PyTorch를 간단히 다루어본 적이 있는데, 앞으로의 연구에 익숙하게 활용하기 위해 PyTorch 내용을 정리해보려 한다.
대부분의 내용은 유튜브의 '모두를 위한 딥러닝 시즌2'를 참고하였다.
기본적인 CNN, VGG, ResNet 내용과 파이썬 문법은 어느 정도 알고 있다고 가정하고, PyTorch 실습 내용 위주로 정리해두었다.
https://www.youtube.com/watch?v=opD4z9xoBv4&list=PLQ28Nx3M4JrhkqBVIXg-i5_CVVoS1UzAv&index=24
간단한 설명이 포함된 실습 자료는 Github를 참조하자.
GitHub - JJukE/Pytorch_DL_for_everyone: 파이토치 익히기 위해 '모두를 위한 딥러닝' 수강
파이토치 익히기 위해 '모두를 위한 딥러닝' 수강. Contribute to JJukE/Pytorch_DL_for_everyone development by creating an account on GitHub.
github.com
1. VGGNet
VGGNet은 Oxford의 VGG(Visual Geometry Group)에서 만든 네트워크이다.
구조가 간단하고 단일 네트워크로 좋은 성능을 보여주어서, 2014년 ILSVRC에서 1위를 차지한 GoogleNet보다 많이 응용되고 있다. (VGGNet은 당시 근소한 차이로 2위였다.)
종류는 다음 그림과 같이 다양하다.

그림에서 알 수 있듯이, VGGNet은 네트워크의 깊이가 성능에 어떤 영향을 주는지 연구하기 위해 설계된 네트워크이다. 구조를 보면 convolution kernel 사이즈는 3, padding 사이즈는 1로 (대부분) 통일해주었고, padding을 통해 convolution layer의 결과에서는 이미지의 사이즈가 변하지 않는다. 이미지 resize는 max pooling을 통해 하였다.
weight (parameter)의 개수에 따라 VGG-11 ~ VGG-19라고 부르며, 입력의 기준 크기는 3 × 224 × 224이다. (만약 input size가 다르다면, 기준 크기에 맞게 reshape해주어야 한다.)
그 중에서 VGG-16 (위 그림에서 D)를 구현해볼 것이다.
모델은 PyTorch에서 제공하는 'torchvision.models.vgg'라는 함수를 사용한다.
전체 코드를 살펴보자. 흐름은 비슷한데, 특별히 'make_layers'라는 함수를 정의하여 'cfg'라는 리스트에 정의된 대로 레이어를 만들어 쌓을 수 있도록 했다. (학습 시간이 매우 오래걸리므로 GPU 사용을 권장한다. 인텔 맥북프로 (cpu intel i7) 기준으로는 너무 오래걸려서 epoch을 3정도로만 학습시켰다. 3번 반복만 해도 2시간 넘게 소요되었다.)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import visdom
vis = visdom.Visdom()
vis.close(env="main")
# Define loss tracker
def loss_tracker(loss_plot, loss_value, num):
'''num, loss_value, are Tensor'''
vis.line(X=num,
Y=loss_value,
win=loss_plot,
update='append')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 여러 transform을 묶어줌
# Normalize(mean, std [,inplace]) -> inplace는 생략 가능
trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=512,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./cifar10', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog',
'frog', 'horse', 'ship', 'truck')
# get some random training images (in visdom)
data_iter = iter(trainloader)
images, labels = data_iter.next()
vis.images(images / 2 + 0.5)
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
# Make VGG16
import torchvision.models.vgg as vgg
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfg = [32, 32, 'M', 64, 64, 128, 128, 128, 'M', 256, 256, 256, 512, 512, 512, 'M'] # 13 + 3 = 16
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features # conv layer
# self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) # image가 7 by 7 보다 작으면 필요 없음
self.classifier = nn.Sequential(
nn.Linear(512 * 4 * 4, 4096), # 32 by 32 -> maxpooling 3번 -> 4 by 4
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
) # FC layer
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
# x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): # features에서 값을 하나씩 가져옴
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0) # VGG에서는 bias 값이 0
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
vgg16 = VGG(vgg.make_layers(cfg), 10, True).to(device)
# 확인
a = torch.Tensor(1, 3, 32, 32).to(device)
out = vgg16(a)
print(out)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(vgg16.parameters(), lr=0.005, momentum=0.9)
# 정밀한 학습을 위해 learning rate를 epoch이 지날 때마다 조금씩 낮춤
lr_sche = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.9) # scheduler step을 5번 실행할 때마다 lr에 0.9 곱함
# Make plot
loss_plt = vis.line(Y=torch.Tensor(1).zero_(), opts=dict(title='loss_trakcer', legend=['loss'], showlegend=True))
# Training (오래 걸림!)
print(len(trainloader))
epochs = 50
for epoch in range(epochs): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = vgg16(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 30 == 29:
loss_tracker(loss_plt, torch.Tensor([running_loss / 30]), torch.Tensor([i + epoch * len(trainloader) ]))
print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 30))
running_loss = 0.0
lr_sche.step()
print('Training Finished!')
