3D Human Pose and Mesh Vertices Reconstruction 분야에서 METRO(MEsh TRansfOrmer) 방법을 제안한 논문을 리뷰해보려 한다.
2021년 CVPR에 게재된 논문이고, 논문 리뷰 내용은 다음 포스팅을 참조하자.
[논문 리뷰] [2021 CVPR] End-to-End Human Pose and Mesh Reconstruction with Transformers
3D Human Pose and Mesh Vertices Reconstruction 분야에서 METRO(MEsh TRansfOrmer) 방법을 제안한 논문을 리뷰해보려 한다. 2021년 CVPR에 게재된 논문이고, 깃허브를 클론하여 구현해본 첫 논문이다. 구현 과정..
jjuke-brain.tistory.com
clone하여 연습하면서 조금씩 코드를 수정했는데, 그 결과는 다음 Github를 참조하자.
https://github.com/JJukE/Practice_MeshTransformer
GitHub - JJukE/Practice_MeshTransformer: METRO Implementation (clone)
METRO Implementation (clone). Contribute to JJukE/Practice_MeshTransformer development by creating an account on GitHub.
github.com
목차
첫 구현이므로 도커에 컨테이너를 생성하는 과정부터 클론 코딩한 전반적인 과정까지 자세히 기록해두려 한다.
전체 과정은 다음과 같이 요약할 수 있다.
- Docker Container 생성
- CUDA 및 패키지 버전 (가능한) 맞추기
- Git Clone & Dataset Download
- Training & Evaluation
- 환경 Setting - Requirements (패키지) 다운로드
- Training
- Evaluation
- Applying Reconstruction to my picture
논문 저자의 코드는 다음을 참조하자.
https://github.com/microsoft/MeshTransformer
GitHub - microsoft/MeshTransformer: Research code for CVPR 2021 paper "End-to-End Human Pose and Mesh Reconstruction with Transf
Research code for CVPR 2021 paper "End-to-End Human Pose and Mesh Reconstruction with Transformers" - GitHub - microsoft/MeshTransformer: Research code for CVPR 2021 paper "End-to-En...
github.com
Docker Container 생성
도커 파일을 만드는 자세한 과정은 다음 포스팅을 참조하자.
Docker, SSH, Visual Studio Code로 작업 환경 구축하기
도커의 컨테이너 환경을 로컬 환경처럼 사용할 수 있는 작업 환경을 구축하는 방법을 기록하고자 한다. 목차 1. CUDA 버전 찾기 CUDA(Computed Unified Device Architecture)란, 그래픽 용도로만 사용하던 GPU를
jjuke-brain.tistory.com
GPU 서버를 사용하여 모델을 학습할 것인데, 이를 위해서는 GPU에 맞는 CUDA 버전을 갖고 있는 도커 이미지 파일을 구해야 한다.
CUDA는 GPU, NVIDIA driver, PyTorch 버전 등에 맞추어서 버전을 찾아야 한다.
깃허브의 install.md 파일을 보니 구현을 위한 라이브러리 버전은 다음과 같았다.
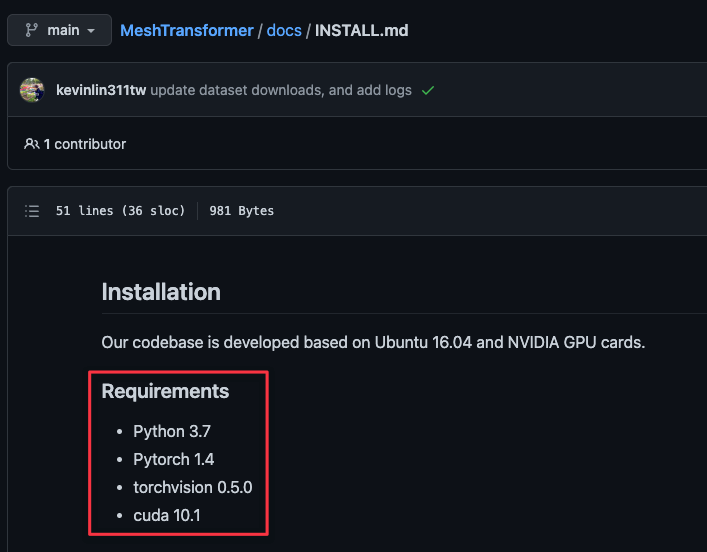
내가 사용하는 GPU에서 CUDA 10.1 버전을 사용할 수 있는지 알아보자.
서버의 GPU는 RTX 3090이며, nvidia-smi 명령어 실행 결과는 다음과 같다.
