PyTorch를 간단히 다루어본 적이 있는데, 앞으로의 연구에 익숙하게 활용하기 위해 PyTorch 내용을 정리해보려 한다.
대부분의 내용은 유튜브의 '모두를 위한 딥러닝 시즌2'를 참고하였다.
기본적인 CNN 내용과 파이썬 문법은 어느 정도 알고 있다고 가정하고, PyTorch 실습 내용 위주로 정리해두었다.
https://www.youtube.com/watch?v=rySyghVxo6U&list=PLQ28Nx3M4JrhkqBVIXg-i5_CVVoS1UzAv&index=19
간단한 설명이 포함된 실습 자료는 Github를 참조하자.
GitHub - JJukE/Pytorch_DL_for_everyone: 파이토치 익히기 위해 '모두를 위한 딥러닝' 수강
파이토치 익히기 위해 '모두를 위한 딥러닝' 수강. Contribute to JJukE/Pytorch_DL_for_everyone development by creating an account on GitHub.
github.com
목차
1. PyTorch nn.Conv2d
Convolution 연산을 진행하는 코드를 통해 간단히 CNN 기본 개념을 살펴보자.
Convolution 연산이란, 이미지 위에서 stride 값 만큼 filter(또는 kernel)을 이동시키면서 겹쳐지는 부분의 각 원소의 값을 곱해서 모두 더한 값을 출력으로 하는 연산이다.
즉, Convolution Layer에서의 Parameter 개수는 filter size이고, 이를 여러 번 사용하여 효율적으로 학습을 진행할 수 있다.
PyTorch에서 제공하는 Convolution Layer를 만드는 코드는 다음과 같다.
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, gropus=1, bias=True)
주요 인자는 각각 다음과 같은 의미를 갖는다.
- in_channels, out_channels : 각각 input data와 연산 결과 output의 채널 수를 말한다.
- kernel_size : filter의 사이즈를 말한다. 보통 3 × 3, 5 × 5 사이즈의 필터(커널)를 많이 사용한다. → 튜플 형태로 지정해준다.
- stride : filter가 input에 대해 몇 칸씩 움직이며 연산을 수행할지를 의미한다.
- padding : input에 padding을 몇 겹 적용할지를 의미한다. output feature map의 사이즈를 input 사이즈 그대로 보존하기 위해 많이 사용된다.
Convolution Layer로 들어가는 입력의 type은 torch.Tensor이고,
shape은 (batch_size, channel, height, width) 형태를 갖는다.
또한 output의 size는 다음 식을 따른다.
\( \text{Output size} = \frac{\text{input size} - \text{filter size} + (2 * \text{padding})}{\text{Stride}} + 1 \)
2. Implementation of CNN with MNIST
이제 MNIST 데이터에 CNN을 적용해보자.
학습 단계는 다음과 같은 단계로 진행된다.
- 라이브러리를 import한다.
- (만약 GPU 사용한다면) GPU 사용을 설정한다.
- 학습에 사용되는 hyperparameters를 설정한다. (lr, epochs, batch size, ...)
- 데이터셋을 가져오고 학습에 쓸 수 있도록 data loader를 만든다.
- 학습 모델 (CNN)구조를 만든다.
- Loss Function과 Optimizer를 선택한다.
- 모델을 학습시키고 loss를 출력한다.
- 모델의 성능을 검증한다.(test)
앞선 포스팅에서 다루어본 내용이 대부분이므로, 여기서는 5번째인 CNN 구조를 PyTorch로 구현하는 과정을 자세히 살펴본 후에 전체 코드 및 결과를 살펴볼 것이다.
# CNN Model (3 conv layers and 2 Fully Connected Layers)
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.keep_prob = 0.5 # for dropout
# L1 ImgIn shape=(7, 28, 28, 1)
# Conv -> (7, 28, 28, 32)
# Pool -> (7, 14, 14, 32)
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
# L2 ImgIn shape=(7, 14, 14, 32)
# Conv -> (7, 14 ,14, 64)
# Pool -> (7, 7, 7, 64)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
# L3 ImgIn shape=(7, 7, 7, 64)
# Conv -> (7, 7, 7, 128)
# Pool -> (7, 4, 4, 128)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
)
# L4 FC 4×4×128 inputs -> 625 outputs
self.fc1 = torch.nn.Linear(4 * 4 * 128, 625, bias=True)
torch.nn.init.xavier_uniform_(self.fc1.weight)
self.layer4 = torch.nn.Sequential(
self.fc1,
torch.nn.ReLU(),
torch.nn.Dropout(p= 1 - self.keep_prob)
)
# L5 Final FC 625 inputs -> 10 outputs
self.fc2 = torch.nn.Linear(625, 10, bias=True)
torch.nn.init.xavier_uniform_(self.fc2.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1) # Flatten them for FC
out = self.layer4(out)
out = self.fc2(out)
return out위 코드의 구조를 그림으로 나타내면 다음과 같다.
