\mathbf{z}) \)
- Latent로부터 새로운 observable(새로운 data point) 생성 \( \mathbf{x} \sim p_\theta(\mathbf{x} \vert \mathbf{z}) \)
Training objective는 Marginal log-likelihood function을 최대화하는 것이다.
\( \log p_\theta(\mathbf{x}) = \log \int p_\theta (\mathbf{x} \vert \mathbf{z}) p(\mathbf{z}) \, d \mathbf{z} \)
여기서 문제가 하나 있는데, marginalize 과정에서 관측되지 않은 random variable을 제거한다는 점이다.
그리고 식의 Integral은 정확한 계산이 불가능하므로, prior \(p(\mathbf{z})\)로부터 Monte Carlo sampling을 통해 근사한다.
\( \begin{align*} \log p_\theta(\mathbf{x}) &= \log \int p_\theta (\mathbf{x} \vert \mathbf{z}) p(\mathbf{z}) \, d \mathbf{z} \\ & \approx \log \cfrac{1}{S} \sum\limits_{s=1}^S p_\theta (\mathbf{x} \vert \mathbf{z}_S) \\ &= \log \sum\limits_{s=1}^S \operatorname{exp}( \log p_\theta(\mathbf{x} \vert \mathbf{z}_S)) - \log S \\ &= \operatorname{LogSumExp}_S \{ p_\theta(\mathbf{x} \vert \mathbf{z}_S) \} - \log S \end{align*} \)
여기서 Log-sum-exp function \( \operatorname{LogSumExp}_S \{ f(s) \} = \log \sum_{s=1}^S \operatorname{exp}(f(s)) \)은 미분이 가능(differentiable)한 함수이다. 그리고 보통 prior는 간단한 distribution(standard Gaussian distribution)으로 가정한다.
Density Networks

이렇게 Fig 3과 같이 noise distribution \( \mathcal{N}(\boldsymbol{0}, \mathbf{I})\)에서 샘플링한 latent \(\mathbf{z}\)를 neural network에 입력하여 distribution(예를 들면 Gaussian distribution의 mean과 variance)을 decoding하는 network를 density network로 통칭한다.
위에서 소개한 대로, prior distribution \(p(\mathbf{z})\)를 standard Gaussian \( \mathcal{N}(\boldsymbol{0}, \mathbf{I}) \)으로 가정했으므로, conditional likelihood \(p_\theta(\mathbf{x} \vert \mathbf{z})\)만 모델링하면 된다. 즉, 미리 모든 distribution을 수학적으로 표현(formulate)해야 한다. 이러한 deep generative model을 prescribed model이라 하며, VAE가 가장 대표적인 prescribed model이다.
이러한 접근법은 Latent variable model을 이해하고 성능을 향상시키는 데 도움이 되며, prescribed model과 implicit model의 차이를 이해할 수 있다. 그러나 이 방법으로 analytical solution을 얻을 수 없고, prior에서 많은 샘플링이 필요하며, 차원의 저주(curse of dimensionality)라는 큰 문제점이 있다.
이러한 Curse of dimensionality를 해결하기 위해 VAE(prescribed model)에서는 Variational inference를 활용한다. 그런데, latent variable model의 또 다른 갈래인 implicit model에서는 likelihood 기반의 모델 대신에 implicit model을 활용한다. 그 대표적인 예가 Generative Adversarial Networks (GANs)이다.
Implicit Modeling with Generative Adversarial Networks (GANs)
결국 생성 모델 학습을 할 때, log-likelihood function을 통해 하고자 하는 것은 training data와 생성된 data를 비교하는 것이다. GAN에서는 VAE에서 사용하던 KL divergence loss term 대신에 다른 metric을 통해 비교하려 한다. 또한, 꼭 처음부터 사전 정의된 모델 (prescribed model)을 활용해야 할지에 대한 의문도 제기한다. Latent로부터 full distribution을 얻는 것이 아니라, data point 하나씩을 얻는 implicit model을 고안한다.