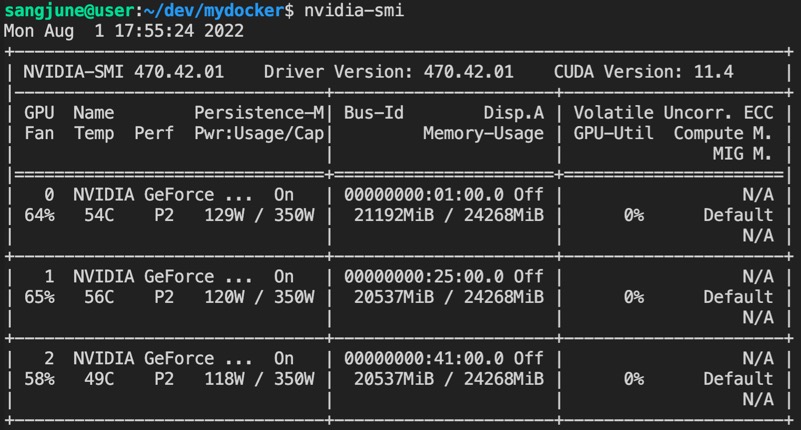
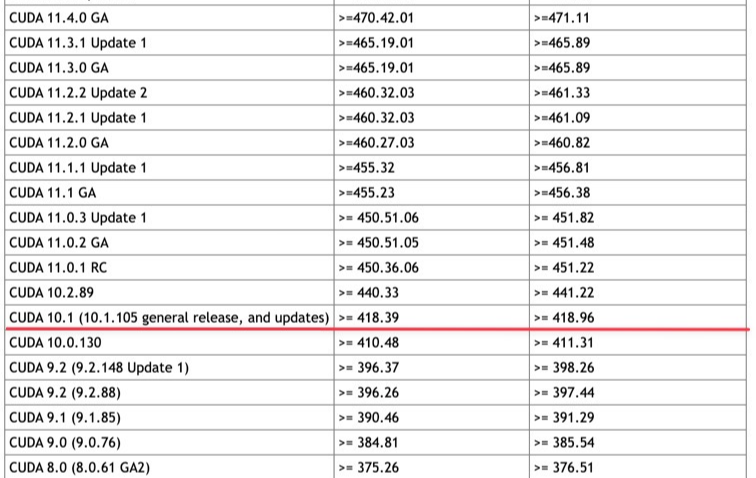
드라이버 버전 기준으로는 470.42.01이므로 CUDA 10.1을 사용할 수 있다.
(드라이버 버전에 따른 호환 가능한 CUDA 버전 확인 링크)
하지만, Capability를 살펴보면 RTX 3090은 8.6이므로 CUDA 10.1버전과 맞지 않다.

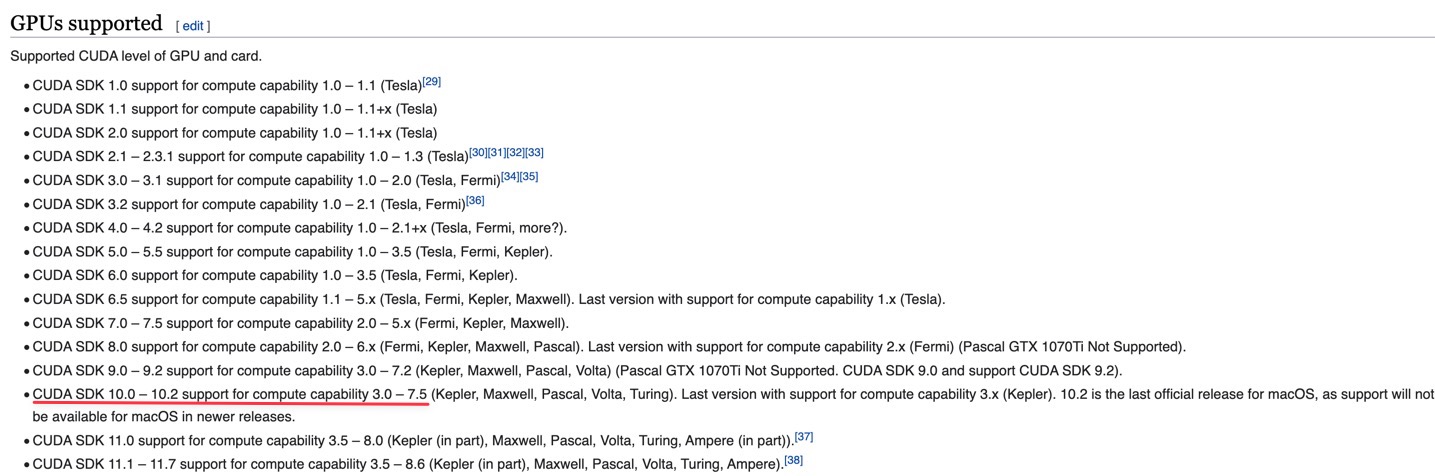
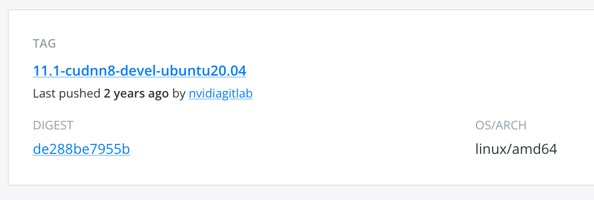
따라서 CUDA 11.1 버전을 사용하기로 하였고,
이에 맞는 도커 이미지 파일을 다음 링크에서 찾을 수 있다.
https://hub.docker.com/r/nvidia/cuda/tags
Docker Hub
hub.docker.com
추가로, 컨테이너 생성 이후에 PyTorch를 사용하게 될텐데, CUDA 버전에 사용 가능한 PyTorch 버전은 다음 링크에서 확인할 수 있다.
https://pytorch.org/get-started/previous-versions/
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
pytorch.org
도커 파일을 만들고, 이미지를 빌드한 후 다음 명령어로 컨테이너를 생성해주었다.
docker run --gpus all -id \
--name JJuk_E \
-v /data/sangjune/dev:/root/dev \
-v /etc/localtime:/etc/localtime \
-e TZ=Asia/Seoul \
--ipc host \
--restart unless-stopped \
-p 38201:22 \
-p 48201:8888 \
sangjune/cuda-miniconda-ssh:11.1-ver0
Git Clone & Dataset Download
컨테이너 내부에 'git clone --recursive'로 MeshTransformer 깃허브의 파일들을 clone했다.
git clone recursive는 submodule까지 모두 clone하는 것으로, transformer와 mano 등의 submodule을 포함하여 클론한다.
git clone --recursive [url]
# git clone과 submodule update를 따로 진행하는 것과 같은 효과
git clone [url]
git submodule update --init --recursive
그리고 데이터를 받아 오려는데, 처음에 'wget' 명령어로 200GB 가량의 여러 dataset을 받아오려고 하니 속도가 매우 느렸다. (100 KB/sec 정도의 속도였는데, 이는 외국의 멀리 떨어진 서버로부터 wget을 통해 다운로드 시 발생하는 문제점이라고 한다.)
