3D Human Pose and Mesh Vertices Reconstruction 분야에서 METRO(MEsh TRansfOrmer) 방법을 제안한 논문을 리뷰해보려 한다.
2021년 CVPR에 게재된 논문이고, 깃허브를 클론하여 구현해본 첫 논문이다. 구현 과정은 다음 포스팅을 참조하자.
[논문 구현] [2021 CVPR] End-to-End Human Pose and Mesh Reconstruction with Transformers
3D Human Pose and Mesh Vertices Reconstruction 분야에서 METRO(MEsh TRansfOrmer) 방법을 제안한 논문을 리뷰해보려 한다. 2021년 CVPR에 게재된 논문이고, 논문 리뷰 내용은 다음 포스팅을 참조하자. https://..
jjuke-brain.tistory.com
목차
Core Questions
논문의 핵심 내용과 내가 얻은 Insight는 다음과 같다.
- What did authors try to accomplish?
- METRO (MEsh TRansfOrmer) : 하나의 이미지를 입력으로 받아 3D Human Pose 및 Mesh Vertices를 Reconstruction하는 아키텍쳐 개발하였다.
- What were the key elements of the approach?
- 아키텍쳐 핵심 구성 요소는 Transformer Encoder와 Masked Vertex Modeling이다.
- METRO는 parametric mesh model에 의존하지 않기 때문에 다재다능하다. (Human pose 뿐만 아니라 3D Hand Reconstruction의 task에서도 최고 성능을 보였다.)
- What can I use myself?
- 3D Human 도메인의 배경 지식을 쌓았고, 논문 구현(clone)을 처음으로 해보았다.
- What other references do I want to follow?
- Transformer 개념과 self-attention 개념을 알아둘 필요가 있을 것이다. 이에 따라 다음 논문을 읽어볼 계획이다.
- Transformer 논문 → Attention Is All You Need
- Self-attention 논문 → A Better Building Block for Sentiment Analysis Neural Network Classifiers
- Non-local Neural Networks 논문
- Position Encoding 개념
- Transformer 개념과 self-attention 개념을 알아둘 필요가 있을 것이다. 이에 따라 다음 논문을 읽어볼 계획이다.
- What are the contributions of this paper?
- 3DPW, Human3.6M 데이터셋에 대한 최고 성능을 보였다.
- Ablation Study를 통해 Masked Vertex Modeling의 효과를 확인했고, Non-local Interaction을 분석했다.
METRO Architecture

이미지의 사이즈는 224 × 224로 맞추어 입력으로 받으며, body joints \(J\)와 mesh vertices \(V\)를 예측한다.
크게 CNN과 Multi-Layer Transformer Encoder 모듈로 구성되며, CNN을 통해 이미지의 feature vector를 추출하며, Multi-Layer Transformer Encoder가 feature vector를 입력받아 body joint와 mesh vertex의 3D coordinate를 병렬로 출력한다.
METRO의 동작 과정은 다음과 같이 요약할 수 있다.
- CNN으로 image feature vector 추출한다.
- Image feature vector에 template human mesh를 추가하여 Position Encoding 방법을 적용한다.
- Transformer Encoder로 Self-attention 적용하고 3D coordinate를 regress
그림과 같은 generic한 설계 덕분에, METRO는 Human Pose and Mesh Reconstruction task에서 end-to-end로 학습이 가능하다.
좀 더 자세히 살펴보자.
Convolutional Neural Network (CNN)
앞서 언급했듯이, CNN은 feature extraction을 위해 사용되며, 해당 CNN은 ImageNet classification task로 pre-trained되었다.
또한 마지막 hidden layer에서 dimension이 2048인 feature vector \(X\)를 추출하게 된다.
Multi-Layer Transformer Encoder
Transforemr Encoder 구조
METRO에서의 Transformer는 3D coordinate를 출력해야하기 때문에, 모든 layer에서 hidden embedding의 차원이 일정하게 유지되는 기존의 transformer를 사용할 수 없다.
따라서 여러 block을 사용하여 차원을 축소시킬 수 있다는 아이디어를 적용하여 'Multi-Layer Encoder with Progressive Dimensionality Reduction'를 사용하였다.
다음 그림을 통해 구조를 살펴보자.
