목차
이전 글에 이어, autoregressive generative model에 어떤 모델이 있는지 좀 더 살펴보자.
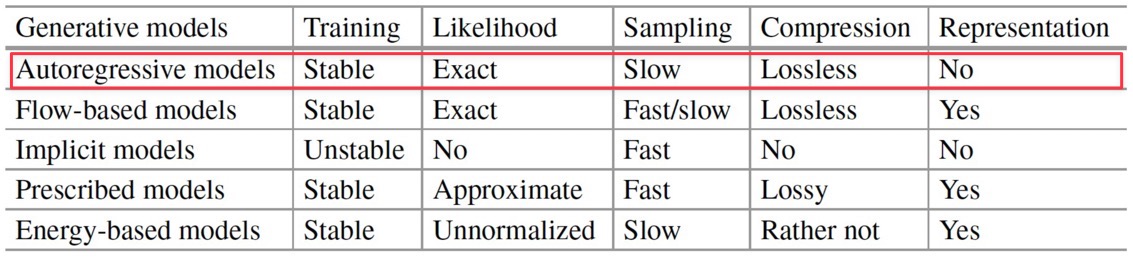
다음은 다양한 deep generative model 의 비교 표이다.
Autoencoder based ARM
Autoregressive Models (ARM) vs Autoencoders (AE)
Autoencoder
먼저 autoencoder에 대해 간단히 알아보고 비교해보자.
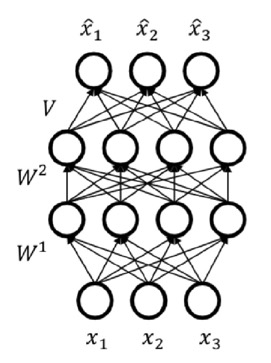
Autoencoder는 encoder \(e(\cdot)\)와 decoder \(d(e(x)) \approx x\)의 구조를 갖는다.
예를 들어 Fig 2에서 encoder는 \(e(\mathbf{x}) = \sigma(W_2 ( W_1 \mathbf{x} + b_1 ) + b_2)\))와 decoder \(d(h) = \sigma(Vh + c)\)로 이루어져 있고, loss function은 다음과 같이 나타낼 수 있다.
\( \underset{W_1, W_2, b_1, b_2, V, c}{\min} \sum\limits_{x \in D} \sum\limits_{i} -x_i \log \hat{x}_i - x_i \log (1 - \hat{x}_i) \)
\( \underset{W_1, W_2, b_1, b_2, V, c}{\min} \sum\limits_{x \in D} \sum\limits_{i} (x_i - \hat{x}_i)^2 \)
위는 \(x\)가 binary random value일 때 사용하는 binary cross entropy(BCE) loss, 아래는 continuous random variable일 때 사용하는 L2 loss이다.
보통 autoencoder를 사용하는 목적은 input과 똑같은 reconstruction 결과물을 얻는 것 보다는 encoding의 결과인 \(e(x)\)가 \(x\)를 잘 표현(representation)하는 feature이길 바라는 것이므로 (feature learning), encoder와 decoder에 constraint를 부여하게 된다.
그렇다 해도 기본적인 형태의 autoencoder는 generative model은 아니다. 새로운 데이터를 생성하기 위해 sampling할 때 필요한 \(\mathbf{x}\)에 대한 distribution을 정의하는 게 아니기 때문이다.
Generative model from an autoencoder