따라서 (github에 적힌 대로) AzCopy를 사용하여 다운받았다.
내 환경에서는 데이터를 담아두는 스토리지 서버는 따로 있어서, 컨테이너 내부에 AzCopy를 다운받은 후 아래 명령어를 통해 AzCopy로 해당 링크의 파일을 다운받고, 컨테이너 생성 시에 스토리지 서버의 데이터 디렉토리와 마운트했던 디렉토리로 데이터를 옮겨주었다.
[azcopy 파일이 있는 경로] copy '[다운받을 url]' [다운받을 경로]
# for example
path/to/azcopy copy 'https://data.net/metro/datasets/file.tar' /path/to/download/file.tar
다운받은 파일에는 3DPW, Human3.6M, FreiHand 등의 dataset이 있었다.
Training & Evaluation
본격적으로 학습을 돌리기에 앞서, Requirements에 맞는 라이브러리를 다운받을 필요가 있다.
깃허브에 포함된 'INSTALL.md'에서 필요한 라이브러리 목록을 찾아볼 수 있다.
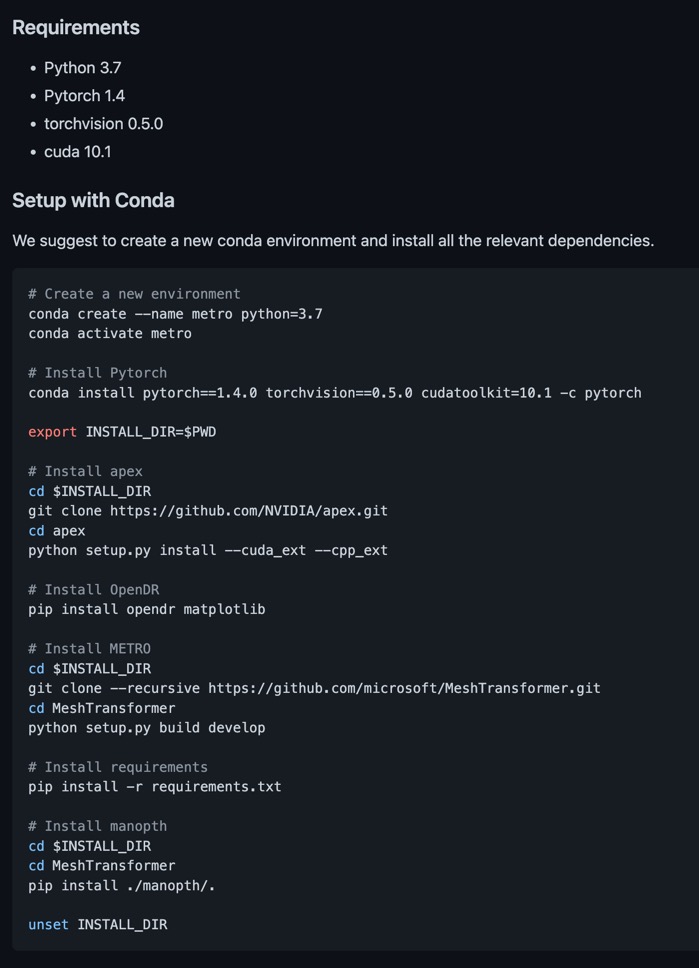
먼저 컨테이너에 파이썬 3.7을 다운받은 후, 위 사진에서의 'Setup with Conda'의 순서대로 작성했다. 단, 내가 설치한 CUDA 버전에서 가능한 가까운 버전으로 PyTorch는 1.8.0, torchvision은 0.9.0, cudatoolkit은 11.1 버전으로 다운받았고, 다른 명령어는 그대로 입력했다.
Training
논문 내용에 소개했듯이, METRO 모델은 human mesh와 hand 모두에 대해 3D reconstruction을 잘 수행한다고 했다.
3D hand reconstruction, human mesh reconstruction 중에 human mesh reconstruction task를 수행하는 모델을 학습시켰다.
깃허브에는 위와 같이 터미널에서 여러 변수를 설정하고 파이썬 파일을 실행하도록 나와있다.
이때 '-m' 옵션은 실행할 파이썬 스크립트(모듈)를 찾을 때, 모듈이 설치된 경로(sys.path)에서 찾고 그 내용을 '__main__'모듈로서 실행한다. 파일을 실행할 때마다 path를 모두 입력해주지 않아도 되기 때문에 모듈이 배포되었을 때 유용하게 사용할 수 있다. 또한 인자가 모듈 이름이므로, 파일 확장자(.py)를 입력하지 않아야 한다.
명령어가 길기 때문에 vim을 활용하여 쉘 실행 파일(.sh)을 하나 만들었다.
vim metro_human_train.sh
vim에서 위와 같이 입력해준 후(단, data의 path가 다르다면 본인에 맞게 바꿔줘야 함), 아래 명령어로 터미널에서 쉘 파일을 실행해줄 수 있다.
sh metro_human_train.sh
Trouble Shooting
그런데, 실행 시 'OMP_NUM_THREADS' 환경변수 오류가 발생했다.