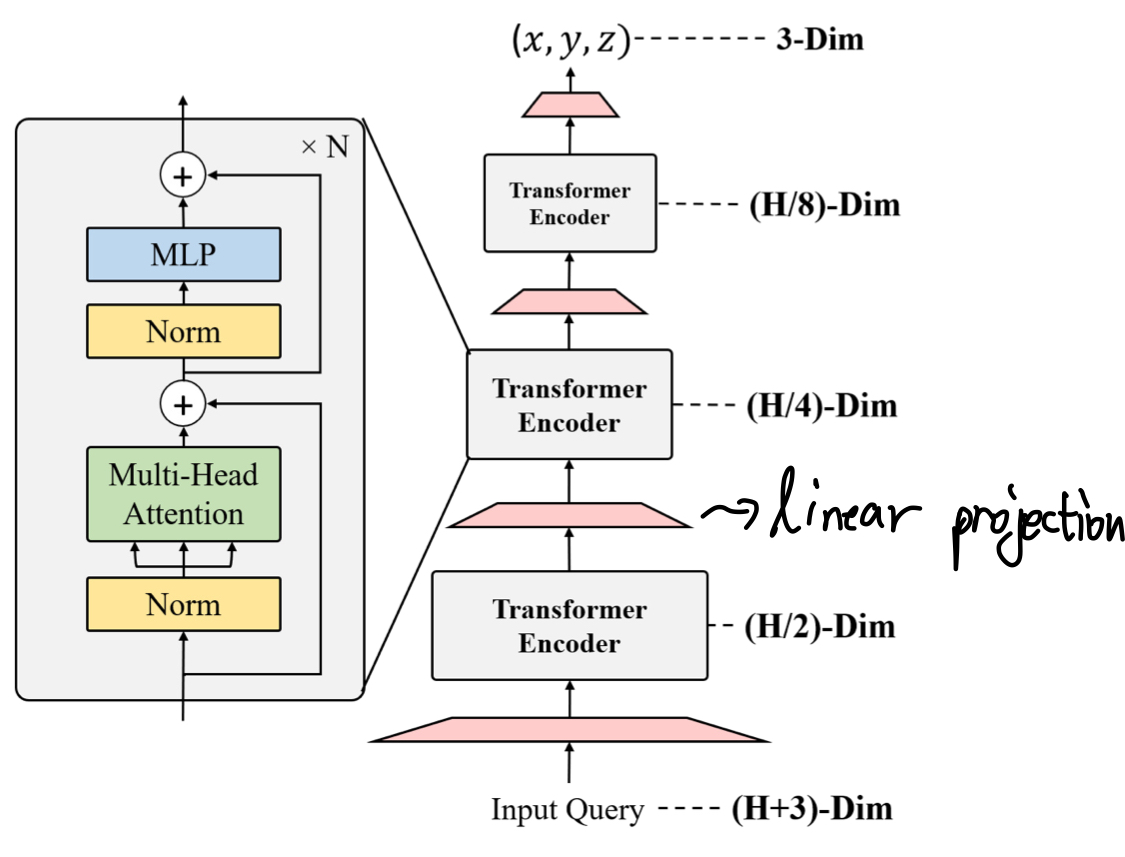
각 encoder layer 이후에는 'Linear Projection'을 적용하여 hidden embedding의 차원을 축소시켰다.
그리고 여러 개의 encoder layer를 사용함으로써 모델은 마치 self-attention과 차원 축소 과정을 번갈아가며 하는 것처럼 동작한다.
앞서 언급했듯 출력 결과물은 joint와 mesh vertex들의 3D Coordinate이다.
Positional Encoding
전체 METRO framework의 구조로 다시 돌아가보면, transformer encoder는 body joint와 mesh vertex 쿼리이다.
각 쿼리의 positional information을 보존하기 위해 template human mesh를 사용했다. (positional encoding 방법)
이미지의 feature vector \(X \in \mathbb{R}^{2048 \times 1}\)를 모든 body joint \(i\)에 대한 3D coordinates \( (x_i, y_i, z_i)\)와 연결한다.
이에 따라 joint queries \(Q_J = \left\{ q_1^J , q_2^J, \cdots, q_n^J \right\} \)를 형성한다. (이때, \(q_i^J \in \mathbb{R}^{2051 \times 1} \))
마찬가지로, 모든 mesh vertex \(j\)에 대해 vertex queries \(Q_V = \left\{ q_1^V, q_2^V, \cdots, q_m^V \right\} \)를 형성한다. 역시 \(q_j^V \in \mathbb{R}^{2051 \times 1} \)를 만족한다.
Masked Vertex Modeling (MVM)
본래 transformer는 언어 특성을 학습하기 위해 training 과정 전반적으로 MLM (Masked Language Modeling)을 사용했다.
하지만 MLM은 입력을 recover하는 것이 목적이기때문에, regression이 목적인 METRO framework와는 잘 맞지 않는다.
따라서 논문에서는 transformer encoder에서 양방향 attention을 위해 'Masked Vertex Modeling (MVM)'를 설계하였다.