Implicit Modeling
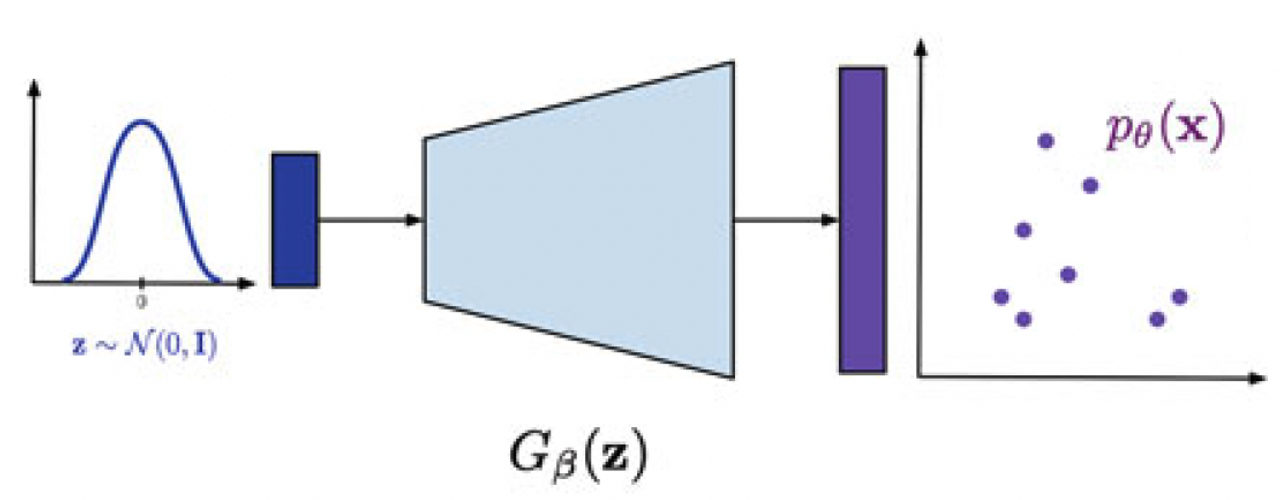
위에서도 언급했듯, Fig 4에서처럼 implicit model은 data의 distribution(mean, variance)이 아닌 data point를 하나씩 생성한다. 이러한 방법으로 decoding하는 neural network를 Dirac delta function을 활용하여 수식으로 표현하자면 아래와 같다.
\( p_\theta(\mathbf{x} \vert \mathbf{z}) = \delta(\mathbf{x} - \operatorname{NN}_\theta(\mathbf{z})) \)
여기서 Dirac's delta function은 다음과 같이 정의된다.
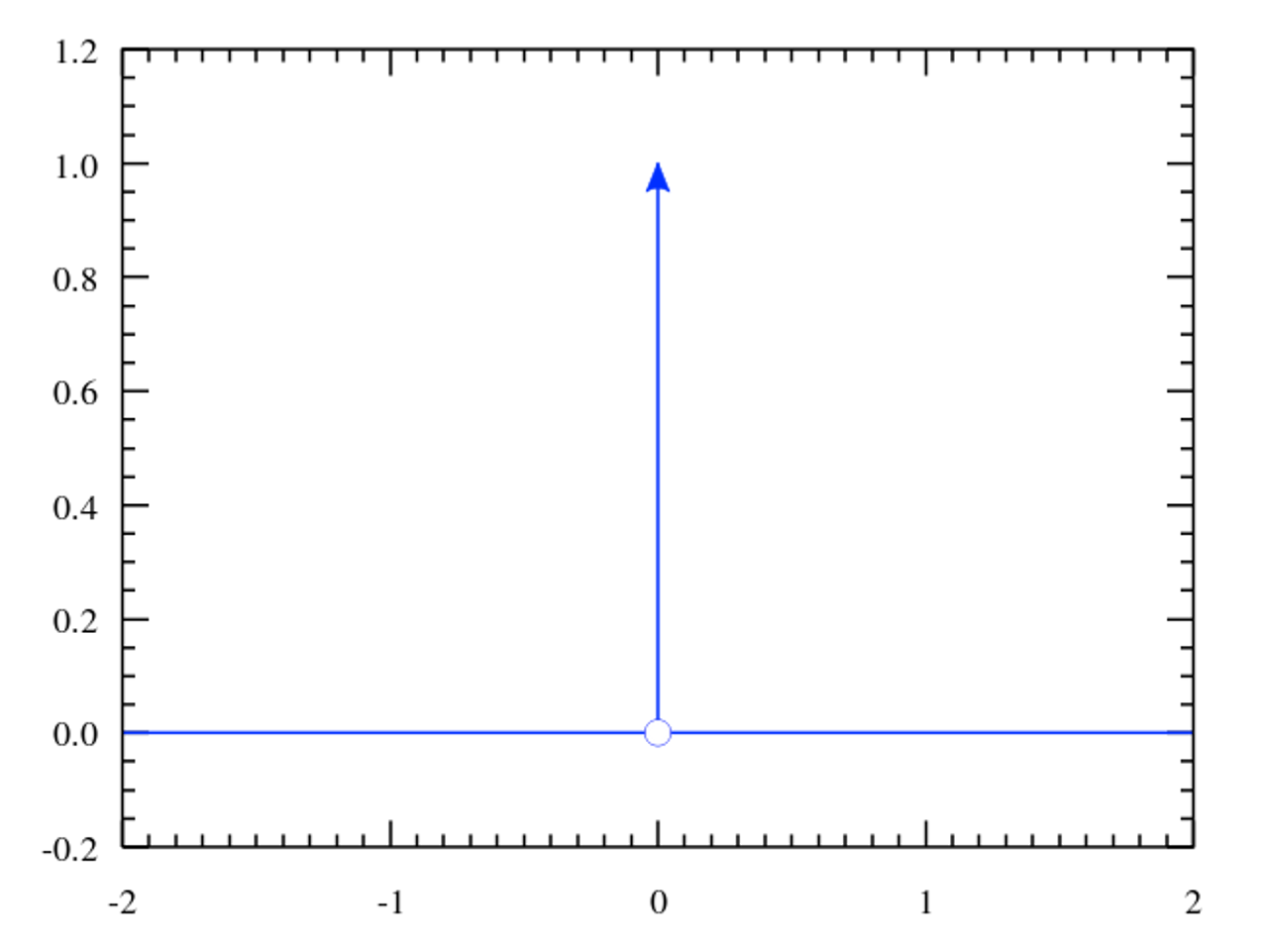
\( \delta(x) = \underset{b \rightarrow 0}{\lim} \cfrac{1}{\vert b \vert \sqrt{\pi}} e^{-(x/b)^2} \)
Decoding 과정에서의 Dirac delta function을 보면, latent \(\mathbf{z}\)를 입력받은 neural network 결과 중에서 peak 값만 존재하게 되는 것이다. 그 peak 값이 data point 하나가 될 것이다. 실제 동작할 때에는 neural network \(\operatorname{NN}_\theta\)가 mean과 variance 대신 mean만 출력하는 것을 의미한다.
Marginal distribution은 Delta peak의 mixture로 표현된다.
\( p_\theta(\mathbf{x}) = \int \delta(\mathbf{x} - \operatorname{NN}_\theta(\mathbf{z})) p(\mathbf{z}) \, d \mathbf{z} \)
무수히 많은 \mathbf{z}에 대해 peak 값을 얻다 보면, observable space에서 어떤 지역(region)은 다른 곳보다 dense하게 point 값이 많이 분포하게 될 것이다. 이것이 결국 Fig 3에서 density network의 결과였던, 모델이 생성할 때 샘플링할 distribution이 되는 것이다. 이 전반적인 과정을 implicit modeling이라 한다.