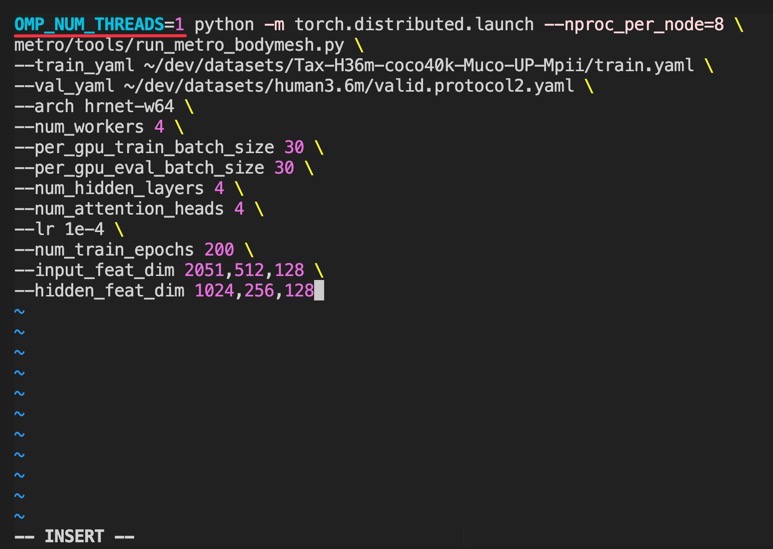
추가적인 환경 변수 설정을 하여 간단히 해결할 수 있었다. 쉘 파일을 다음과 같이 바꾸어 실행해주었다.
[Ref] CUDA_VISIBLE_DEVICES 환경변수
Multi-GPU 시스템을 사용중이고, 서버를 여러 명이 사용중이라면 (nvidia-smi 명령어를 실행해보면 GPU가 총 몇개인지 알 수 있다.) 혹시 모를 충돌을 방지하기 위해 원하는 GPU만 사용하는 방법을 알아둘 필요가 있다.
별도의 설정을 하지 않으면 cuda는 GPU 0번을 사용하려 한다. (또는 코드에 따라 default로 사용 가능한 GPU 모두를 사용할 수도 있다.)
이때, Terminal에서 python code를 실행하는 경우, 다음과 같이 GPU 번호를 'CUDA_VISIBLE_DEVICES'라는 환경변수로 할당해줄 수 있다. (참고로, GPU index는 0번부터 시작된다.)
cuda는 cuda가 볼 수 있는 (visible한) GPU를 사용하는데, 인위적으로 visible device를 변경해주는 것이다.
크게 terminal에서 .py 파일을 실행하는 경우, jupyter notebook 등에서 .ipynb 파일 내에서 돌리는 경우로 나누어 설정 방법을 알아보자.
먼저, Terminal에서 'train.py' 파일을 돌리는 경우를 알아보자.
CUDA_VISIBLE_DEVICES=3 python train.py터미널에 이와 같이 명령할 경우, GPU #3으로 train.py 파일을 실행한다.
만약 여러 GPU를 할당하여 병렬로 사용하고 싶다면 다음과 같이 comma를 이용하여 원하는 GPU 번호를 할당하면 된다.
CUDA_VISIBLE_DEVICES=2,3 python train.py
다음으로, Jupyter notebook 등을 통해 .ipynb 파일 내에서 실행하는 경우는 다음과 같이 환경변수를 설정한다.
os.environ["CUDA_VISIBLE_DEVICES"]="3" # Set the GPU #3 to use
마찬가지로, 여러 GPU를 할당하려면 다음과 같이 comma를 사용한다.
os.environ["CUDA_VISIBLE_DEVICES"]="2,3" # Set the GPUS #2 and #3 to use
설정한 이후에는 다음 코드로 device에 cuda(GPU)를 설정하여 GPU 할당 여부를 확인해볼 수 있다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('Device:', device)
print('Current cuda device:', torch.cuda.current_device())
print('Count of using GPUs:', torch.cuda.device_count())- torch.cuda.is_available() : cuda가 사용 가능하면 true를 반환한다.
- torch.cuda.current_device() : 현재 cuda가 사용하는 GPU를 출력한다.
- torch.cuda.device_count() : 현재 cuda가 사용하는 GPU 개수를 출력한다.
이때, CUDA_VISIBLE_DEVICES 변수에 할당된 GPU(예를 들어, 예시에서 "#3")는 cuda에서 #0으로 할당된다.
[Ref] Distributed Training in PyTorch
모델이 워낙 무거워서 GPU(3090) 하나로는 out of memory가 떠서, 효율적인 학습을 위해 Data Parallel Training을 해야 했다.
그런데 CUDA 버전의 차이 때문인지, 계속 'NODE_RANK'에 대해 KeyError가 발생해서 해당 문제의 해결을 위해 간단히 내용을 정리해본다.
Data parallel training은 다음과 같은 경우로 나뉜다.
- Single device training : 하나의 GPU로 data와 model이 (적절한 속도로) 학습 가능한 경우, data parellel training을 굳이 사용하지 않아도 된다.
- Single-machine multi-GPU DataParellel : 여러 GPU로 하나의 machine(컴퓨터)에서 학습을 진행하는 경우로, 최소한의 코드 변화로 학습 속도를 높이고 싶은 경우 사용한다.
