비교적 최근인 2019년도에 object detection 분야에 관한 리뷰 논문이 있어, 읽어보고자 한다.
0. Abstract, Conclusion
1) Abstract
object detection 분야는 비디오 분석, 이미지 이해와 관련이 많아 최근 연구가 많이 진행되고 있다.
전통적인 object detection 방법은 handcrafted feature(사람이 직접 정한 특징) 또는 얕게 훈련시키는 아키텍쳐를 기반으로 구축된다. 이 경우 여러 low level image 특징들을 high level context와 결합하여 복잡한 ensemble로 구현할 경우 쉽게 침체된다.
semantic(의미론적)하고, high level이며, 더 깊은 feature를 학습할 수 있는 딥러닝과 강력한 tool들이 빠르게 발전하면서 이러한 한계를 극복해 나가고 있다. 이러한 모델은 network 아키텍쳐, strategy 학습, optimization function 측면에서 다르게 작동한다.
본 논문에서는 다양한 deep learning 기반 object detection framework를 리뷰한다.
간단한 딥러닝 역사와 representative tool, 즉 Convolutional Neural Network로 시작하여, 이를 수정하거나 유용한 trick을 사용하여 감지 성능을 훨씬 높인 전형적인 object detection architecture들을 집중적으로 살펴본다. detection task들은 각각 다른 특징을 보이므로, 간단히 salient object detection(SOD, 중요 물체 검출), face detection, pedestrian detection 등의 특정 task들을 알아볼 것이다. 또한 실험적인 분석도 알아볼 것이다. 마지막으로, object detection 및 관련된 neural network 기반 학습 시스템의 미래 역할에 대한 가이드라인이 될 유망한 방향과 task들을 제시한다.
2) Conclusion
강력한 학습 능력과 그림자, scale 변화, 배경 변화를 다루는 데 있어서의 강점 덕분에 딥러닝 기반 object detection에 대한 연구는 매우 활발하다.
본 논문에서는 폐색, 클러터, 저해상도 등의 subproblem들을 다루는, R-CNN을 서로 다르게 수정하는 딥러닝 기반 object detection에 대해 자세히 다루었다.
다른 task의 기반 아키텍쳐를 제공하는 generic object detection pipeline에서부터 시작하여 salient object detection, face detection, pedestrian detection을 다루었다.
마지막으로, object detection 분야를 완전히 이해하기 위한 미래 연구 방향을 제시하였다.
이러한 리뷰는 인공신경망 및 관련 학습 시스템의 개발에도 의미있으며, 이는 미래 연구 과정에서 통찰과 가이드라인을 제공할 것이다.
1. Introduction
image를 완전히 이해하기 위해, 우리는 서로 다른 image를 구분하는 것뿐만 아니라 각 이미지에 포함된 object들의 개념과 위치를 정밀하게 추정할 수 있어야 한다. 이러한 task를 object detection이라 하는데, 이는 face detection, pedestrian detection, skeleton detection 등의 subtask로 구분된다.
computer vision의 기본적인 문제 중 하나로, object detection은 이미지와 비디오의 의미론적(semantic) 이해에 대한 정보를 제공하고, 이미지 분류, 사람의 행동 분석, 얼굴 인식, 자율주행 등의 분야에 적용될 수 있다.
neural network 및 관련 학습 시스템을 계승하는 동시에 이 분야의 progress는 neural network 알고리즘을 개발하고, learning system으로 간주되는 object detection 기술에 큰 영향을 줄 것이다.
하지만, 시야, 포즈, 그림자, 조도 등 다양한 환경 때문에 완벽한 object detection은 매우 어렵다. 따라서 최근 이 분야가 많은 주목을 받고 있다.
object detection의 문제는 다음과 같이 정의된다.
- object localization : 주어진 이미지에서 물체가 어디에 위치하는지 알아내는 것
- object classification : 물체가 어떤 종류인지 알아내는 것
따라서, 전통적인 object detection 모델의 pipeline은 informative regeion selection, feature extraction, classification의 3가지로 나뉜다.
1) Informative Region Selection
물체들은 어떤 위치에서든 나타날 수 있고, 각각 다른 aspect ratio나 크기를 가질 수 있으므로, multiscale sliding window로 전체 이미지를 스캔하는 것이 자연스럽다.
이러한 전략이 물체가 존재할 수 있는 모든 곳을 찾는다고 해도, 단점 또한 명백하다. window의 크기가 다양하므로, 계산량이 많고 너무 많은 redundant window를 생산할 수도 있다.