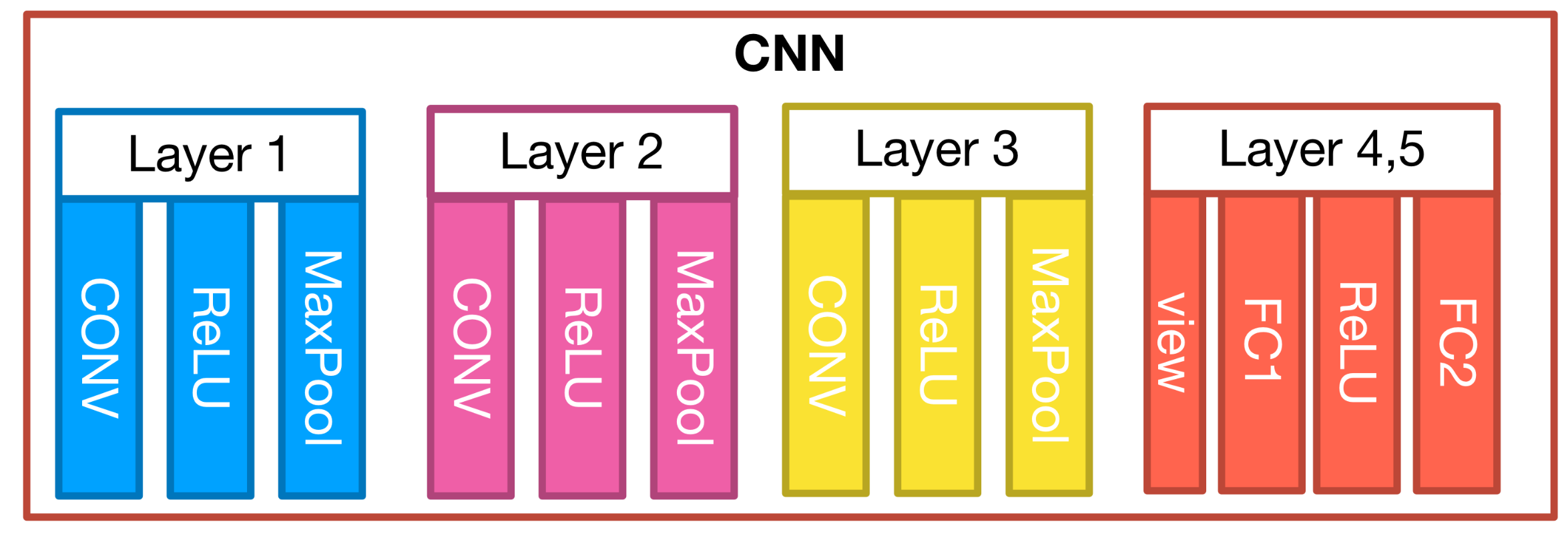
각 Convolution Layer에는 Conv2d, ReLU, MaxPool2d가 포함되고, Fully Connected Layer 2개를 지난다.
3. Visdom
Visdom이란, 구글의 텐서플로우(tensorflow)에서의 텐서보드(tensorboard)와 같이 Torch, PyTorch, NumPy 라이브러리를 사용할 때 시각화를 해줄 수 있는 툴이다.
가장 기초적인 visdom 사용법을 알아보자.
1) Visdom 설치
먼저, 다음 명령어를 통해 visdom을 설치해줄 수 있다. (터미널에서 가상환경 상에서 진행할 때는 느낌표(!)가 필요 없지만, jupyter notebook상에서 라이브러리 설치를 할 경우 느낌표를 넣어줘야 한다. 느낌표는 주피터 노트북에서 명령 프롬프트를 실행한다는 것을 의미한다.)
!pip install visdom
2) Visdom 서버 켜기
visdom은 웹상에서 시각화를 진행한다. 따라서 다음 코드를 통해 서버를 켜주어야 한다.