- Single-machine multi-GPU DistributedDataParallel : 코드를 좀 더 수정하여 더 빠르게 학습을 진행하고 싶은 경우 사용한다.
- Multi-machine DistributedDataParallel and the launching script : 여러 machine을 사용하여 학습을 진행할 경우 사용한다.
- torch.distributed.elastic : 학습 동안 유동적으로 resource가 추가 혹은 제거되거나 out-of-memory 등의 에러가 발생할 수 있는 경우에 'elastic'이라는 라이브러리를 사용한다.
DataParallel은 single-process, multi-thread이며 single machine에서만 사용 가능하지만, DistributedDataParallel은 multi-process이며 여러 machine에서도 사용 가능하다.
이때 machine은 'node'라는 개념으로 작동한다.
더 자세한 내용은 추후에 따로 공부하여 정리하도록 하고, distributed train을 위한 코드를 보며 변수의 의미를 파악해보자.
공식 문서의 설명은 다음과 같다.

추가로, out-of-memory 문제때문에 batch size를 20으로 줄였다.
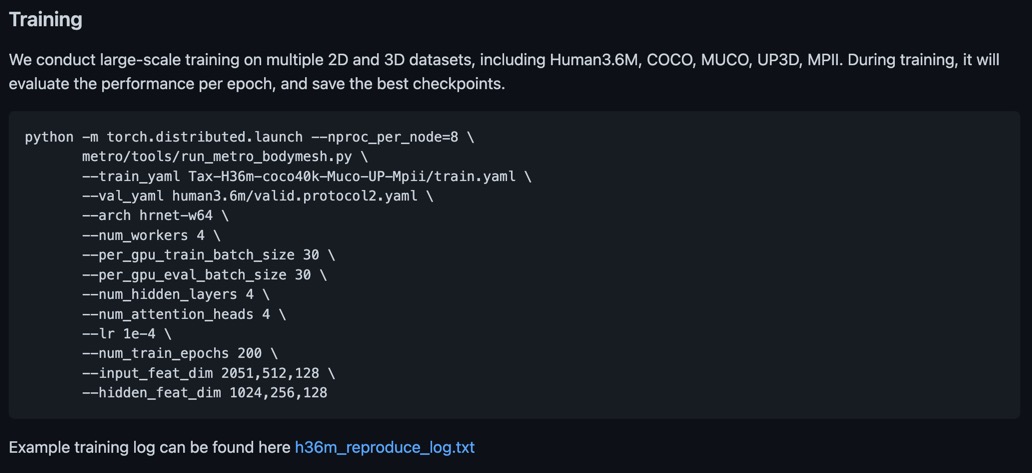
train을 위한 최종 shell 파일은 다음과 같다. (single machine을 사용한다면 굳이 nnodes와 node_rank를 쓸 필요 없지만, 표기해주어도 상관없다.)
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5 OMP_NUM_THREADS=1 \
python -m torch.distributed.launch --nproc_per_node=6 \
--nnodes=1 --node_rank=0 \
metro/tools/run_metro_bodymesh.py \
--train_yaml ~/dev/datasets/Tax-H36m-coco40k-Muco-UP-Mpii/train.yaml \
--val_yaml ~/dev/datasets/human3.6m/valid.protocol2.yaml \
--arch hrnet-w64 \
--num_workers 4 \
--per_gpu_train_batch_size 20 \
--per_gpu_eval_batch_size 20 \
--num_hidden_layers 4 \
--num_attention_heads 4 \
--lr 1e-4 \
--num_train_epochs 200 \
--input_feat_dim 2051,512,128 \
--hidden_feat_dim 1024,256,128
'torch.distributed.launch'에 대한 변수의 의미는 다음과 같다.
- --nproc_per_node : number of processes per node를 뜻한다. 쉽게 말해 node 당 사용할 GPU의 개수를 정해줄 수 있다. 내 경우 서버에 3090 6대가 있어 6으로 설정했다.
- --nnodes : node의 개수이다. 노드는 하나로 사용할 것이므로, 따로 할당해주지 않았다. (single-node multi-process이므로)
- --node_rank : node를 여러 개 사용할 경우, 각 노드에 번호를 붙여준다. (즉, node를 두 개사용한다면, 위와 같은 코드를 두 번 작성해야 할 것이다.)

드디어 학습을 시작했다.
그런데 내가 새로운 모델을 개발해볼 것도 아니고 굳이 8일이라는 긴 시간을 들여서 학습할 필요는 없는것 같아서, epoch을 30으로 줄이고, 학습 과정을 visualization 해보았다.
Visualize the Training Process
학습 과정을 시각화하기 위해 wandb를 사용했다.
먼저, Wandb 사이트에 회원가입을 해야한다. 가입 직후 창을
https://anaconda.org/conda-forge/wandb
Wandb :: Anaconda.org
anaconda.org
그후, 아래 명령어로 wandb 패키지를 설치한다.
conda install -c conda-forge wandb
그리고, 아나콘다 가상환경과 wandb를 연동해주어야 한다.
wandb login
이 명령어를 실행하면 API key를 브라우저에서 찾으라면서 링크를 줄 것이다.
해당 링크에서 API key를 복사하여 붙여넣어주면 연동이 완료된다.
연동 후에는 wandb 사이트 상에서 새로운 프로젝트를 생성한 후, training 코드 중간에 몇 가지 코드를 추가해줘야 한다.
추가할 주요 코드는 다음 세 가지이다.
- wandb.init() : 해당하는 wandb 계정, 프로젝트와 연결 후 initialize해준다.
- wandb.watch() : gradient, topology 등과 관련된 정보를 visualize해준다.