이러한 접근법의 문제점은 loss function을 계산할 수 없는 ill-defined term \( \log \delta(\mathbf{x} - \operatorname{NN}_\theta(\mathbf{z})) \)이 존재한다는 것이다. 이를 해결하기 위해 Adversarial loss를 도입한다.
Adversarial Loss
Adversarial loss에서 활용할 주요 용어부터 알아보자.
Data point \( \mathbf{x}\) 중에서, real data(ex. dataset의 이미지)는 emperical distribution \(p_\text{data}(\mathbf{x})\)에서 샘플링한 data point이며, fake data(ex. 모델이 생성한 이미지)는 generator \(G\)가 생성한 data point이다.
Discriminator, generator
Discriminator \(D\)는 data가 진짜인지, 가짜인지를 분류하는 classifier로, neural network로 parameterize한다.
\( D : \mathcal{X} \rightarrow [0, 1] \)
Generator는 noise를 입력 받아 fake data를 생성하며, 또다른 neural network로 parameterize한다.
\( G : \mathcal{Z} \rightarrow \mathcal{X} \)
Objective function(Adversarial loss)
Objective function을 살펴보자. 우선 data source가 real data \(\mathbf{x} \sim p_\text{data}(\mathbf{x})\), fake data \(\mathbf{x} \sim p_\theta(\mathbf{x}) = \int G(\mathbf{z}) p(\mathbf{z}) \, d \mathbf{z} \)로 두 가지이다.