하지만, sliding window template의 수를 정해두고 적용한다면, 만족스럽지 못한 영역이 생성될 수도 있다.
2) Feature Extraction
서로 다른 물체들을 인식하기 위해, 우리는 feature를 추출할 필요가 있다. feature는 의미론적이고 강인한 표현을 제공한다. scale-invariant (scale에 상관없는) feature 변환, HOG(histograms of oriented gradients), Haar-like feature 등이 표현 중 하나이다. 이것은 이러한 feature들이 복잡한 사람의 뇌와 연관된 표현을 제공할 수 있다는 사실 때문이다.
하지만, 외관, 조도, 배경 등에 따라 다양하게 나타날 수 있으므로, 모든 종류의 물체를 완벽하게 묘사할 수 있는 강인한 feature descriptor를 매뉴얼하게 설계하는 것은 어렵다.
3) Classification
게다가, classifier는 목표 물체와 다른 카테고리의 물체들을 분류하고, representation을 더 계층적이고, 으미론적이고, informative하게 만드는데 필요하다.
보통 SVM(Supported Vector Machine), AdaBoost, DPM(Deformable part-based model)이 많이 사용된다.
특히 DPM은 물체의 특정 부분과 deformation cost를 결합함으로써 flexible한 모델이다. graphical model을 추가하여 low level feature들을 설계하고 움직이는 부분을 결합한다. graphical model을 구분적으로 학습하여 다양한 object class에 대해 정밀한 part-based model을 만들 수 있다.
이러한 구분적인 local feature descriptor들과 얕은 학습이 가능한 아키텍쳐들에 기반하여, 최신 기술은 PASCAL VOC(Visual Object Classes) object detection competition에서 얻어지며, 실시간 embedded system은 하드웨어의 경량화로 얻어졌다.
하지만, 2010년부터 2012년도까지는 오직 앙상블 시스템과 몇몇 성공한 방법들에 작은 변화를 가하는 정도로 조금씩 성장하였다. 이는 bounding box 생성에서의 비효율성, redundant, 부정확성에 의해서, 그리고 low level descriptor와 얕은 모델들간의 결합에 의해 의미론적인 차이가 해소되지 않았기 때문이었다.
DNN(Deep Neural Network)덕에, R-CNN에서 CNN(Convolutional Neural Network) 방법이 소개되면서 중요한 gain을 얻었다.
DNN, 또는 대부분의 representative CNN은 전통적인 모델들과 완전히 다른 방법으로 접근했다. 얕은 feature가 아닌 더 복잡한 feature를 학습할 수 있는 깊은 아키텍쳐를 갖고 있었고, 표현 능력과 강인한 학습 알고리즘이 feature를 매뉴얼하게 설계할 필요 없이 object의 정보를 학습할 수 있게 해주었다.
R-CNN 이후로 classification과 bounding box 생성을 연결하여 최적화할 수 있는 faster R-CNN, 고정된 grid regression으로 object detction을 진행하는 YOLO(You Only Look Once) 등 이를 향상시킨 많은 모델들이 제안되었다.
이들은 모두 R-CNN에 비해 감지 성능을 월등히 향상시키고, 실시간으로 정확한 object detection을 할 수 있게 했다.