이는 input queries를 랜덤으로 masking하는 방법이다. 마스킹된 입력을 recover하는 MLM과 달리, transformer가 모든 joints와 vertices를 regress하도록 했다.
또한 Missing query를 예측(즉, 가려진 부분을 simulation)하기 위해서는 모델이 관련된 queries를 사용해야 한다.
MVM은 transformer가 관련된 vertices 및 joints를 사용하여 regress하도록 하는데, 이때 그들 간의 거리나 mesh topology와는 관련이 없다.
따라서 이 방법은 human body modeling 시에 joints와 vertices 간의 먼 범위의 상호작용도 가능하게 한다.
Experiment
먼저, 3DPW와 Human3.6M 데이터셋을 사용한 실험으로부터 Human Mesh Reconstruction 분야에서 이전 state-of-the-art methods보다 좋은 성능을 가졌음을 보인다.
그리고, Ablation study를 통해 non-local interactions와 model design에 대한 insight를 제공한다.
마지막으로, hand reconstruction task에도 일반화할 수 있음을 보인다.
Evaluation Metrics
먼저, 평가 기준은 아래와 같다.
- MPJPE (Mean-Per-Joint-Position-Error) : human 3D pose를 평가하기 위한 metric이다.
- Ground Truth(정답) joints와 예측 joints 간의 유클리드 거리를 측정한다.
- PA-MPJPE or Reconstruction Error (Procrustes Analysis MPJPE) : 위와 같은 task를 평가하기 위한 metric이다.
- PA를 사용하여 3D alignment를 진행한 후에 MPJPE 값을 측정하는 방법이다. MPJPE에 비해 scale과 rigid pose(translation, rotation 등)의 영향을 받지 않아 일반적으로 사용된다.
- MPVE (Mean-Per-Vertex-Error)
- Ground Truth vertices와 예측 vertices 간의 유클리드 거리를 측정한다.
Performance on 3DPW and Human3.6M datasets
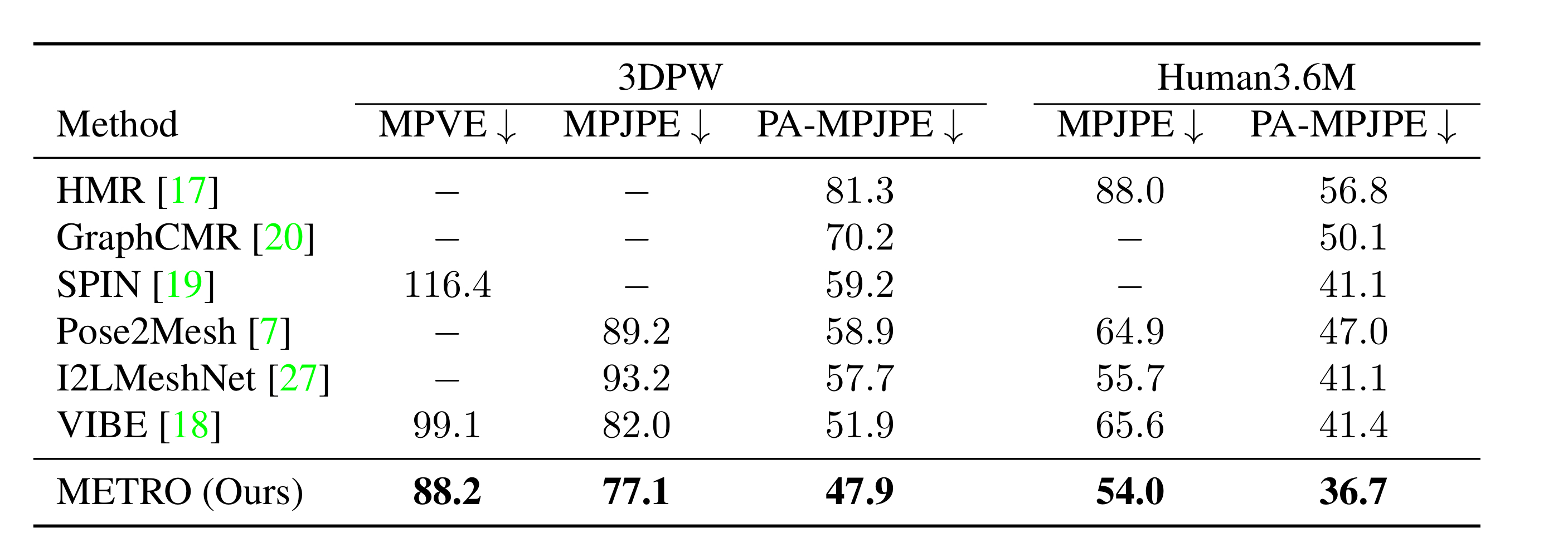
Outdoor-image dataset인 3DPW에서 transformer가 in-the-wild reconstruction 성능이 얼마나 좋은지를 평가했다.