Discriminator는 입력 데이터가 fake이면 0, real이면 1로 예측하도록 하는 (binary) classification task를 수행한다. 따라서 binary cross-entropy loss를 활용하여 다음과 같이 나타낼 수 있다.
\( \mathcal{L} = \mathbb{E}_{\mathbf{x} \sim p_\text{data}} \left[ \log D(\mathbf{x}) \right] + \mathbb{E}_{\mathbf{z} \sim p(\mathbf{z})} \left[ \log (1 - D (G(\mathbf{z})) \right] \)
왼쪽 term은 real data source, 오른쪽 term은 fake data source에 해당한다.
Discriminator가 예측할 정답값을 \(y\)로 표현하여 좀 더 쉬운 표현으로 바꾸자면, binary cross-entropy는 다음과 같이 계산할 수 있다.
\( \operatorname{BCE} = y \log ( D(\mathbf{x})) + (1 - y) \log (1 - D(\mathbf{x})) \)
Discriminator 입장에서는 BCE를 최대화 하는 것이 목표이다. 즉, real data를 입력받았을 때(\(y=1\)), real으로 예측(\(D(\mathbf{x}) = 1\))하고, fake data를 입력받았을 때(\(y=0\)), fake로 예측(\(D(\mathbf{x}) = 0\))해야 이상적인 discriminator이고, BCE가 최댓값이 된다.
Generator 입장에서는 BCE 값을 최소화해야 한다.
\( \operatorname{BCE} = y \log ( D(\mathbf{x})) + (1 - y) \log (1 - D(G(\mathbf{z}))) \)
Generator가 fake data를 생성하여 discriminator에게 넘겨줬을 때(\(y=0\)), discriminator가 real data로 판단하도록 속여야(\(D(G(\mathbf{z})) = 1)\) 이상적인 generator이고, 이 때 BCE는 최소화된다.
이를 종합하면 최종 adversarial loss는 다음과 같이 나타낼 수 있다.
\( \underset{G}{\min} \underset{D}{\max} \, \mathbb{E}_{\mathbf{x} \sim p_\text{data}} \left[ \log D(\mathbf{x}) \right] + \mathbb{E}_{\mathbf{z} \sim p(\mathbf{z})} \left[ \log (1 - D (G(\mathbf{z})) \right] \)
Adversarial이라는 이름이 붙은 이유는, generator와 discriminator가 서로 반대되는(adversarial) objective를 갖고 학습을 진행하기 때문이다.
학습할 때에는 min-max problem을 최적화하는 방법을 사용한다. 이때 backpropagation, stochastic gradient descent 등을 활용할 수 있다.
GANs
GAN 모델의 학습 과정은 아래 그림과 같이 나타낼 수 있다.
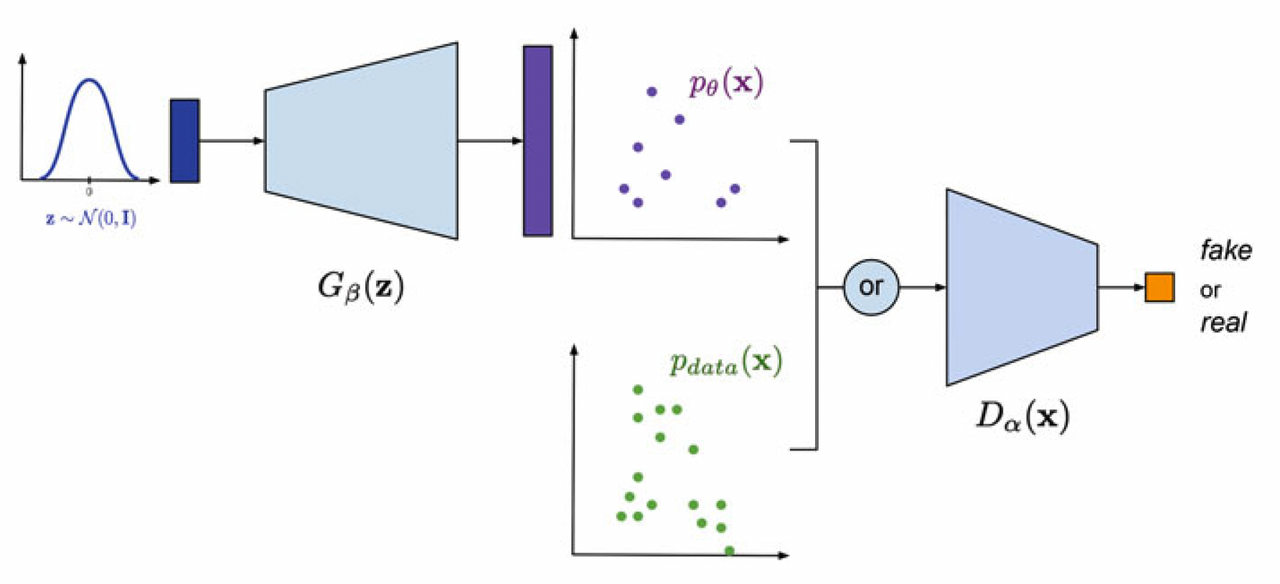
Implementation
간단한 GAN을 구현해보자.