- argument 중 주요 3가지만 설명하자면, 딥러닝 모델, loss function, log를 주는데, log에 'all'을 주면 gradient, parameter 등의 값을 visualize할 수 있다.
- wandb.log() : 내가 원하는 값을 visualize해준다.
- 아래 예시에서와 같이 'epoch', 'val_metric'이라는 값을 visualize했다. (복잡한 모델을 구현한 코드라 loss값이 아닌 실험을 위한 별도의 metric을 출력했다.)
예시를 살펴보자. 대략적인 wandb.init, wandb.watch, wandb.log의 위치를 알아볼 수 있을 것이다.
import torch
...
import wandb #
def model_train(model, ...):
wandb.init(project='[생성한 프로젝트 이름]', entity='[wandb 계정 이름]')
...
# loss function
criterion = torch.nn...
wandb.watch(model, criterion, log='all')
...
for iter in enumerate(train_dataloader):
model.train()
iter += 1
epoch = iter // iters_per_epoch
...
loss = ...
optimizer.zero_grad()
loss.backward()
optimizer.step()
if iter % iters_per_epoch == 0:
val_metric = ...
wandb.log({'Epoch': epoch, 'metric':val_metric })
...
...
학습을 진행하면 다음과 같이 학습 도중에도 visualization을 해볼 수 있다.
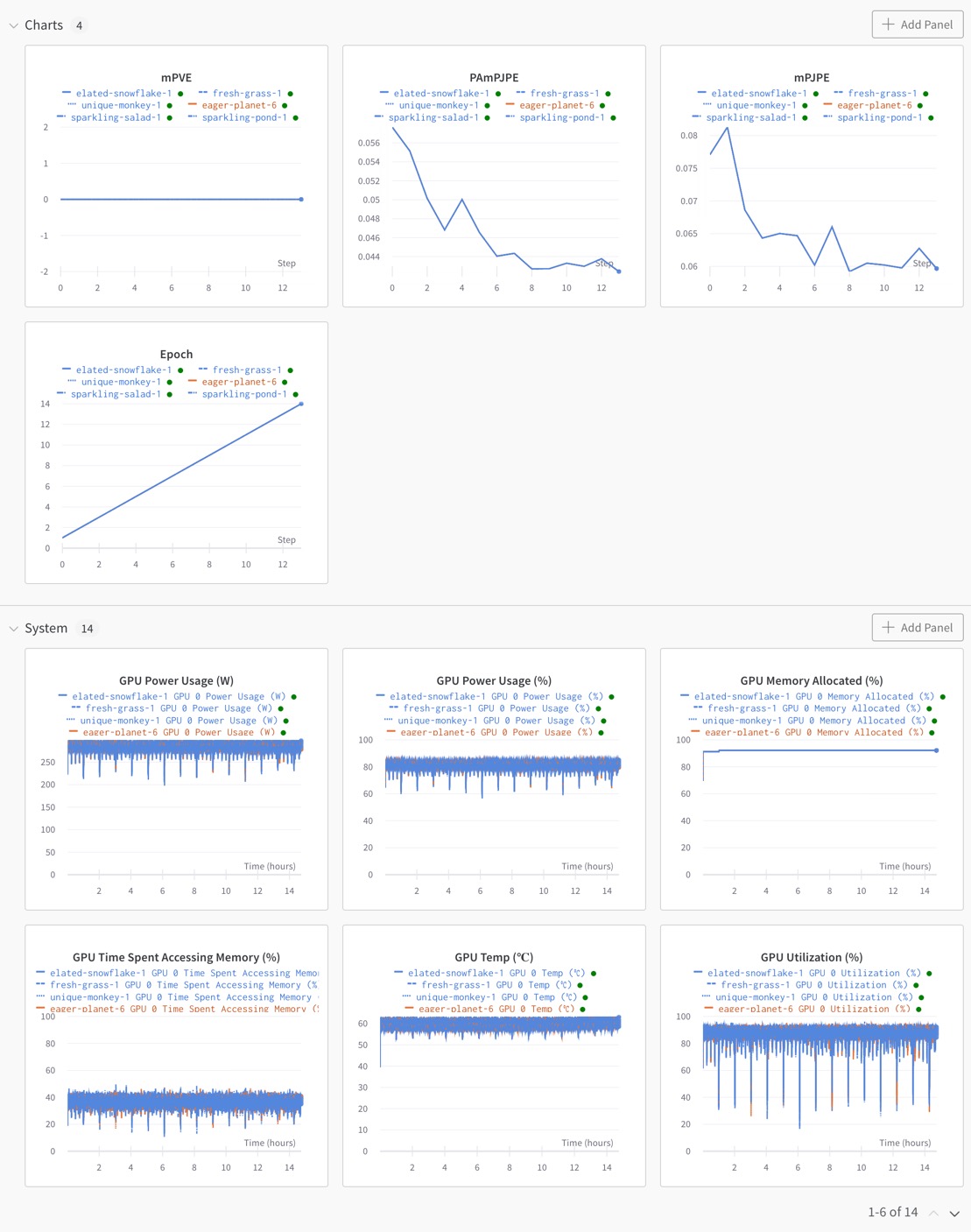
최종 학습 결과는 다음과 같다.