# Result plot
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
data_iter = iter(testloader)
images, labels = data_iter.next()
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
outputs = vgg16(images.to(device))
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
# Test
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
2. ResNet
Convolution Layer에서 5 by 5 커널을 한 번사용하는 것이나 3 by 3 커널을 2번 사용하는 것이나 성능이 동일할 것으로 예측할 수 있다.
하지만 VGGNet 발표 당시 3 by 3 커널 두 번을 중첩하여 사용하는게 성능이 더 좋다고 한다.
이는 non-linear 함수인 ReLU가 더 많이 들어가 decision function이 더 잘 학습되기 때문이다.
또한 학습할 parameter가 줄어들어 학습 속도도 빨라진다.
그러나 VGGNet의 단점은 마지막 단에서 Fully Connected Layer를 3개나 붙여 파라미터 수가 급증하게 된다는 것이다.
그리고, 단순한 구조로는 어느 정도 이상 깊게 쌓으면 더 이상 성능이 좋아지지 않고 오히려 나빠지는 경향을 보였다.
이는 망이 깊어질 때 gradient vanishing/exploding이나 degradation 현상이 발생하기 때문이다.
1) Skip Connection
ResNet에서는 이 문제를 'skip connection'이라는 방법으로 해결했다.
평범한 CNN에서는 입력을 받아 layer에서 weight를 거쳐 출력을 내며, 이것이 다음 layer의 입력이 된다.
하지만 ResNet에서는 아래와 같이 현재 layer에서의 입력을 layer의 출력과 연결시켜 다음 layer의 입력에 더해준다.
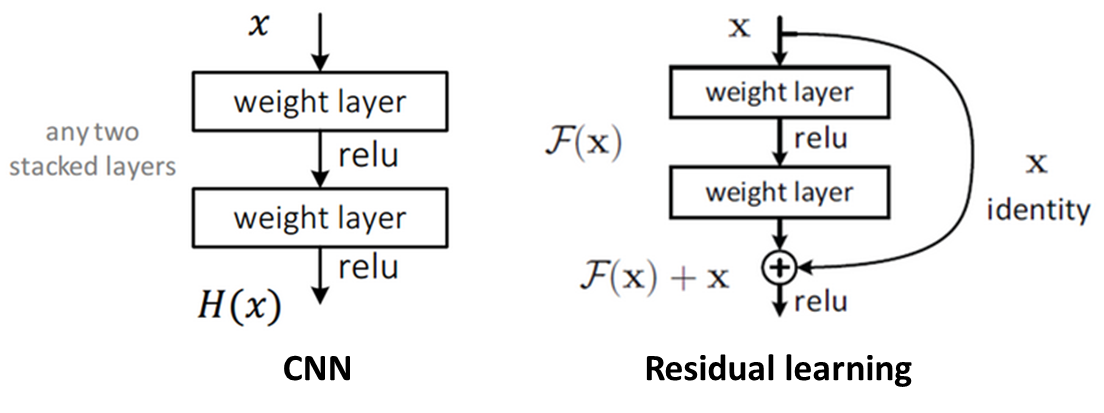
이 방법을 통해 VGGNet에서는 layer 수가 19개 이상이 되면 성능이 좋아지지 않고 오히려 나빠졌는데, ResNet은 layer 수를 152개, 더 나아가 약 1000개까지 늘려 성능을 높일 수 있었다.
이와 같은 결과가 나온 이유는, 기존 네트워크는 layer의 출력
2) Implementation
VGGNet과 마찬가지로 'torchvision.models.resnet'함수를 통해 구현할 수 있다. 입력 사이즈 기준 또한 3 × 224 × 224이다.
그런데, 어느 정도의 깊이로 쌓을 것인가에 따라 skip connection을 구현하는 방식이 조금 다르다.
ResNet-18/34에 사용되는 구조는 basicblock이라 하고, ResNet-50/101/152에 사용되는 구조는 bottleneck이라 한다.
그림과 코드를 살펴보자.