VIBE라는 sota 모델은 비디오 기반 방법을 사용했지만, METRO는 이미지 기반의 방법이다.
또한 in-door scenario에 대한 성능 평가는 Human3.6M 데이터셋에서 진행했다. 특히 PA-MPJPE 값에 대한 성능 향상이 두드러졌다.
두 데이터셋의 특성이 조금 다른데, 3DPW 데이터셋에는 occlusion이 더 많고, Human3.6에는 body shape를 정확히 추정하기 더 어렵다.
METRO는 두 데이터셋 모두에서 state-of-the-art methods보다 좋은 성능을 보임으로써 occlusion(가려짐)에도 더 강인하고, body shape도 더 정확히 regression함을 알 수 있었다.
Ablation Study
for MVM
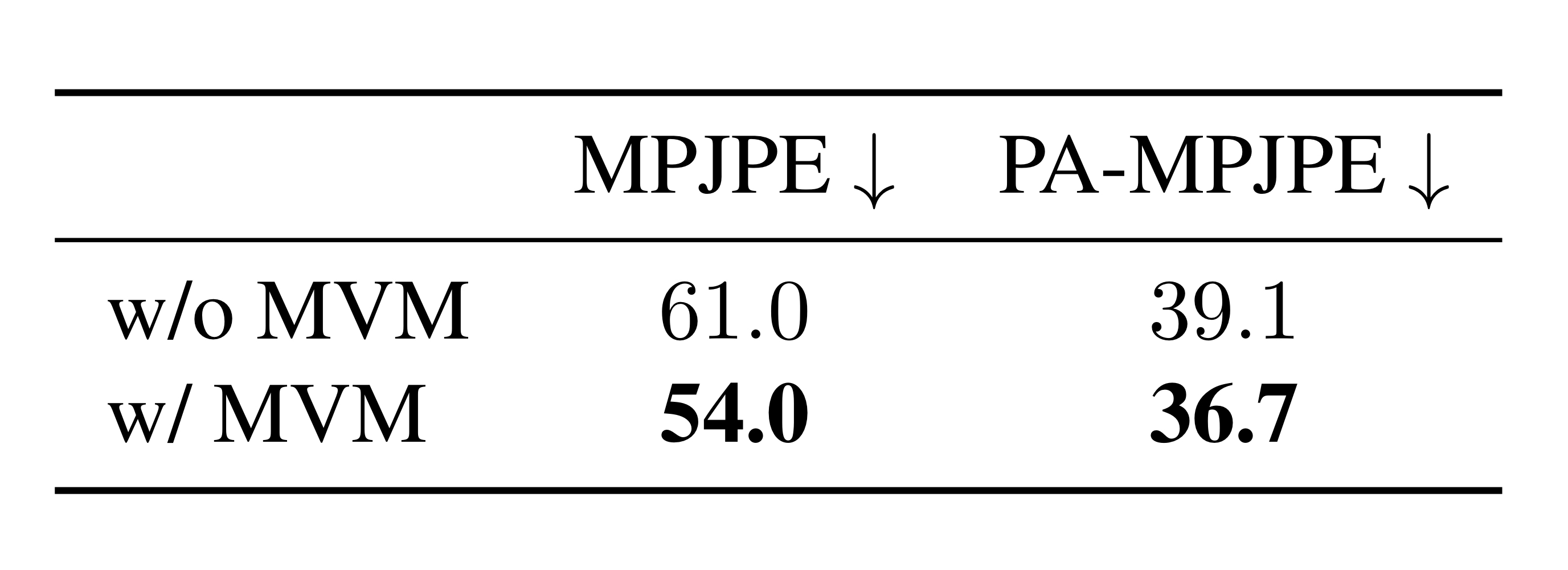

Human3.6M에서 진행한 ablation study에서 (1)과 같은 결과를 보였는데, 이를 통해 MVM을 적용했을 때 성능이 더 향상되었음을 알 수 있다.
또한, 서로 다른 비율의 masked queries를 사용하여 MVM objective를 사용해 보았을 때, masked queries가 높아질수록 성능이 좋아졌지만, 30%가 넘어가는 경우 그 효과가 사라졌다. 이는 missing queries가 너무 많아지기 때문일 것이다.
for Non-local Interaction
또한, Non-local Interaction에 대해 ablation study를 진행했다.

