3D Scene Graph를 연구하기 앞서 관련 내용을 다룬 논문을 읽고 리뷰해보려 한다.
목차
Core Questions
논문을 읽고 얻은 insight를 정리해보자.
- What did authors try to accomplish?
- 다양한 semantic 정보와 서로의 관계를 담을 공간과 그 구조를 통합적으로 나타내는 3d scene graph를 제안하였다.
- 논문에서는 주로 scene graph 구조 중 node를 얻기 위한 방법을 소개한다.
- What were the key elements of the approach?
- Input : 3D mesh와 panorama 이미지(+camera parameter)
- Output : Semantic 정보를 표현한 3D scene graph
- What can I use myself?
- 3D scene graph 구조를 이해하고, 구성하는 방법을 알아본다.
- 앞으로의 scene graph 관련 연구의 기초를 잡는다.
- What other references do I want to follow?
- 이 논문을 기초로 다른 3D scene graph 논문을 이해할 것이다.
- What are the contributions of this paper?
- Scene graph로 3D semantic 정보를 담는 3D scene graph 패러다임을 제안했다.
- 다양한 object의 attributes, 두 object 사이의 relationships 등의 정보를 활용할 수 있다.
- 3D scene graph를 생성하는 과정에서 (특히 object에 대한 instance segmentation을 위해) semi-automatic하고, robust한 방법 제안
- 두 가지 constraints를 주어 기존 detection method를 보완했다.
- Framing : Panorama에서 query image를 framing하여 2D detector의 성능을 최대화했다.
- Multi-vew consistency : 서로 다른 위치의 카메라에서 얻은 2D detection으로 3D mesh에서의 labeling 성능을 보완했다.
- 두 가지 constraints를 주어 기존 detection method를 보완했다.
- Gibson 환경에서 기존 database에 3D scene graph를 추가 modality로 활용하여 확장했고, 이를 open source로 제공했다.
- Scene graph로 3D semantic 정보를 담는 3D scene graph 패러다임을 제안했다.
Introduction
로보틱스, 컴퓨터 비전 등의 분야에서는 어떤 장면에 대한 semantic 정보를 어디에 놓을지, 그리고 그 정보를 어떤 구조로 표현할지가 아주 중요하다.
Semantic 정보를 어디에 놓을 공간(space)을 생각해보자.
가장 흔하게 장면 정보를 담는 공간은 바로 이미지이다. 하지만 이미지를 구성하는 요소인 pixel은 외부 요인(parameter)에 의해 너무 쉽게 변하고, object의 전체 형상에 대한 정보는 담을 수 없다는 단점이 존재한다.
Scene의 semantic 정보를 담을 이상적인 공간의 조건은 다음과 같다.
- 외부 요인에 대해 최대한 invariant해야(변하지 않아야)한다.
- 이미지나 비디오 등 다른 domain 또는 task에 쉽게 연결될 수 있어야 한다.
이러한 조건을 고려해 보았을 때, 정보를 3차원 공간에 저장하는 것이 좋아 보인다.
여기서 semantic 정보를 3D space에 놓는다는 것은 곧 3D mesh 상에 semantic 정보가 입혀진다는 것을 말한다.
대표적인 예시로 다음과 같은 3D semantic segmentation task를 들어볼 수 있다.

3차원 공간에 정보를 저장하게 되면, semantic이 쉽게 이미지나 비디오에 projection될 수 있고, 이를 통해 annotation을 쉽게 작성할 수 있게 된다.
그렇다면 이러한 semantic 정보를 나타낼 구조는 어떻게 정해야 할까?
Semantic은 object class, natural language caption 등 다양한 종류가 있고, 그 표현 방법도 각각 다르다.
논문에서는 scene graph를 사용하는 것이 구조를 표현하는데 가장 적합하다고 말한다.
Scene graph의 특징은 다음과 같다.
- Object class 이외에도 attributes, relationships 등 다양한 정보를 표현할 수 있다.
- 언어로 표현한 caption보다 더 많은 구조 정보를 가질 수 있고, invariant하다.
따라서 논문에서는 기존 2D scene graph에서 3D 정보를 추가하여 3D scene graph를 구성하는 과정을 소개한다.
이때, 두 가지 constraint를 주어 결과가 더 일관성 있도록 해준다.