하지만 주피터 노트북에서 서버를 켜는 코드를 치게 되면 다음 코드를 실행시킬 수가 없으므로 (다음 셀을 실행시키려면 서버를 종료해야 하는데, 그러면 visdom을 사용할 수 없다.) 명령 프롬프트 (맥은 터미널)를 사용하여 서버를 켜준다.
python -m visdom.server
링크가 뜨는데, 들어가보면 다음과 같은 화면이 보일 것이다.

3) Visdom 기초 사용법
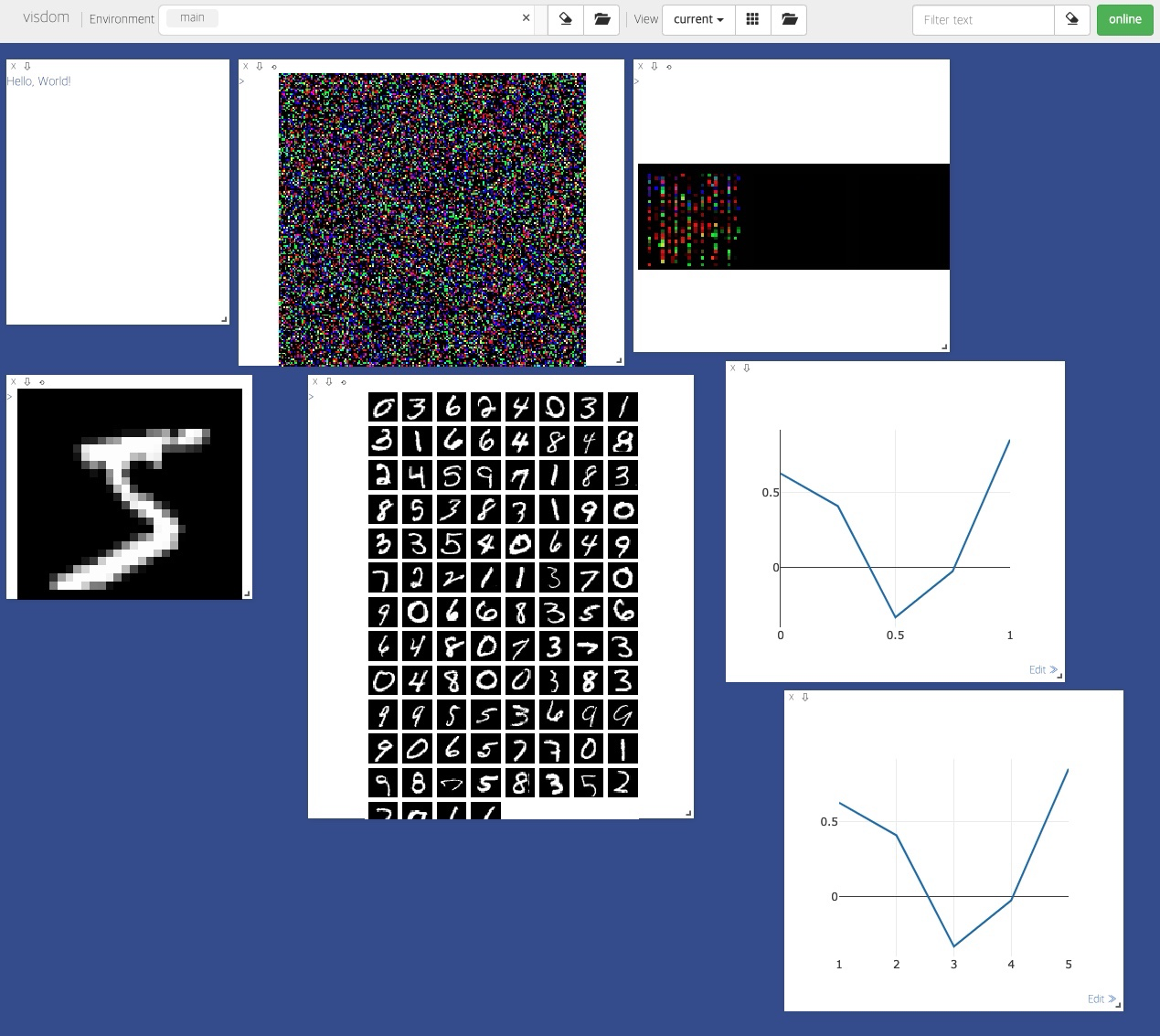
가장 기초인 text, image, images, line plot을 진행해보자.
