목차
컴퓨터 비전 분야라고 하면 보통 2D image에서 물체를 탐지하는 등의 패턴 파악을 떠올린다. 하지만 3D 비전에서는 이미지가 아닌 더 다양한 형태로 3D 객체(object)나 장면(scene), 또는 형상(shape)을 표현한다. 이렇게 다양한 표현 방법에 따라 이를 학습하는 딥러닝 모델도 여러 종류가 존재한다.
이번 포스팅에서는 3차원 공간에 존재하는 object, scene, 특히 물체의 shape(surface)을 어떻게 표현하는지를 알아보려 한다. 이렇게 표현한 3D representation을 어떻게 학습하는지도 이어서 다룰 것인데, 이 포스팅과 연관하여 읽어보길 추천한다.
Representations for 3D Shape Learning
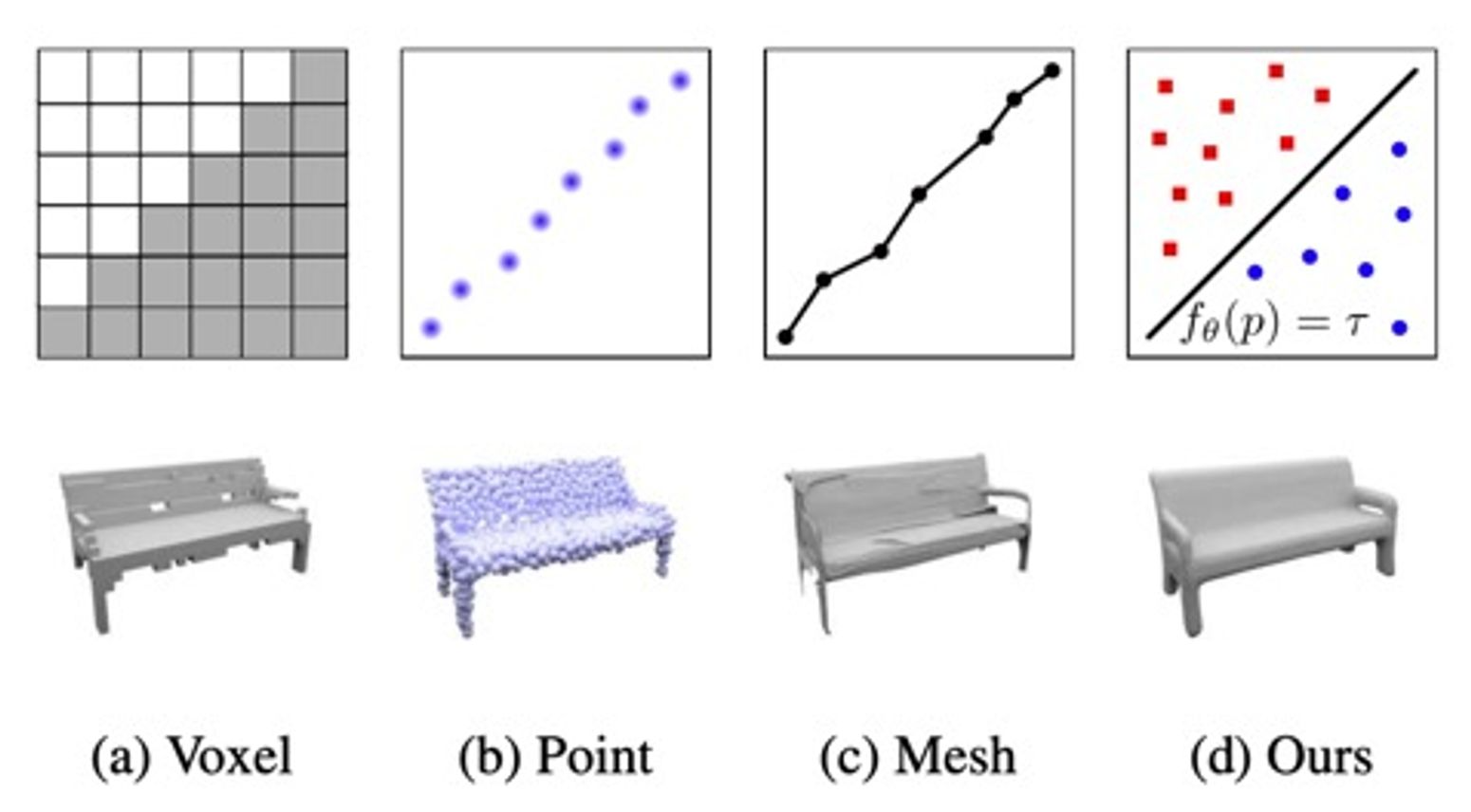
3D Shape을 학습하기 위해 데이터를 표현하는 방법은 크게 다음과 같이 나눠볼 수 있다.