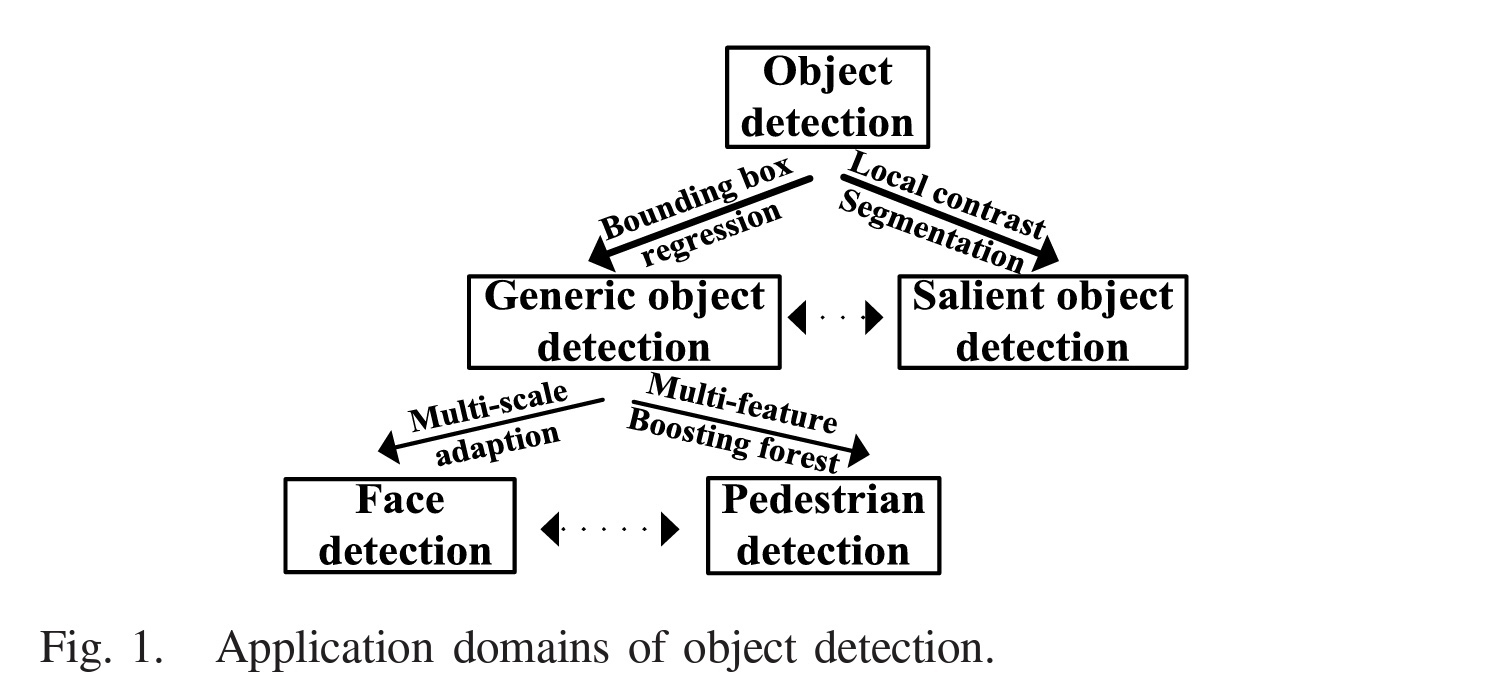
본 논문에서는 representative model들에 대한 간략한 리뷰와 generic object detection, salient object detection, face detection, pedestrian detection 등 application 도메인에서의 서로 다른 특징을 다룬다. 위 그림에서 이러한 관계를 확인할 수 있다.
기본적인 CNN 아키텍쳐에 기반하여 generic object detection은 bounding box regression으로 얻을 수 있고, salient object detection은 local contrast segmentation으로 얻을 수 있다.
또한 Generic Object Detection 기반의 Face Detection은 multiscale adaption으로 수행할 수 있고, Pedestrian Detection은 multi-feature fusion/boosting forest로 수행한다.
점선은 서로 연관이 있는, 일치하는 domain을 뜻한다. 이는 곧 커버된 도메인이 다양하다는 의미이다. 위 그림에서 Pedestrian과 Face image는 regular structure를 갖는 반면 general object와 scene image는 geometric strucrue와 layout 상에서 더 복잡한 다양성을 갖는다. 따라서, 서로 다른 deep model이 필요하다.
이와 관련하여, 최근 연구들은 특정 알고리즘을 거의 세분화하지 않고 이미지 분류와 물체 탐지에 관한 딥러닝 기술을 수행하는 소프트웨어 tool들에 집중하려하는 경향이 있다. 이와 달리, 본 논문에서는 다양한 application domain을 자세히 커버하는 딥러닝 기반 object detection 모델과 알고리즘에 관한 리뷰뿐만 아니라 해당 모델 및 알고리즘의 실험적인 비교와 의미있는 분석을 제공한다.
그리고 Section 2에서 딥러닝의 간단한 역사와 기본적인 CNN 아키텍쳐에 대한 소개를 하고, Section 3에서 Generic Object Detection 아키텍쳐를 소개한다. 그리고 CNN이 적용된 특정 task들(salient object detection, face detection, pedestrain detection)을 Section 4 ~ 6에서 알아볼 것이며, 유망한 미래 연구 방향을 Section 7에서 제안한다. 마지막으로, Section 8에서 결론을 맺는다.








최근댓글