주피터 노트북으로 돌아와서, 다음 코드를 작성한다.
# import
import visdom
# visdom 객체 생성
vis = visdom.Visdom()
# text 생성
vis.text("Hello, World!", env="main") # env: 나중에 창을 끌 때 사용할 수 있음
# image 한 개 생성
vis.image(torch.randn(3, 200, 200))
# image 여러 개 생성
vis.images(torch.Tensor(3, 3, 28, 28))
# 앞선 코드에서의 mnist 데이터 보기
data = mnist_train.__getitem__(0)
print(data[0].shape)
vis.images(data[0], env="main")
# data loader를 통해 데이터 여러 개 한 번에 확인
for num, value in enumerate(data_loader):
value = value[0]
print(value.shape)
vis.images(value)
break
# Line Plot
Y_data = torch.randn(5) # x값 없으면 0부터 1 사이의 값 생성됨
plt1 = vis.line(Y=Y_data)
X_data = torch.Tensor([1,2,3,4,5])
plt2 = vis.line(Y=Y_data, X=X_data)
# close the window
vis.close(env="main")
close 전까지의 결과는 다음과 같다. (실제 주피터노트북에서는 하나 생성할 때마다 한 셀씩 진행하였다. 한꺼번에 해도 결과는 같지만, 하나씩 해보자!)
4) Loss tracking with Visdom
visdom을 활용하여 학습 과정을 살펴볼 수 있다. 그 전에, line plot을 좀 더 알아보자.
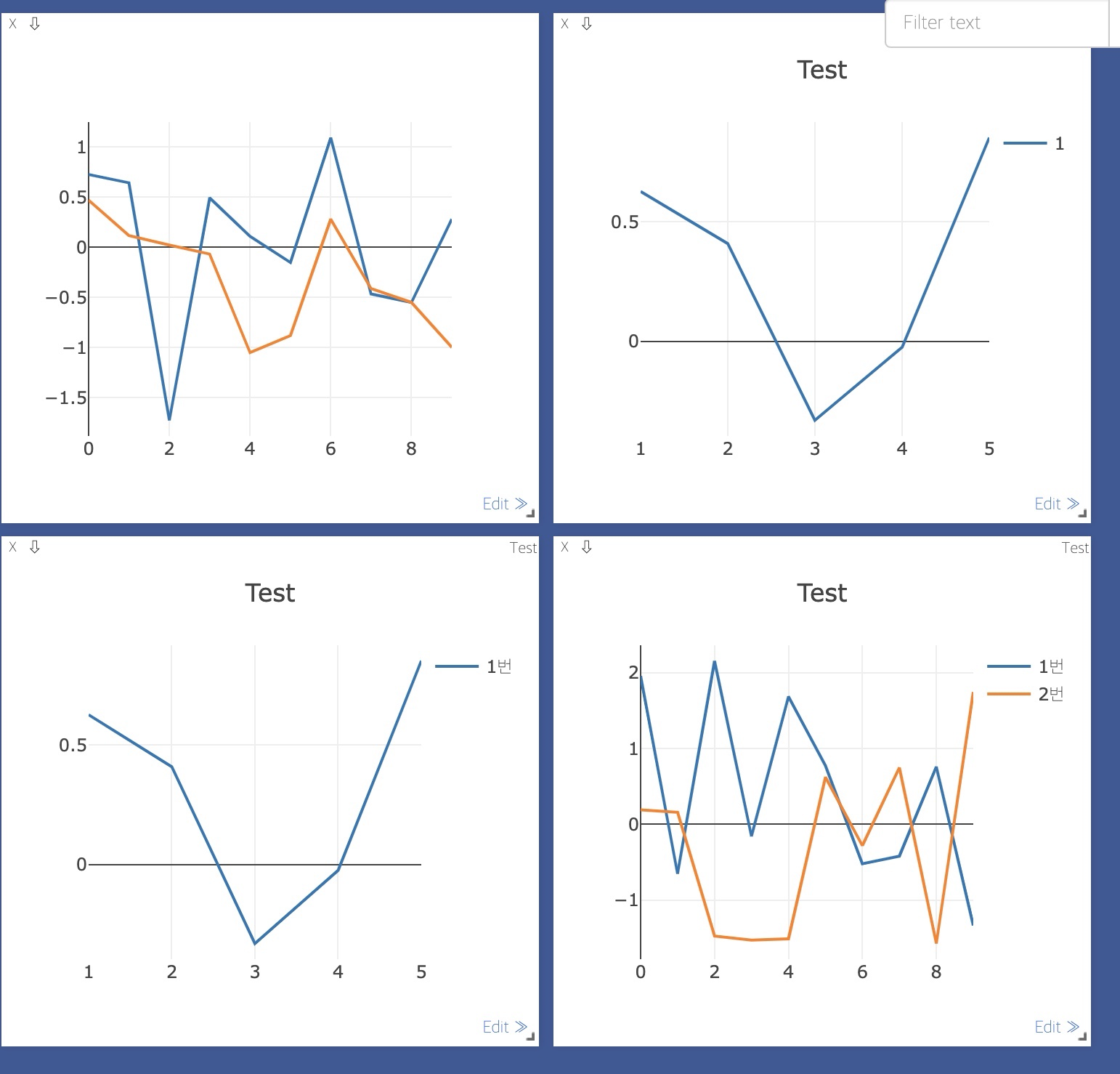
(1) Multiple Line on Single Windows
하나의 창에 여러 line plot을 띄울 수 있다.