- Framing
- Multi-view Consistency
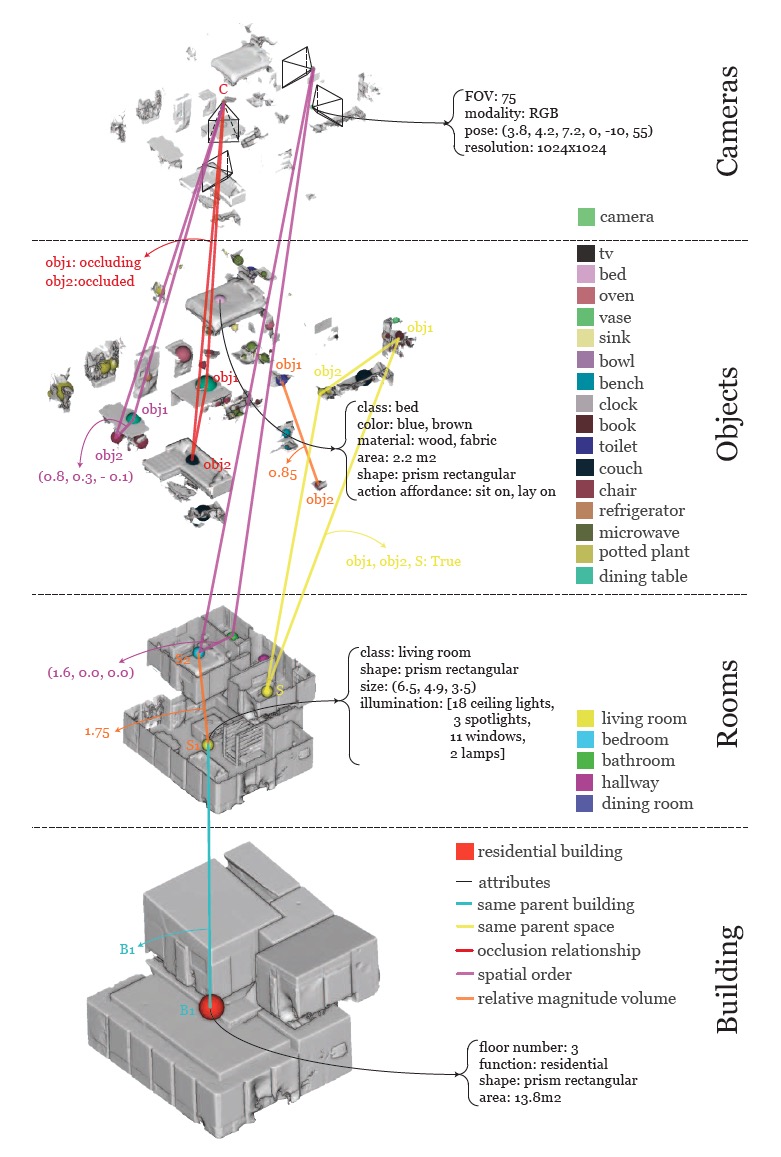
3D Scene Graph Structure
그렇다면 3D scene graph가 어떤 구조를 가지는지 살펴보자.
사실 scene graph는 어떤 항목을 포함하고, 어떤 구조를 갖는가에 따라 다양한 방법으로, 다양한 구조로 사용할 수 있다.
본 논문에서는 3D mesh model과 RGB 파노라마 이미지(+camera parameter)를 입력받아 4개의 layer를 갖는 3D scene graph를 만들어내는 과정을 소개하고 있다.
Graph는 노드와 엣지로 표현한 network이다.
논문에서는 다음과 같은 구조의 3d scene graph를 생성한다.
- Element (node로 표현)
- 1st layer : Building
- 주어진 mesh model의 root node로 표현한다.
- 2nd layer : Rooms
- 각 방 당 하나의 node로 표현한다.
- 3rd layer : Object
- 의자, 벽 등 다양한 object를 표현한다.
- 4th layer : Cameras
- 각 camera의 3차원 공간 상의 위치를 node로 표현한다.
- 1st layer : Building
- Attributes
- Element 각각이 갖는 특성이다. graph를 만드는 사람이 원하는 종류의 특성을 나타낼 수 있다.
- 예를 들어, 침대를 나타낸 node에 대한 attribute로는 class(침대), color(파란색, 갈색), material(나무) 등이 존재한다.
- Relationships (edge로 표현)
- 두 node 간의 관계를 나타낸다. 한 layer 내에서도, 서로 다른 layer간에도 relationship이 존재할 수 있다.
- 예를 들어, 같은 object layer 내에서 'obj1과 obj2 사이의 거리는 0.85이다.'(추상적으로 멀다, 가깝다 등으로 주어지는 경우도 많음), 혹은 서로 다른 layer 간에 'obj1은 room2 안에 있다.' 등의 관계를 나타낼 수 있을 것이다.
