목차
3D Vision에서는 pointcloud 데이터를 자주 다룬다. 최초로 이 데이터를 직접적으로 다루는 모델인 PointNet을 제안한 논문 'Charles R. et al., PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation' 논문을 리뷰해보려 한다.
Motivation
기존에 3D data를 어떻게 표현(representation)할 것인가에 따라 다음과 같이 다양한 학습 방법이 있었다.
- Volumetric CNN : 3D Voxel로 표현된 3D representation을 다룸
- Multiview CNN : 3D point cloud나 shape을 2D image로 변환한 후 2D convolutional network 적용
- Spectral CNN : Mesh에 spectral CNN을 적용
- Feature-based Deep Neural Network : 3D data를 vector로 변환한 후 학습
특히, convolutional architecture의 경우 image에서의 2d grid, space에서의 3d voxel grid 등 규칙적인 input data format이 필요하다.
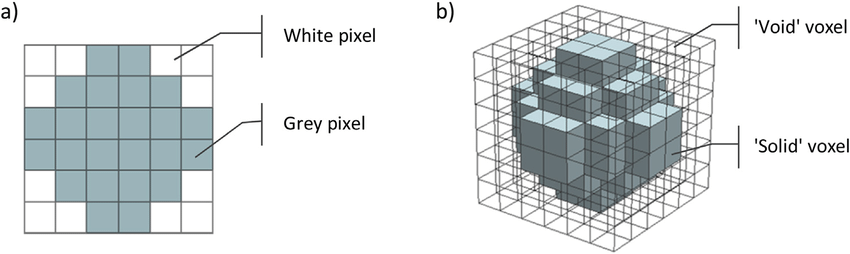
하지만, point cloud나 mesh와 같은 3D geometric data는 규칙적인 format이 없으므로 voxel grid 등으로 데이터를 변형하여 딥러닝 모델의 input으로 주었다. 이러한 방법은 불필요하게 큰 volume을 렌더링해야 하고, data의 특성을 모호하게 한다는 단점이 있다.
PointNet은 이러한 과정 없이 point cloud를 직접적으로 input representation으로 사용하는 딥러닝 네트워크이다.
Introduction
PointNet이 고려해야 할 point cloud의 특성은 다음과 같다.
- Mesh의 불규칙성과 복잡성을 피해야 하며, 간단하고 통합된 구조여야 한다.
- Point set의 특성 반영해야 한다.
- Permutation invariant : 순서가 바뀌어도 network 계산 결과는 같아야 한다. (point set은 unordered set이다.)
- Transformation invariant : 강체의 병진운동(translation), 회전운동(rotation)에도 결과는 같아야 한다.

PointNet은 대표적으로 3D classification, 3D segmetnation task에 사용하며, point cloud 자체를 입력으로 받아 classification task(Fig 2의 1번)인 경우에는 input point cloud의 class label을 예측하고, segmentation task(Fig 2의 2번)에서는 point 각각의 segment 혹은 part label을 예측한다.
PointNet은 다음과 같은 특징을 갖는다.
- Simplicity : 초기 단계에서 각 point는 독립적으로 처리된다.
- Transform invariant : Transform도 point마다 독립적으로 적용되므로, rigid/affine transformation 적용이 쉽다.
- Permutation invariant : Input point들의 순서가 바뀌어도 feature 결과는 바뀌지 않는다.
- 연속적인 어떤 set function이든 근사할 수 있다.
- Summarization : Point cloud를 sparse한 key points(object의 skeleton)로 축약한다.
- Stability(Robustness) : Input이 조금 변하거나, outlier 혹은 missing이 조금 생겨도 좋은 성능을 보인다.
- Efficiency and Powerful : shape classification, part segmentation, scene segmentation 등 다양한 task에 대해 기존 SOTA 모델들보다 훨씬 빠르고, 성능도 좋다.
Method
Properties of Point Sets
Point는 Euclidean space에 놓여있으므로, 다음과 같은 특성을 갖는다.
- Unordered : Point set 내의 point들은 순서가 없다.
- 따라서 \(N\)개의 point를 다루는 network의 경우, \(N!\)가지의 permutation(순서)에 대해 같은 representation을 학습해야 한다.
- Interaction among points : 이웃하는 point 간의 연관성이 '거리'의 개념을 기준으로 정해진다.
- 가까운 point끼리의 local structure와 그 local structure간의 상호작용을 포착해야 한다.
- Transformation invariance : Point set에 translation, rotation 등이 생겨도 point set을 학습한 representation은 똑같아야 한다.
PointNet Architecture
전체적인 PointNet 구조는 아래와 같다.

Input
PointNet의 input은 앞서 말한대로 3D points이다. Implementation 관점에서 봤을 때, point의 위치(x, y, z 좌표값)로 주어진다.
적용할 task에 따라 object classification task인 경우에는 shape에서 샘플링한 point cloud, part semantic segmentation task인 경우 단일 object의 point cloud, object semantic segmentation task인 경우 3D scene의 point cloud가 주어질 것이다.
Output
Output의 경우, classification task의 output은 해당 object의 class 개수(\(k\)) 만큼의 score vector일 것이고, semantic segmentation인 경우 point 개수 \(n\), semantic category 개수 \(m\)개에 대해 \(n \times m\)개의 score를 구하여 모든 point 각각이 어떤 semantic category에 해당하는지를 예측할 것이다.
Pipeline
Classification과 segmentation task의 차이에 따라 뒷단에서 point feature를 어떻게 활용하는지만 바뀐다.