먼저, generator와 discriminator class를 구현한다.
class Generator(nn.Module):
def __init__(self, generator_net, z_size):
super(Generator, self).__init__()
# Init the generator neural network
self.generator_net = generator_net
# Size(dimension) of the latents
self.z_size = z_size
def generate(self, z):
# Generate a sample point given z
return self.generator_net(z)
def sample(self, batch_size=32):
# At first, sample the latents
z = torch.randn(batch_size, self.z_size)
return self.generate(z)
def forward(self, z=None):
if z is None:
return self.sample()
else:
return self.generate(z)
class Discriminator(nn.Module):
def __init__(self, discriminator_net):
super(Discriminator, self).__init__()
# Init the discriminator neural net
self.discriminator_net = discriminator_net
def forward(self, x):
# Just classify (apply the neural net)
return self.discriminator_net(x)
두 클래스를 활용하여 GAN class를 구현한다.
class GAN(nn.Module):
def __init__(self, generator, discriminator, eps=1.e-5)
super(GAN, self).__init__()
# Init generator and discriminator
self.generator = generator
self.discriminator = discriminator
# small epsilon value for numerical issue
self.eps = eps
def forward(self, x_real, reduction='avg', mode'discriminator'):
# calculate adversarial loss
if mode == 'generator':
# sample fake data
x_fake_gen = self.generator.sample(x_real.shape[0])
# calculate output of discriminator for fake data (using clamp for numerical stability)
d_fake = torch.clamp(self.discriminator(x_fake_gen), self.eps, 1. - self.eps)
# loss for the generator
loss = torch.log(1. - d_fake)
elif mode == 'discriminator':
# calculate outputs of discriminator for both fake and real data
x_fake_gen = self.generator.sample(x_real.shape[0])
d_fake = torch.clamp(self.discriminator(x_fake_gen), self.eps, 1. - self.eps)
d_real = torch.clamp(self.discriminator(x_real), self.eps, 1. - self.eps)
# final adversarial loss for the discriminator
loss = -(torch.log(d_real) + torch.log(1. - d_fake))
if reduction == 'sum':
return loss.sum()
else:
return loss.mean()
def sample(self, batch_size=32):
return self.generator.sample(batch_size=batch_size)
예를 들어, generator와 discriminator를 MLP로 간단히 구현하면 아래와 같이 GAN model을 구현할 수 있다.
# Generator network and Discriminator network
generator_net = nn.Sequential(nn.Linear(L, M), nn.ReLU(),
nn.Linear(M, D), nn.Tanh())
generator = Generator(generator_net, z_size=L)
discriminator_net = nn.Sequential(nn.Linear(D, M), nn.ReLU(),
nn.Linear(M, 1), nn.Sigmoid())
discriminator = Discriminator(discriminator_net)
# GAN model
model = GAN(generator=generator, discriminator=discriminator)
학습을 할 때에는, discriminator와 generator를 둘 다 학습시켜야 하므로 optimizer를 두 개 사용해야 한다. Training loop를 구현해보면 아래와 같다.
for idx_batch, batch in enumerate(train_loader):
# for Discriminator
loss_dis = model.forward(batch, mode='discriminator')
optimizer_dis.zero_grad()
optimizer_gen.zero_grad()
loss_dis.backward()
optimizer_dis.step()
# for Generator
loss_gen = model.forward(batch, mode='generator')
optimizer_dis.zero_grad()
optimizer_gen.zero_grad()
loss_gen.backward()
optimizer_gen.step()








최근댓글