line plot을 하는 함수는 'vis.line(Y=Y_data, X=X_data)'였는데, multiple line은 이와 비슷하게 다음과 같은 형태로 적용한다.
num = torch.Tensor(list(range(0,10)))
num = num.view(-1,1)
num = torch.cat((num,num),dim=1)
plt = vis.line(Y=torch.randn(10,2), X = num)
또한 다음과 같이 'opts' 인자에 dict()를 통해 그래프의 정보를 표현해줄 수도 있다.
[범례(legend) 표시]
plt = vis.line(Y=Y_data, X=X_data, opts = dict(title='Test', showlegend=True))
[범례(legend) 직접 표시]
plt = vis.line(Y=Y_data, X=X_data, opts=dict(title='Test', legend=['1번'], showlegend=True)) # 범례 직접 설정
[범례(legend) 여러 plot에 각각 표시]
plt = vis.line(Y=torch.randn(10,2), X=num, opts=dict(title='Test', legend=['1번', '2번'], showlegend=True)) # 2개 동시에 plot
4개의 plot 결과는 다음과 같다.
(2) Function for update line
본격적으로 학습 과정을 plot하기 위해서는 함수를 만들어두고 필요할 때마다 사용하는 것이 효율적일 것이다.
아래와 같이 함수를 정의하자.
def loss_tracker(loss_plot, loss_value, num):
'''num, loss_value are Tensor'''
vis.line(X=num, Y=loss_value, win=loss_plot, update='append')
vis.line의 'win'인자는 plot의 이름을 나타내고, num은 index가 될 것이다.
'update'인자는 말그대로 어떤 방식으로 plot을 갱신할 것인지를 말하는데, 인자로 'append'를 부여함으로써 loss_value가 생길 때마다 값을 하나씩 추가하며 plot을 update해줄 것이다.
결과는 아래와 같다.
5) MNIST with visdom
이제 MNIST 데이터 학습에 visdom을 활용해보자.
전체 코드는 아래와 같다.
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torch.nn.init as init
import torch.optim as optim
# Import visdom
import visdom
vis = visdom.Visdom()
vis.close(env="main")
# Define loss_tracker
def loss_tracker(loss_plot, loss_value, num):
'''num, loss_value are Tensor'''
vis.line(X=num,
Y=loss_value,
win=loss_plot,
update='append'
)
# Device setup
# if gpu avialable
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
# Parameters
learning_rate = 0.001
training_epochs = 15
batch_size = 32
# Load MNIST Dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train = True,
transform=transform.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
# Build CNN model
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc1 = nn.Linear(3 * 3 * 128, 625)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(625, 10, bias=True)
init.xavier_uniform_(self.fc1.weight)
init.xavier_uniform_(self.fc2.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
return out
model = CNN().to(device)
value = (torch.Tensor(1, 1, 28, 28)).to(device)
print( (model(value)).shape)
# Make plot
loss_plt = vis.line(Y=torch.Tensor(1).zero_(),
opts=dict(title='loss_tracker',
legend=['loss'], showlegend=True))
# Train with loss_tracker
total_batch = len(data_loader)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch: {} / {} cost = {}'.format(
epoch+1, training_epochs, avg_cost))
loss_tracker(loss_plt, torch.Tensor([avg_cost]), torch.Tensor([epoch]))
print('Learning Finished!')