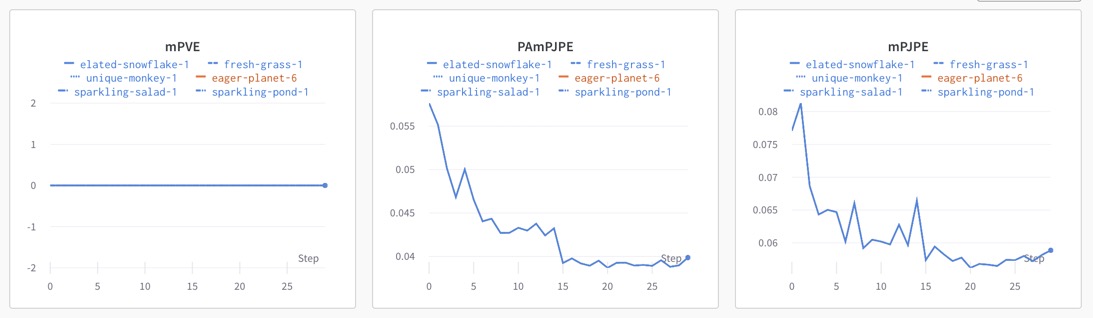
마지막 epoch에서의 validation 결과는 다음과 같다.

training은 Human3.6M, COCO, MUCO, UP3D, MPII Dataset을 모두 사용하여 진행했고, validation은 Human3.6M dataset에 대해 진행했다.
Evaluation
Evaluation 과정도 Training과 마찬가지로 쉘 파일을 만들었다.
vim metro_human_eval.sh
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5 OMP_NUM_THREADS=1 \
python -m torch.distributed.launch --nproc_per_node=6 \
--nnodes=1 --node_rank=0 \
metro/tools/run_metro_bodymesh.py \
--val_yaml ~/dev/datasets/human3.6m/valid.protocol2.yaml \
--arch hrnet-w64 \
--num_workers 4 \
--per_gpu_eval_batch_size 20 \
--num_hidden_layers 4 \
--num_attention_heads 4 \
--input_feat_dim 2051,512,128 \
--hidden_feat_dim 1024,256,128 \
--run_eval_only \
--resume_checkpoint ./output/checkpoint-30-119010/model.bin
training 시의 쉘 파일 내용에서 train 관련 인자가 빠졌고, checkpoint를 불러오는 인자가 추가되었다.
Trouble Shooting
그런데, 'File not found: archive/data.pkl'이라는 오류가 발생했다.
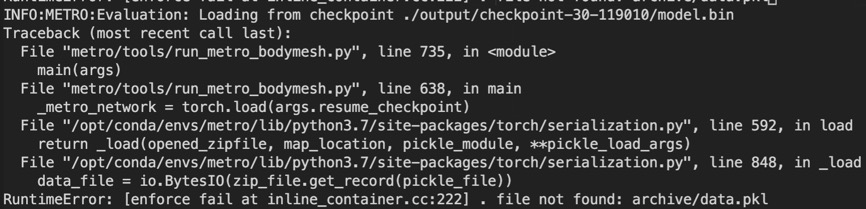
Log를 살펴보니, checkpoint가 제대로 저장되지 않고 있었다.
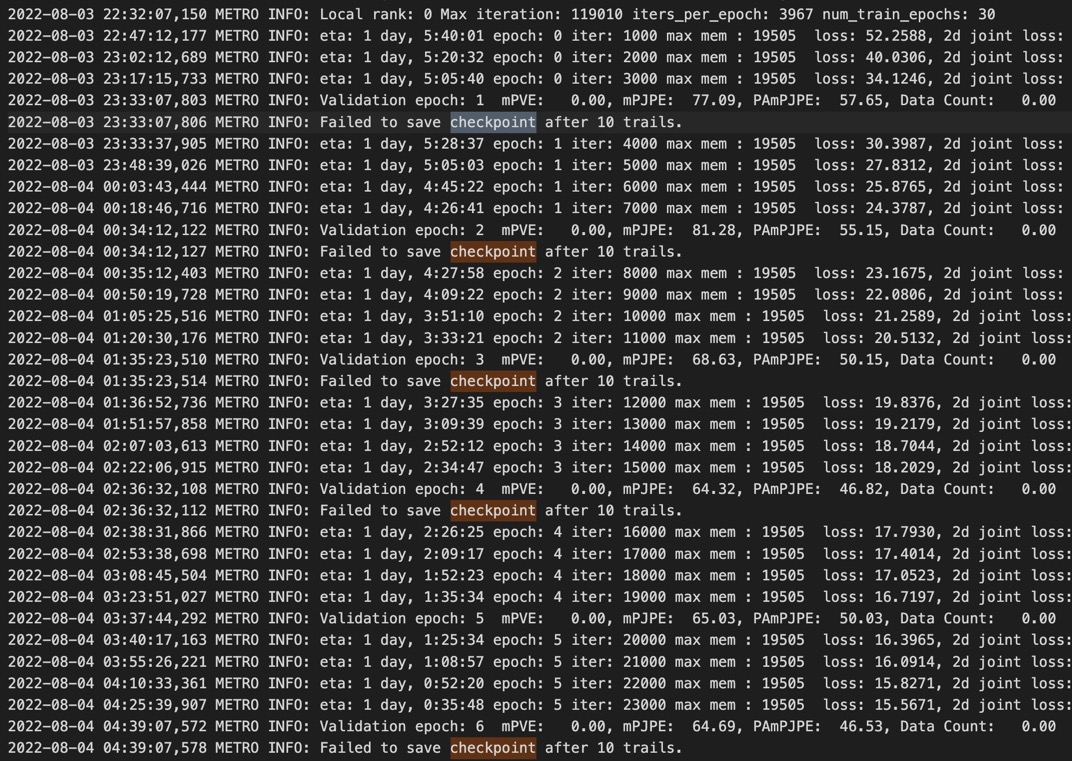
checkpoint를 저장하는 코드를 보니, model.bin 파일만 생성된 것을 보아 directory를 만드는 과정까지는 성공적으로 진행됐는데, state_dict를 저장하는 과정에서 문제가 있었던 것 같다.