Constructing the 3D Scene Graph
3D scene graph를 구성하기 위해서는 그 구성 요소인 element, attribute, relationship을 정해야 할 것이다.
그런데, 주어진 구성 요소를 가지고 (사람이 직접) input인 RGB(파노라마 이미지)와 3d mesh 데이터에 라벨을 붙이고 공간 정보까지 annotation하는 것은 너무 비효율적인 작업이다.
따라서 기존에 존재하는 semantic detector(여기서는 Mask R-CNN)를 활용하여 이 과정을 자동화했다. 하지만 detection 성능이 완벽하지는 않으므로, 성능을 보완하기 위해 앞서 언급한 framing, multi-view consistency라는 두 가지 constraint를 주었다.
이때 framing은 2D(파노라마 이미지) detection에서 동작하고, multi-view consistency는 3D(mesh)로 이 정보를 옮길 때 동작한다.
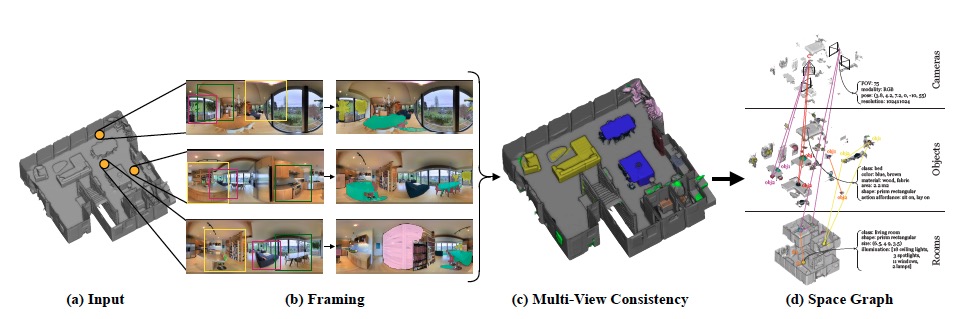
Framing on Panoramic Images
특히 2D semantic algorithm에서는 object가 일부만 보일 경우, detection이 부정확해진다. 이때 framing이라는 방법으로 보완할 수 있다.
Framing이란, 파노라마 이미지에서 직사각형 형태의 부분 이미지 여러 장을 sampling하여 detection 정확도를 높이는 방법이다.
그 과정은 다음과 같다.
- Object를 이미지 중심에 배치하고, 근처 context가 보이도록 적당히 확대/축소한다.
- 파노라마 이미지 하나에서 아래와 같은 yaw(\(\psi\)), pitch(\(\theta\)), Field of View(\(FoV\)) 조건에 따라 여러 이미지를 sampling하여 Mask-RCNN의 input으로 준다.
- \(\psi = [-180^\circ, 180^\circ, 15^\circ], \quad \theta = [-15^\circ, 15^\circ, 15^\circ], \quad FoV = [75^\circ, 105^\circ, 15^\circ]\)
- Sampling 결과 파노라마 이미지 하나 당 800 by 800 size의 (직사각형)이미지 225장을 얻는다.
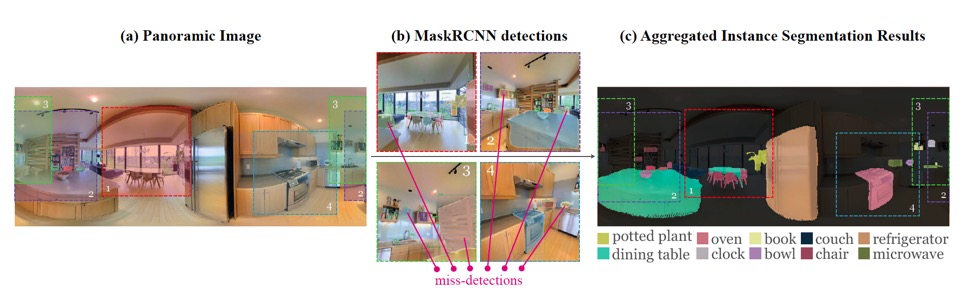
- 파노라마 이미지 상에 weighted voting scheme을 적용하여 segmentation 결과를 나타낸다.
Weighted voting scheme이란, 샘플링한 이미지의 detection 결과들을 통해 최종 파노라마 이미지의 detection 성능을 보정하는 과정이다.