# Test
with torch.no_grad():
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy: ', accuracy.item())
위와 거의 동일한데, visdom을 import하고 loss_tracker 함수를 선언해주는 부분, loss_plt를 통해 그래프를 만들어주는 부분과 training 과정에 loss_tracker 함수를 호출하는 부분이 추가되었다.
plotting의 결과는 다음과 같다. (학습 도중에 위에서 본 바와 같이 그림이 실시간으로 update됨을 알 수 있다.)
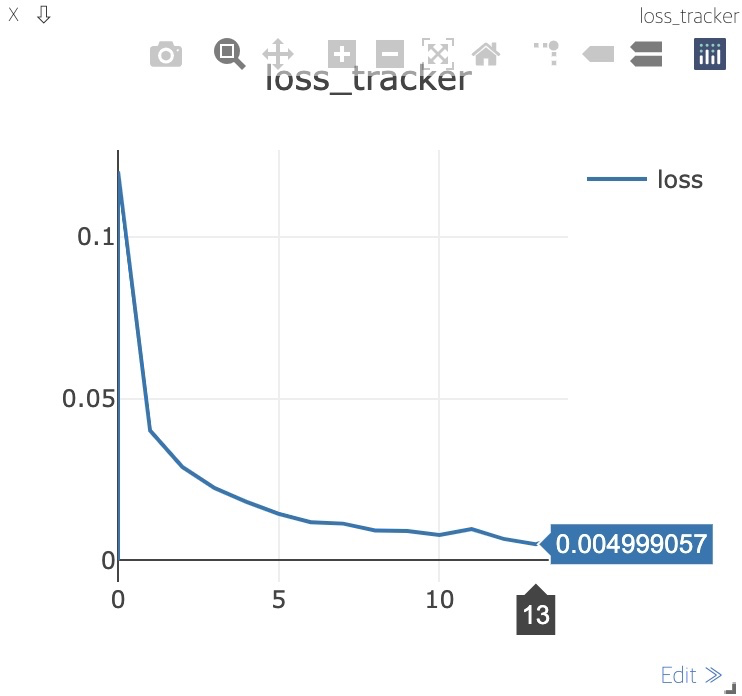
다음 링크에 들어가보면, visdom을 활용하는 더 다양한 방법을 볼 수 있다.
GitHub - fossasia/visdom: A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Torc
A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Torch and Numpy. - GitHub - fossasia/visdom: A flexible tool for creating, organizing, and sharing ...
github.com
3. ImageFolder
연구를 하다보면 PyTorch에서 제공한 dataset 이외의 dataset을 불러와야 하는 경우가 많다.
이렇게, 새로운 dataset을 불러오는 방법을 간단하게 알아보자.
# ImageFolder
train_data = torchvision.datasets.ImageFolder(root='[data_경로]', transforms=None)
여기서, transforms를 ImageFolder 함수 내에서 일일이 적용하다보면 매우 귀찮으므로, 다음과 같이 묶어서 선언해줄 수 있다.
from torchvision import transforms
trans = transforms.Compose([
transforms.Resize((64,128))
])
train_data = torchvision.datasets.ImageFolder(root='[data_경로]', transforms=trans)
# label이 0 또는 1인 경우
for num, value in enumerate(train_data):
data, label = value
print(num, data, label)
if(label == 0):
data.save('[저장할_경로(확장자까지 포함)]'%(num, label))
else: # label이 1인 경우
data.save('[저장할_경로(확장자까지 포함)]'%(num, label))
trans 내에서 transforms.ToTensor()를 통해 텐서 형태로 만들어주거나, 위와 같이 이미지 사이즈를 변경해줄 수 있다.
반복문 부분은 불러온 데이터를 local 환경에 저장하는 과정이다.
4. Model Save & Load
학습이 매우 오래걸릴 때에는 아래와 같이 학습 중간에 모델을 저장하거나 불러올 수 있다.
또는 학습이 완료된 모델을 어딘가에서 사용해야 할 때 특정 경로에 저장하고, 이후에 불러올 수 있다.
# save
torch.save(model.state_dict(), "./model/model.pth")
코드 그대로, 학습을 위해 선언해준 'model'이라는 (CNN 모델)인스턴스의 state를 지정한 경로에 저장해주는 것이다.
저장한 모델을 불러오는 코드는 다음과 같다.
new_model = CNN().to(device)
# load
new_model.load_state_dict(torch.load('./model/model.pth'))







최근댓글