- \(N\)개 point를 입력받는다.
- Input transformation, feature transformation을 적용하여 local point feature를 얻는다.
- MLP와 max pooling을 통해 global point feature를 얻는다.
- Task에 따라 다음 과정으로 나뉜다. (Fig 2 참고)
- Classification task : Global feature를 MLP에 입력하여 k개 class에 대한 score를 구한다.
- Segmentation task : Local feature와 global feature를 연결(concat)하고, MLP를 거쳐 n개 point들의 segmentation score를 구한다.
Key Modules of PointNet
PointNet에서의 핵심은 max pooling layer, local feature와 global feature의 연결, 그리고 joint alignment network 두 개(input transformation, feature transformation)이다. 각각을 자세하게 알아보자.
Max pooling layer
PointNet에서는 max pooling을 통해 point의 정보를 합친다. Max pooling은 symmetric function이므로 permutation invariant와 robustness를 구현할 수 있다.
즉, max pooling을 사용함으로써 input point의 순서가 바뀌어도 뽑히는 feature는 변하지 않고, input이 조금 변해도 robust하다.

사실 permutation invariance를 구현하기 위한 방법은 sorting, sequential model, symmetric function 등 여러가지가 있는데, 그중 가장 성능도 좋고, point cloud라는 input을 다루기에 가장 적합한 것이 max pooling이었다. 그 증명 과정은 논문을 참고하자.

Aggregation of Local and Gobal information
Semantic segmentation task를 수행할 때, PointNet에서 얻은 local feature와 global feature를 연결(concat)하는 과정이 있다. 이는 segmentation 과정에서 두 가지 정보를 모두 활용해야 하기 때문이다.
Max pooling의 결과는 point set 전체적인(global) 정보를 담는 vector이다. Classification task에서는 간단히 SVM이나 MLP classifier를 활용하여 task를 진행할 수 있으나, segmentation은 point 각각이(local) 어떤 segmentic category에 해당하는지 알아야 하므로 local feature와 global feature가 모두 필요하다.

이전 과정에서 local feature의 shape은 \((n,64)\), global feature의 shape은 \((n,1024)\)였다. 이를 point 개수를 보존하며 \((n,1088)\)의 vector로 연결한다.
이후에 이를 MLP에 태워 point별 feature를 다시 뽑아 network가 각 point의 local 정보(geometry)와 global 정보(semantic)를 모두 다루도록 한다.
Joint Alignment Networks (Input Transformation and Feature Transformation)

Joint alignment network란, PointNet에서 feature를 뽑기 전에 모든 input point set을 canonical space로 정렬해주는 network를 말한다. 이는 spatial transformer에서 sampling과 interpolation을 통해 2D image를 정렬한 아이디어를 차용한 것이다.
먼저 input transformation부터 알아보자. T-Net(Transformation Network)을 사용하는데, 이미지에서보다 point cloud에 적용하는 게 훨씬 간단하다.
T-Net은 affine transformation matrix를 예측하는 네트워크이다. 즉, point set이 canonical space에 비해 얼마나 translation, rotation했는지를 예측하는 네트워크이다.
다음으로 feature transformation에서는 또다른 T-Net을 활용한다. Input transformation 이후에 한 번 feature를 뽑는데, 여기에 T-Net을 한 번 더 적용하여 feature transformation matrix를 예측한다. 즉, feature space가 얼마나 transform되었는지를 예측한다.
이때 spatial space(3D)보다 feature space(64D)에서의 transformation matrix의 차원이 훨씬 높으므로 optimization이 어려워지는데, 이를 해결하기 위해 loss에 regularization term을 추가해준다.
\( \mathcal{L}_\text{reg} = \lVert \mathbf{I} - \mathbf{A}\mathbf{A}^\top \rVert_F^2 \)
- \(\mathbf{A}\) : T-Net이 예측한 feature alignment matrix
위 loss를 통해 optimize한다는 것은 feature transformation(alignment) matrix가 orthogonal matrix가 되도록 학습시키는 개념이다. 이를 통해 optimization 과정이 stable해지고, 모델 성능이 더 좋아진다.

Experiments

Fig 10의 결과에서 색상은 depth를 나타내고, critical points란 global shape feature를 결정하는 점, 즉 이 점들이 없어지지만 않는다면 결과가 바뀌지 않는 점들을 말한다.
Upper-bound shape이란, noise가 존재해도 결과가 바뀌지 않는 최대 범위를 말한다.
3D Object Part Segmentation, Semantic Segmentation

Fig 11은 object part segmentation 결과이다. 한 물체가 주어졌을 때, 그 물체의 부분을 나눠주는 것이다.

Fig 12는 semantic segmentation 결과로, 주어진 scene에서 point별로 해당하는 category를 나누는 작업이다.
이외에도 Model retrieval from point cloud (주어진 point(query shape)과 shape feature가 비슷한 shape을 고르는 task), shape correspondence (주어진 두 shape의 critical point set 간의 correspondence 계산) 등 다양한 task에 활용될 수 있다.
다음에는 이를 보완한 PointNet++ 모델을 제안한 논문을 리뷰해볼 것이다.








최근댓글