\( w_{i, \lambda} = \sum\limits_{j, L_{d_{ij}} = \lambda} \cfrac{S_{d_{ij}}}{\lVert C_{d_{ij}} - C_j \rVert} \)
변수의 의미는 다음과 같다.
- \(i\) : 파노라마 이미지의 픽셀 index
- \(\lambda\) : class
- \(j\) : 파노라마 이미지에서 샘플링한 직사각형 이미지의 frame index
- \(L_{d_{ij}}\) : 파노라마의 \(i\) 픽셀에 대해 \(j\)번째 frame 직사각형 이미지에서 detection한 결과 class
- \(S_{d_{ij}}\) : confidence score (예측 결과에 대한 metric)
- \(C_{d_{ij}}\) : detection \(d_{ij}\)의 중심 픽셀
- \(C_j\) : \(j\)번째 frame의 중심 픽셀
Pixel 별로 예측 결과의 confidence score와 이미지 중심으로부터의 detection의 거리를 고려하여 weight를 구하고, 이를 통해 pixel 당 가장 score가 높은 class를 계산한다.
하지만, 픽셀에 대한 결과 class 각각을 파노라마에 그대로 입히면 해당 픽셀이 어떤 object instance에 속하는지에 대한 정보를 무시하여 local inconsistency(불일치) 문제가 발생한다.
따라서 직사각형 이미지에서 detection을 할 때 가장 score가 높은 class를 최종 label의 후보로 두고, 가장 많은 class를 최종 label로 선정한다.
이 과정에서, 파노라마는 instance별로 segment가 되는 것이 아니라, class별로 된다. 따라서 class별로 나뉜 결과를 instance로 연결시켜주는 작업을 거쳐 최종적으로 instance segmentation mask를 얻는다.
Multi-view Consistency
Multi-view Consistency는 서로 다른 파나로마 이미지로부터 얻은 semantic label을 결합하여 최종 mesh를 얻는 과정에서의 오류를 보완하는 과정이다.
3D mesh에 정합(register)된 RGB 파노라마로 annotation(2D pixel label을 3D surface에 투영)이 가능하다.
하지만, 파노라마 한 장만 projection하게되면 다음과 같은 문제가 발생한다.
- 파노라마에서의 label 결과가 부정확할 수 있다.
- 특정 object를 제대로 reconstruction하지 못할 수 있다.
- 이미지 픽셀과 mesh surface간에 misalignment(카메라 registration error)가 발생할 수 있다.
이러한 문제점 때문에 segmentation 결과도 부정확해지고, 따라서 이웃한 object로 label이 'leaking'하는 문제가 발생한다.
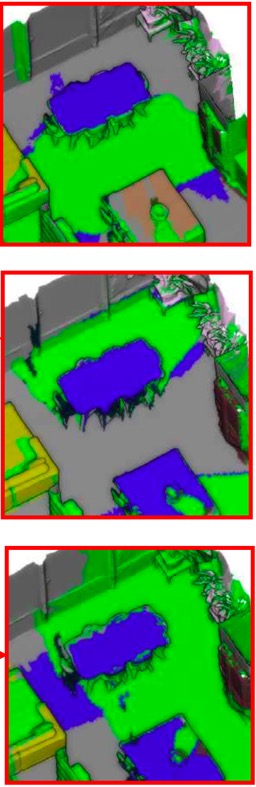
여러 파노라마 이미지에서 같은 object를 관찰하기 때문에, 이를 이용해서 문제를 해결한다. 이를 multi-view consistency라 한다.
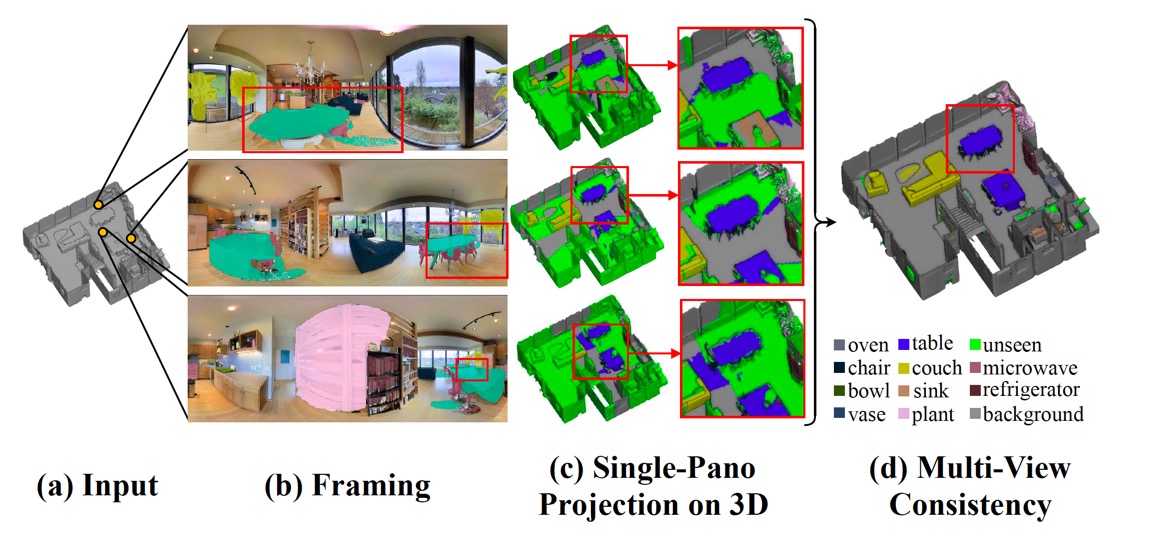
위에서 (d) 과정을 자세히 살펴보자.