그런데, Fig 3에서와 같이 input으로부터 데이터를 추정(estimate)한다는 점에서 FVSBN과 NADE는 autoencoder와 비슷해 보인다. 그럼 autoencoder를 generative model로 활용하려면 어떻게 해야하는 지 알아보자.
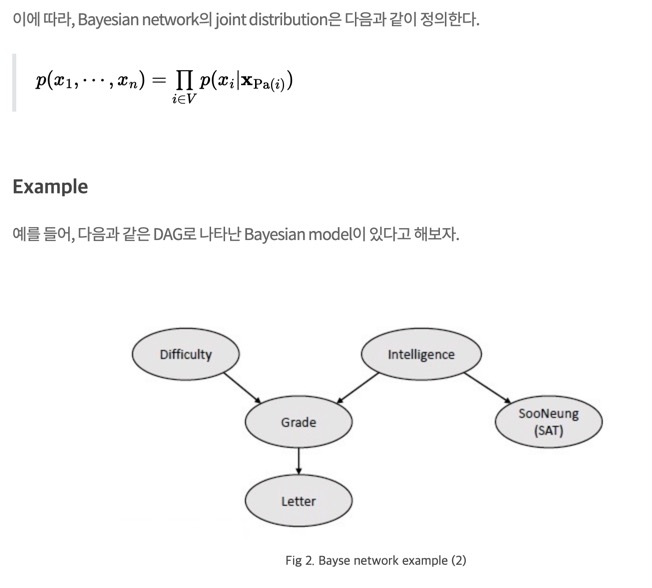
우선 네트워크가 Bayesian Network (DAG structure)여야 한다. 즉, ordering이 필요하다.
예를 들어, Fig 3의 autoencoder를 살펴보자. Ordering이 1, 2, 3 순서라면, \(\hat{x}_1\)은 어떤 input \(x\)에도 의존하지 않는다. 즉 generation 시 input이 필요하지 않다. 그리고 \(\hat{x}_2\)는 \(x_1\)에, \(\hat{x}_3\)는 \(x_1, x_2\)에, 이런 식으로 dependency가 생길 것이다.
이때 \(n\)개 output을 내는 neural network 하나를 사용해볼 수 있다. (NADE의 경우 \(n\)번의 pass를 거치면 된다.)
Masked AE for Distribution Estimation (MADE)
MADE는 masking을 활용하여 autoencoder를 generative model에 활용한 모델이다.

Autoencoder를 autoregressive하게 활용하기 위해(DAG structure를 갖게 하기 위해, 즉 ordering을 부여하기 위해) masking을 하여 특정 path를 끊어준다. Fig 4에서, ordering이 \(x_2, x_3, x_1\) 순서라고 해보자. (ordering은 Fig 4에서 각 unit 안에 표시되어 있다.)
- 첫 번째 순서인 \(x_2\)의 distribution \(p(x_2)\)의 parameter를 생성하는 unit은 어떤 input에도 의존하지 않으며, \(p(x_3|x_2)\)는 input \(x_2\)에만, \(p(x_1|x_2, x_3)\)는 input \(x_2, x_3\)에 의존한다.
- Hidden layer에서 각 unit에 대해 \([1, n-1]\)(예시에서 n=3) 범위에서 integer를 랜덤으로 골라 해당 unit이 의존할 input을 정한다. 예를 들어, 2를 골랐으면 1(\(x_2\))과 2(\(x_3\))에 의존하게 된다.
- Mask를 추가하여 몇몇 path(connection)를 없앤다. Fig 4에서 \(M^{W^1}\)을 보면, 첫 번째 열(첫 번째 unit, 즉 \(x_1\))의 path는 전부 masking(0)되어있다. 따라서 오른쪽 그림처럼 \(x_1\) unit은 아무런 connection이 없는 것이다. 마찬가지로 \(x_3\)의 경우 두 번째 path가 끊겨 있다.
이렇게 masking을 하면 \(p(x_3 | x_2)\)에 대해 Fig 4에서 빨갛게 표시한 것과 같이 Bayes network의 DAG structure를 얻을 수 있다. Bayes network의 DAG structure 예시는 아래와 같다. 자세한 내용은 링크를 참조하자.
RNN based ARMs
이전 글에서 RNN으로 Autoregressive Model을 모델링하는 방법을 설명했다. Autoencoder 기반 모델들은 input과 output dimension이 고정되어있지만, RNN은 임의의 length를 다룰 수 있다는 장점을 갖고 있다.
그 예시를 알아보자.
Character RNN
Character RNN은 text를 다루는 RNN 기반 autoregressive generative model이다.