- Point-based methods
- Mesh-based methods
- Voxel-based methods
- Implicit methods
각각을 간단히 알아보자.
Point-based Representation
Point cloud는 3차원 공간 상에 존재하는 점을 통해 3차원 데이터를 표현하는 방법이다.

다양한 센서가 제공하는 raw data와의 매칭이 잘 되는 3D representation으로, 3D learning(shape classification, semantic segmentation 등)에 적용하기 적합하다.
Point cloud를 활용하여 3D learning을 수행하는 대표적인 모델은 PointNet, PointNet++ 등이 있다.
PointNet은 point cloud를 직접적으로 활용하는 모델로, max pooling function으로 global shape feature를 뽑는데, 이러한 기능은 point generation task에서도 encoder로 많이 활용된다.
하지만 모양(topology)을 표현하는 데에는 한계가 있다. 점으로 데이터를 표현할 뿐, 틈이 없는(닫혀있는) surface(shape)를 나타내기에는 적절하지 않다.
Mesh-based representation
Mesh는 shape을 나타내기 위해 사전에 정의된 삼각형, 사각형 등의 template이다.
이렇게 사전에 정의된 template을 mesh로 사용하여 object class를 표현하는 방법은 shape generation task에서 좋은 성능을 보인다. 하지만, shape을 고정된 mesh 형태로밖에 표현하지 못한다는 단점이 있다.
이러한 한계를 보완하기 위해 2D plane을 morphing(변형)하여 3D surface를 표현하는 방법을 사용한다. 하지만 이 방법도 surface parameterization(3D shape의 surface와 2D domain 간의 연결)을 어떻게 하는가에 따라 성능이 좌우되고, parameterization 알고리즘은 input mesh의 quality와 cutting 방법에 따라 성능이 좌우된다.
Parameterization을 딥러닝 네트워크로 하는 방법이 바로 AtlasNet(Thibault Groueix et al., 'A Papier-Mache Approach to Learning 3D Surface Generation)이다. 이 모델의 한계점은 다음과 같다.
- 복잡한 형태를 나타내기 위해서는 여러 plane이 필요하다.
- 생성된 surface patch가 붙어있지 않다. 즉, shape이 닫혀있지 않다.
Voxel-based Representation
Voxel은 2D 이미지에서의 픽셀과 같이 3D 공간을 3D grid로 나눈 것이다. 이를 통해 3차원 형상을 나타내면 다음과 같이 나타난다.

Fig 4에서도 볼 수 있듯이, voxel 기반으로 형상을 표현하면 저해상도(low resolution,
따라서 voxel과 SDF를 혼합한 방법이 활용되기도 했다. (SDF에 대한 자세한 내용은 링크를 참조하자. 아주 간단하다!) Truncated SDF(TSDF)를 사용하여 noisy한 depth map을 3D model로 맵핑하는 방법이다. 하지만 voxel의 특성상 discrete하므로, memory가 부족하고, 마찬가지로 저해상도밖에 다루지 못한다. 관련하여 Wavelet transform-based methods, dimensionality reduction technique 등을 통해 보완하는 방법도 고안되었으나, 이러한 방법들은 shape을 다루기보다 scene을 다루는 데 더 최적화되어 있다.
Implicit representations (SDF, Occupancy)
Implicit representation이란 3D shape을 point, mesh, voxel이 아닌 어떤 함수를 통해 표현한 것을 말한다. 함수로 표현하므로 연속적(continuous)이고, smooth하게 형상을 표현할 수 있다.
DeepSDF
DeepSDF에서는 function으로 continuous SDF를 사용한다. SDF는 공간 상의 각각의 점을 가장 가까운 surface까지의 거리로 나타내는 함수이다. (자세한 설명은 링크를 참조하자. 아주 쉽다!)