3D mesh 표면에 파노라마 이미지에서의 label을 투영할 떄, weighted majority voting scheme을 사용한다. 이는 Framing에서의 voting scheme 과정과 비슷하다.
\( w_{i,j} = \cfrac{\sum\limits_{i, j} \lVert P_i - F_{c_j} \rVert }{\lVert P_i - F_{c_j} \rVert} \)
변수의 의미는 다음과 같다.
- \(i\) : 파노라마 이미지의 index
- \(j\) : Face의 index
- \(P_i\) : \(i\)번째 파노라마 이미지를 생성할 때의 카메라 좌표
- \(F_{c_j}\) : \(j\)번째 표면의 중심 좌표
Framing에서 weighted voting scheme은 파노라마 픽셀에 대한 weight를 구하기 위해 detection의 confidence score와 이미지 중심으로부터 detection의 거리를 고려했었는데, 여기서는 3d mesh의 face에 대한 weight를 구하기 위해 camera location으로부터 face 중심 사이의 거리를 고려한다.
해당 face가 카메라에 가까이 있을수록 분모가 작아지므로 weight가 커지는 것이다.
이렇게 계산한 weight로 파노라마 내에서 같은 instance의 face group \(F_{obj}\)에 대해 label consistency를 판단한다.
- Face 각각에 대한 weight를 모든 파노라마 이미지에 대해 구하여 \(F_{obj}\)의 label 후보를 구한다.
- 가장 많이 나타나는 후보를 \(F_{obj}\)의 최종 label로 정한다.
- 3D mesh에 대한 instance segmetnation mask를 얻는다.
이 label 정보는 파노라마 이미지에 다시 투영될 수도 있다. 따라서 2D label과 3D label이 일치할 것이다.
User-in-the-loop Verification (option)
위 과정을 통해 자동으로 2D 파노라마 이미지, 3D mesh에 일관성 있는 segmentation mask를 씌우는데, 논문에서는 이를 검증할 web interface를 제공한다.
이 과정은 사람이 직접 해주는 과정으로, 검증을 하지 않더라도 충분히 robust하므로 3D scene graph를 구성하는 과정에 필수적이지는 않으나, 생성된 data를 평가하거나, 에러를 완전히 없애줄 수 있다.
과정은 다음과 같다.
- Verification and Editing : 마지막 3d mesh label을 파노라마에 투영한 후에 직사각형 이미지를 렌더링한다.
- 유저에게 object를 보여주고, label을 직접 확인할 수 있도록 한다.
- Object의 segmentation mask를 확인할 수 있고, 조건을 충족시키지 못하면 새로운 segmentation mask를 추가해준다.
- Addition of Missing Objects : 놓친 object가 있을 수 있으므로, mask를 파노라마에 투영시킨 다음 5겹의 직사각형 이미지(이미지 당 72도 yaw difference를 주어 다양한 각도에서의 scene을 확인하도록 한다.)로 분해한다.
- 유저에게 어떤 object category의 instance를 놓쳤는지, 불완전한지를 묻는다.
- 모든 instance가 마스킹 될때까지 mask를 반복적으로 추가한다.
Computation of Attributes and Relationships
Verification까지 거치면 graph의 node에 해당하는 요소들을 얻는다. Scene graph의 attribute, relationship이 추가로 필요한데, 이는 기존에 존재하던 방법으로 얻는다.
그 자세한 과정은 supplementary material을 참조하자.








최근댓글