METRO는 'Input'열의 이미지를 입력받아, 'Output'열의 Human Mesh Reconstruction 결과를 낸다. 가운데 사진들은 특정 joint와의 모든 vertices 간의 self-attention을 나타낸다.
첫 행에서 상당한 부분이 가려진 이미지의 입력에 대해서도 좋은 성능으로 reconstruction을 해낸 것을 확인할 수 있고, 마지막 행에서 많이 구부린 (body shape) 모습의 사람도 reconstruction을 잘 해낸 것을 볼 수 있다.
또한, 이미지의 상황에 따라 다른 self-attention을 적용하는 모습을 볼 수 있다.
CNN Backbones
마지막으로, 서로 다른 CNN Backbone을 사용하였을 때의 성능을 비교해보았을 때, 다음과 같은 결과를 얻었다.
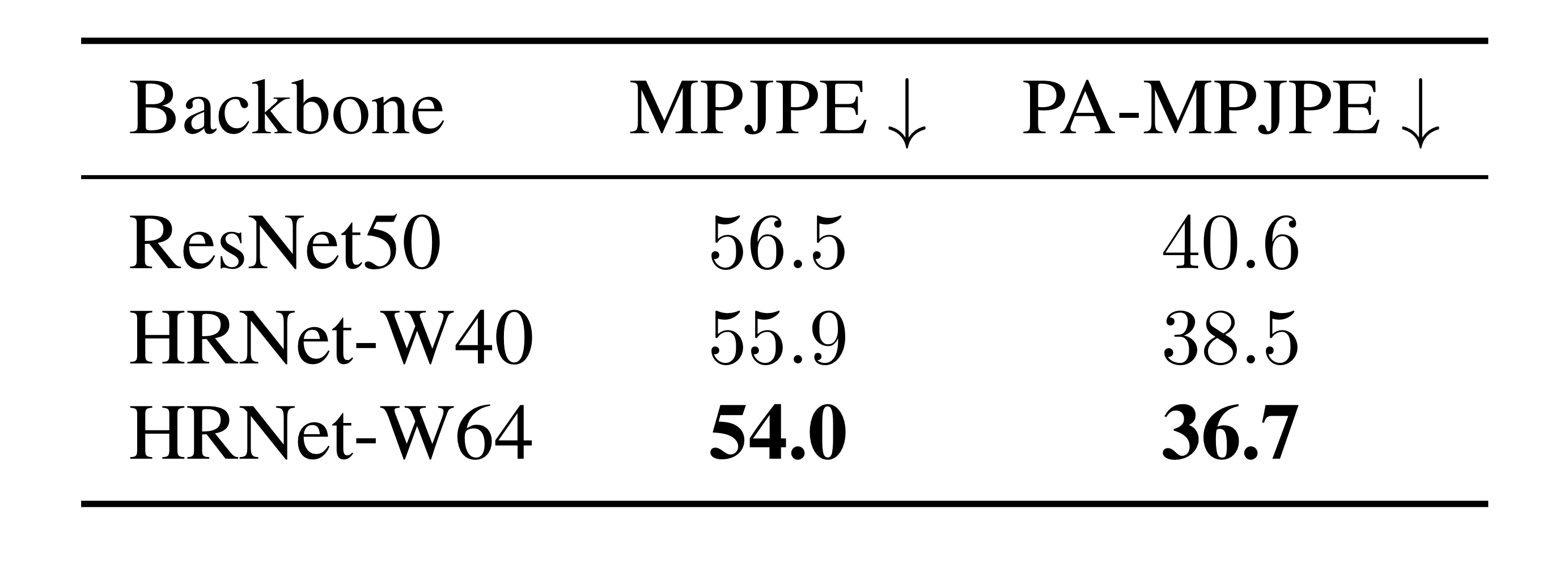
Human3.6M 데이터셋에서 비교했으며, feature map의 해상도가 높은 경우 (HRNet을 사용한 경우) 더 좋은 성능을 보였다.
Generalization to 3D Hand in-the-wild
METRO는 joints와 vertex를 예측할 때 인접 행렬이나 parametric coefficients가 필요 없다. 따라서 human pose & mesh vertices 이외의 object를 reconstruction하는 데에서의 성능도 좋다.
아래는 FreiHAND라는 데이터셋을 이용하여 3D Hand Reconstruction 실험을 진행해본 결과이다.

이 task에서도 state-of-the-art methods에 비해 성능이 꽤 큰 차이로 높아진 것을 확인해볼 수 있다.
정성적인 결과는 다음과 같다.









최근댓글