디버깅을 하고 학습을 다시하는 수밖에 없다는데, 시간이 너무 오래 걸리는 관계로 evaluation은 저자가 제공하는 train 결과 모델을 돌려보기로 했다.
따라서 다음과 같이 제공된 checkpoint 경로로 다시 evaluation을 돌렸고, 그 결과는 아래와 같다.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5 OMP_NUM_THREADS=1 \
python -m torch.distributed.launch --nproc_per_node=6 \
--nnodes=1 --node_rank=0 \
metro/tools/run_metro_bodymesh.py \
--val_yaml ~/dev/datasets/human3.6m/valid.protocol2.yaml \
--arch hrnet-w64 \
--num_workers 4 \
--per_gpu_eval_batch_size 20 \
--num_hidden_layers 4 \
--num_attention_heads 4 \
--input_feat_dim 2051,512,128 \
--hidden_feat_dim 1024,256,128 \
--run_eval_only \
--resume_checkpoint ./models/metro_release/metro_h36m_state_dict.bin

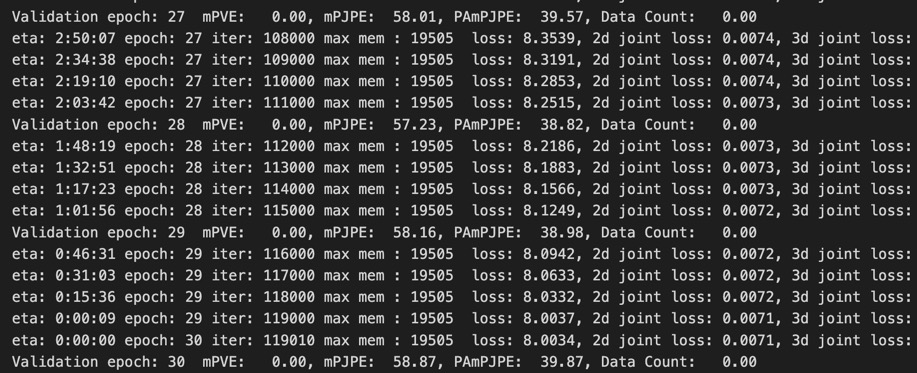
training 결과는 30 epochs만 돌렸으므로 조금 더 metric 값들이 큰 값을 보임을 알 수 있다. (논문 상에서 실험할 때에는 epoch이 200이었다.)
마지막으로 저자가 제공하는 학습된 모델로 3dpw 데이터와 내 사진에 대해 reconstruction을 해보았다.
이상적인 결과는 다음과 같다.

먼저 3dpw 데이터에 대한 결과이다.



다음으로, 내 사진에 대해 body reconstruction 해본 결과는 다음과 같다. (224 × 224 사이즈로 resize 후에 적용했다.)




원래 세 번째 사진에는 모두 mesh reconstruction 결과가 나와야 하는데, 여러 번 반복해서 돌려보아도 결과가 나오지 않았다. 저자가 제공한 모델 파일의 뭔가가 바뀐 듯 하다.
처음부터 제대로 학습을 해본다면 mesh reconstruction 결과까지 뽑아볼 수 있겠으나, 그러기엔 시간이 너무 많이 걸려서 self-attention 결과를 보는 것으로 만족하기로 했다.
두 번째 사진과 같이 몸의 일부가 잘린 사진은 self-attention도 제대로 되지 않았다. 학습 시에 잘린 사진을 사용하지 않았을 것이므로 당연한 결과이다.
구현 후 깨달은 점
Github에 공개된 논문 코드를 처음으로 구현해보면서 다음과 같은 교훈(?)을 얻었다.
- 패키지 버전, 특히 CUDA 버전은 최대한 맞추자.
- 제일 시간을 많이 잡아먹었다. 버전이 바뀌면서 문법이 바뀌는 경우가 있으므로 버전이 달라질수록 수정해야 할 코드가 많아진다.
- Capability 문제 등에 의해 어쩔 수 없이 버전을 맞추지 못하더라도, 최대한 가까운 버전으로 진행하자. 처음엔 CUDA 11.3 버전과 PyTorch 1.11 버전으로 학습했다가 distributed learning 방식을 도저히 맞춰주지 못해서 컨테이너를 다시 생성하는 시행착오를 겪었다.
- 시각화를 위해서라도 핵심 코드 정도는 이해해보자.
- Tensorboard를 사용하려 했으나, 학습이 진행되는 코드를 잘 이해하지 못해 결국은 간단한 코드 몇 줄로 해결이 가능한 wandb를 사용했다. 다음부터는 코드를 좀 더 이해해보고, tensorboard를 사용해보자.
- 애초에 학습 부분의 코드를 제대로 이해했다면 Checkpoint가 제대로 저장되지 않을 일도 없었을 것이다.
- 코드를 모듈화하는 방식을 익혀보자.
- 처음엔 디렉토리 구성이 너무 복잡해서 막막했지만, 결국 중요한 파일 몇 개로 대부분의 알고리즘이 동작했다. 다양한 논문을 구현 해보면서 모듈화 방식을 익혀보고, 추후에 내가 모델을 구현할 때에도 적용해보자.








최근댓글