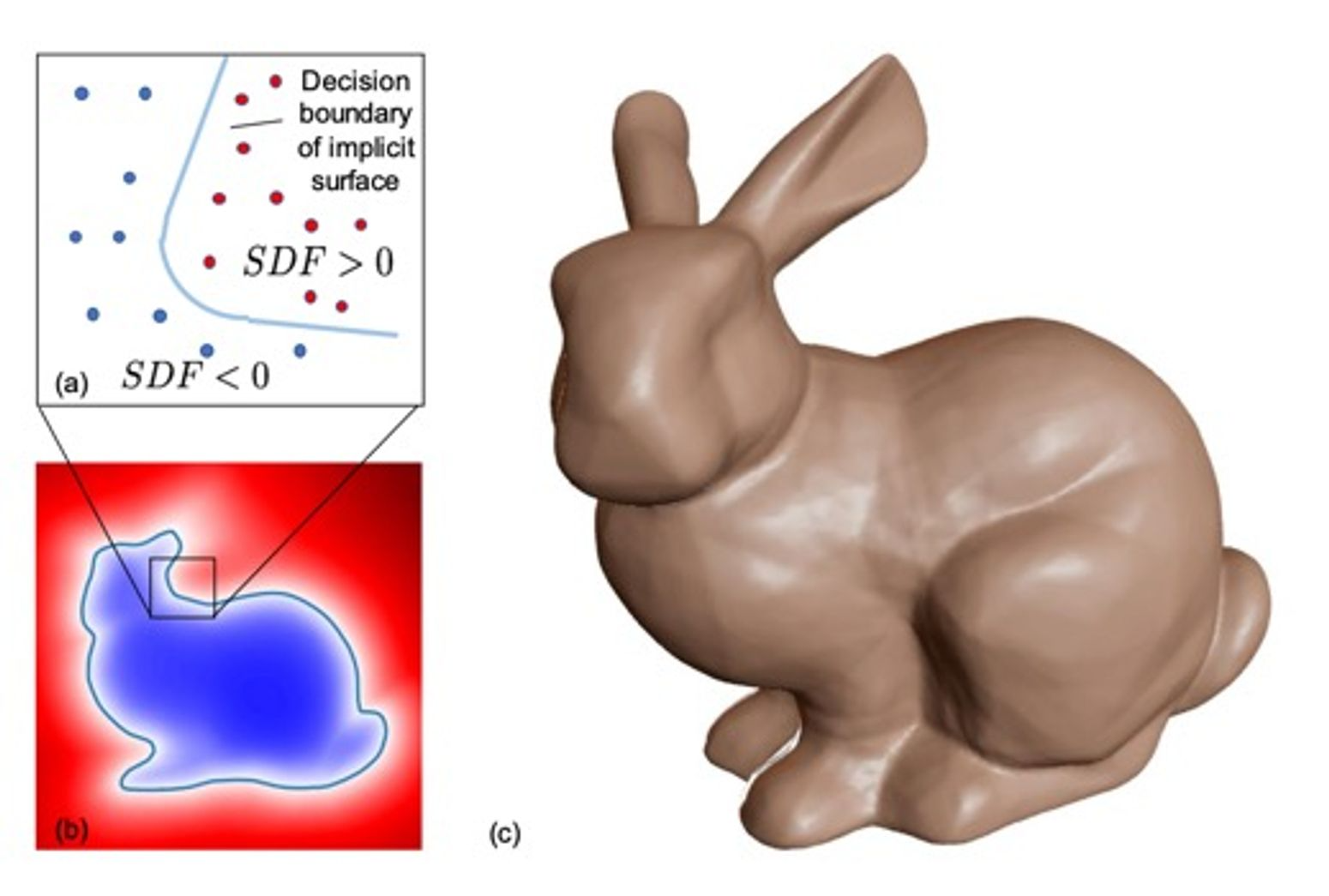
Fig 5에서 볼 수 있듯, surface는 값이 0인 점들의 집합으로 표현해볼 수 있다. (SDF는 부호를 고려(binary)하여 어떤 3D point가 shape 밖에 있으면 +, 안에 있으면 - 값을 갖는다.)
딥러닝 네트워크로 이러한 continuous SDF를 예측하는데, point나 voxel을 입력받아 SDF 값(scalar)을 출력한다. GT SDF 값과 예측한 SDF 값의 차이를 loss로 사용한다.
Occupancy Network
Occupancy Network는 function으로 binary function, 즉 각 점이 shape의 안에 있는지(occupy되었는지), 밖에 있는지만 나타낸다.
여기서는 딥러닝 네트워크로 binary function을 예측하는데, input 지점이 occupancy인지 예측하는 binary scalar를 출력한다. (classifier)








최근댓글