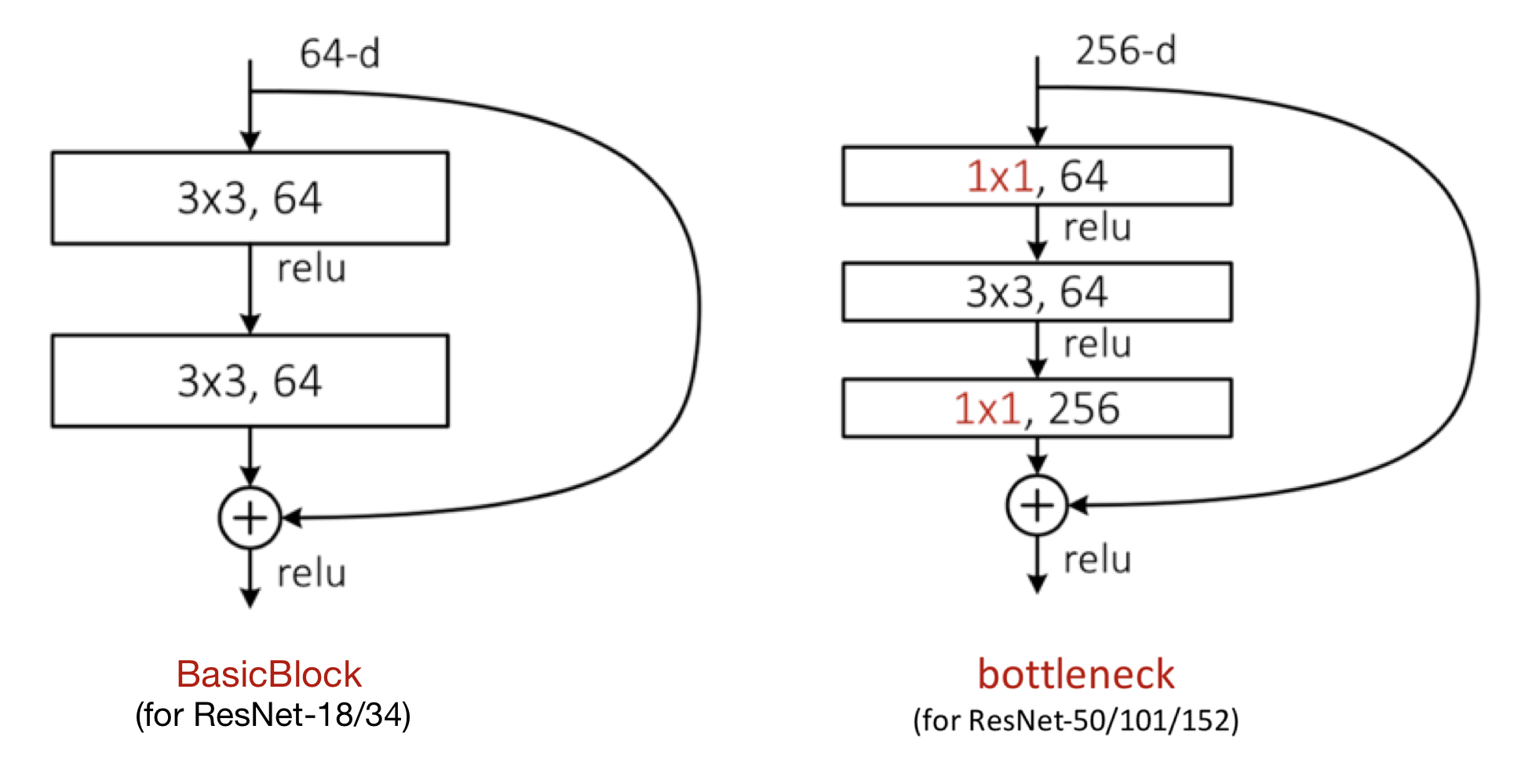
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
# BasicBlock
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x) # 3x3 stride = 2
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out) # 3x3 stride = 1
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
# Bottleneck
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = conv1x1(inplanes, planes) #conv1x1(64,64)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = conv3x3(planes, planes, stride)#conv3x3(64,64)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = conv1x1(planes, planes * self.expansion) #conv1x1(64,256)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x) # 1x1 stride = 1
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out) # 3x3 stride = stride
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out) # 1x1 stride = 1
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
여기서 downsample은 stride가 1보다 큰 경우, 입력의 크기는 그대로이지만 layer를 거치면서 out의 shape가 작아지므로 입력의 크기를 맞추어 줄여주는 것이다.
또한 Bottleneck에서는 'expansion' 함수를 통해 channel 개수를 늘려준다.
이제 본격적으로 ResNet Class를 살펴보자.
class ResNet(nn.Module):
# model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs) #resnet 50
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False):
super(ResNet, self).__init__()
self.inplanes = 64
# input.shape → (3, 224, 224)
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
# output.shape → (64, 112, 112)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0]'''3''')
self.layer2 = self._make_layer(block, 128, layers[1]'''4''', stride=2)
self.layer3 = self._make_layer(block, 256, layers[2]'''6''', stride=2)
self.layer4 = self._make_layer(block, 512, layers[3]'''3''', stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
# remind! → self.inplanes = 64
# remind! → self.layer1 = self._make_layer(block, 64, layers[0]'''3''')
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride), # conv1x1(256, 512, 2)
nn.BatchNorm2d(planes * block.expansion), # batchnrom2d(512)
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion #self.inplanes = 128 * 4
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes)) # * 3
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# ResNet-18 : BasicBlock 사용
def resnet18(pretrained=False, **kwargs):
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs) #=> 2*(2+2+2+2) +1(conv1) +1(fc) = 16 +2 =resnet 18
return model
# Resnet-50 : Bottleneck 사용
def resnet50(pretrained=False, **kwargs):
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs) #=> 3*(3+4+6+3) +(conv1) +1(fc) = 48 +2 = 50
return model
# Resnet-152 : Bottleneck 사용
def resnet152(pretrained=False, **kwargs):
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs) # 3*(3+8+36+3) +2 = 150+2 = resnet152
return mode
Bottleneck에서는 channel을 맞추기 위해서도 downsample을 사용함을 알 수 있다.








최근댓글