\(x_i \in \{h, e, l, o \}\)라 가정하면, one-hot encoding을 활용하여 Fig 6에서의 input layer처럼 나타낸다. 이에 따라 "hello"라는 문자열의 distribution은 다음과 같이 autoregressive하게 나타낼 수 있다.
\( p( x = hello) = p(x_1 = h) p(x_2 = e | x_1 = h) \cdots p(x_5 = o | x_1 = h, \dots, x_4=l)\)
이 모델은 요즘 핫한 chatGPT의 근간이 되는 모델이기도 하다. 하지만, 주어진 past data에 따라 가장 높은 확률의 다음 단어를 생성할 뿐, feqture encoding을 하는 게 아님에 주목하자.
PixelRNN
PixelRNN은 image를 다루는 RNN 기반 autoregressive generative model이다.
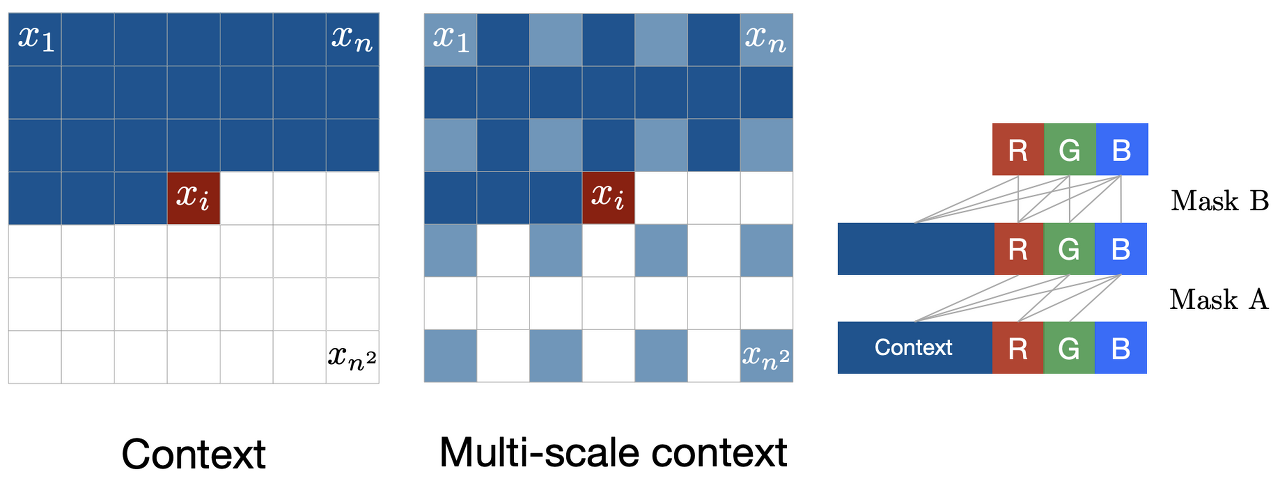
Fig 7과 같이 image를 pixel의 순서대로 다루는데, pixel conditional \(p(x_t | x_{1:t-1})\) 3개가 각각의 channel(RGB color)에 대한 piixel intensity(0 ~ 255)를 정한다.
실제로는 Fig 7 가운데 그림처럼 masking을 통해 multi-scale context를 고려하고, 정확하게는 RNN variants 중 하나인 LSTM을 활용하지만, 이 포스팅에서 자세히 다루지는 않겠다.
Pros and Cons of RNN based ARM
이전 글에서도 설명했지만, RNN을 활용한 autoregressive generative model의 장단점을 다시 한 번 살펴보자.
- Pros
- 임의의 lengt의 sequence에 적용이 가능하다.
- 모든 계산 가능한 함수에 대해 RNN을 적용할 수 있다. (일반적(general)으로 사용이 가능하다.)
- Cons
- Ordering이 필요하다.
- Likelihood evaluation 과정이 sequential하게 이루어진다. → 학습이 매우 느리다.
- Generation 과정이 sequential하게 이루어진다. → autoregressive model의 한계이다.
- Vanishing/exploding gradient problem이 존재한다. → 학습이 어렵다.
CNN based ARM
PixelCNN
다음으로는 image에서 RNN보다 훨씬 많이 활용되는 CNN을 기반으로 한 autoregressive generative model을 살펴보자.


Idea는 매우 간단한데, Fig 8, 9와 같이 masked convolution을 활용하여 주어진 context(이웃한 pixel)를 활용하여 다음 pixel을 예측하는 것이다.
PixelCNN vs PixelRNN
다음은 PixelCNN과 기본 LSTM 기반 PixelRNN과 BiLSTM 기반 PixelRNN을 비교한 그림이다.

연산의 속도와 log-likelihood의 quality는 trade-off 관계임을 알 수 있다.







최근댓글