목차
Transformer를 활용한 (비교적 최신의) 대표적인 언어 모델에는 BERT, GPT 등이 있고, vision 분야에 활용한 예로는 ViT, Swin Transformer 등이 있다. BERT를 이해하기 위해서는 self-supervised training에 대해 이해해볼 필요가 있다. (특히, CLIP과 같이 text와 vision domain에 걸쳐 학습을 진행하는 multi-modal 모델을 이해할 때에도 이 개념이 활용된다.)
Self-attention과 transformer의 기초 내용을 먼저 숙지하고 self-supervised training을 이해해보자.
Transformers in Vision - (1) Attention & Transformer
Transformer가 computer vision에서 어떻게 쓰였는지, 관련 모델이 어떻게 발전하고 있는지 여러 포스팅에 걸쳐서 알아보고자 한다. 이번 포스팅에서는 가장 중요한 기초 내용인 attention과 transformer에 대
jjuke-brain.tistory.com
Transformer
Transformer를 간단히 복기해보자. Task는 'I did not submit the assignment'라는 영어 문장을 한국어로 변역하는 machine translation이라 하자.

Self-attention 계산은 Fig 1에서와 같이 각 encoder와 decoder의 multi-head attention 모듈과 masked multi-head attention 모듈에서 수행한다.
기본 self-attention은 아래와 같은 수식으로 계산된다.
\( f(\mathbf{x}, \{ ( \mathbf{x}_i, \mathbf{x}_i \}_{i=1}^n ) = \sum\limits_{i=1}^n \alpha (\mathbf{x}, \mathbf{x}_i) \mathbf{x}_i \)
이는
입력한 문장 'I did not submit the assignment' 각각의 단어를 처리하는데, 모든 단어와 각 단어의 관련성을 계산하는 과정이다.
Multi-head self-attention은 아래와 같이 여러 head에 각각의 weight을 두어 self-attention을 여러 번 계산한다.
\( \mathbf{h}_m = f(\mathbf{W}_m^{(q)} \mathbf{x}, \{ \mathbf{W}_m^{(k)} \mathbf{x}_i, \mathbf{W}_m^{(v)} \mathbf{x}_i \}_{i=1}^n ) = \sum\limits_{i=1}^n \alpha ( \mathbf{W}_m^{(q)} \mathbf{x}, \mathbf{W}_m^{(k)} \mathbf{x}_i ) \mathbf{W}_m^{(v)} \mathbf{x}_i \)
query, key, value에 해당하는 weight에 따라 중요한 token을 계산한다. 이러한 weight을 optimize함으로써 학습을 진행할 수 있다.
Multi-head attention vs Masked multi-head attention
Transformer는 RNN 기반 모델과 달리 모든 시점의 입력을 입력받는다. 따라서 \(t\)까지의 정보만 가지고 \(t+1\) 시점을 예측하고자 할 때, decoder에서 일반적인 multi-head attention을 사용하면 이후 입력까지 모두 아는 상태와 같아진다. 따라서 Transformer의 decoder에서는 미래의(아직 알지 못한다고 가정하는)입력 부분은 '\(-\inf\)'로 마스킹하여 multi-head attention을 계산하는 Masked multi-head attention을 사용한다.
좀 더 깊은 내용이 궁금하다면 링크를 참조하자.
여기서 주목할 점은, 일반적인 self-attention은 모든 input token을 사용하기 때문에 parrallel computation이 가능하지만, masked self-attention은 가려진 부분을 사용할 수 없으므로 parrallel computation이 불가능하다는 점이다.
Advanced Transformers
Transformer 기반의 모델은 아래와 같다. 보통은 encoder 부분이나 decoder 부분 하나만 사용한다.
- Encoder Part of Transformer (Bidirectional Transformer)
- BERT (Devlin et al., ACL 2019)
- ViT (Dosovitskiy., ICLR 2021)
- TokenGT (Kim et al., NeurIPS 2022)
- Decoder Part of Transformer (Masked self-attention 활용)
- GPT (Radford et al., 2019; Brown et al., NeurIPS 2020)
여러 domain에서 사용된 transformer의 예시는 아래와 같다.
- NLP
- BERT, GPT
- CV
- Vision Transformer
- Graph
- Graph Transformer
- Reinforcement Learning
- Decision Transforemer
Design Principles of Transformer in DL
Transformer가 항상 다른 기본적인 모델(CNN, RNN 등)보다 좋은 성능을 나타내는 건 아니다. Inductive bias가 적기 때문이다. Inductive bias의 개념은 링크를 참조하자.
CNN, GNN, RNN 등보다 inductive bias가 적으므로 dataset 양이 적은 경우 성능이 좋지 않다. (design principle이 적다.)

따라서, Fig 2와 같이 매우 적은 데이터로는 traditional ML(Random Forest 등)을, 그보다 조금 더 많다면 inductive bias가 높은 딥러닝 모델(CNN, GNN, RNN 등)을, 매우 많은 데이터를 갖고 있다면 Transformer 기반 모델(BERT, ViT 등)을 사용하는 것이 좋다.
Self-supervised Learning이란?
현재 Transformer 기반의 모델이 큰 성공을 거두고 있는 주된 요인은, scalability, 즉 아주 큰(복잡한) 모델을 통해 다양한 task에서 높은 성능을 보인다(expressive power가 강함)는 것이다.
그런데 앞서 Transformer가 제대로 역량을 발휘하기 위해서는 방대한 데이터가 필수적으로 필요하다고 하였다. 매번 방대한 데이터로 크기가 큰 모델을 학습시키는 것은 비효율적이므로, 거대한 규모의 self-supervised (pre)training을 통해 이 문제를 해결하였다.
일반적인 supervised learning은 특정 task에 대한 성능을 높이는 데에 최적화되어있으나, training data에 대해서 사람이 직접 labeling을 해주어야 한다.
Self-supervised learning은 사람이 아닌 data가 supervision signal을 제공하도록 하는 unsupervised learning의 일종이다. 좀 더 정확히 말하자면, labeling되지 않은 data에 대해서 task를 정하여 data의 representation을 학습(모델 스스로 supervision을 생성하여 supervised 방식으로 학습)하는 방식이다.
이때 정한 task를 pretext task라 한다. Pretext task는 self-supervised 모델이 학습하는 task로, 이를 통해 downstream task에서 활용될 representation을 학습하게 된다.
Pretext Tasks
Pretext task는 크게 다음과 같이 나누어진다.
- Self-prediction : 데이터 샘플 내에서 일부를 masking하고, 그것을 predict(혹은 reconstruct)하는 task
- Autoregressive generation : Sequential data를 다루는 task (ex. GPT)
- Masked generation : Random masking을 통해 일반화 성능을 높이는 task (ex. BERT)
- Innate relationship prediction : Rotation 등의 transformation에도 데이터의 본질은 유지되는 image에서 주로 사용하는 task
- Hybrid self-prediction : 여러 방식의 pretext task를 혼합한 task (ex. DALL-E)
- Contrastive Learning : Embedding space 상에 비슷한 데이터의 feature는 가깝게, 다른 feature는 멀게 embedding하도록 학습하는 task
Pretext task의 좀 더 구체적인 예시를 몇 가지 살펴보자.
Position Prediction
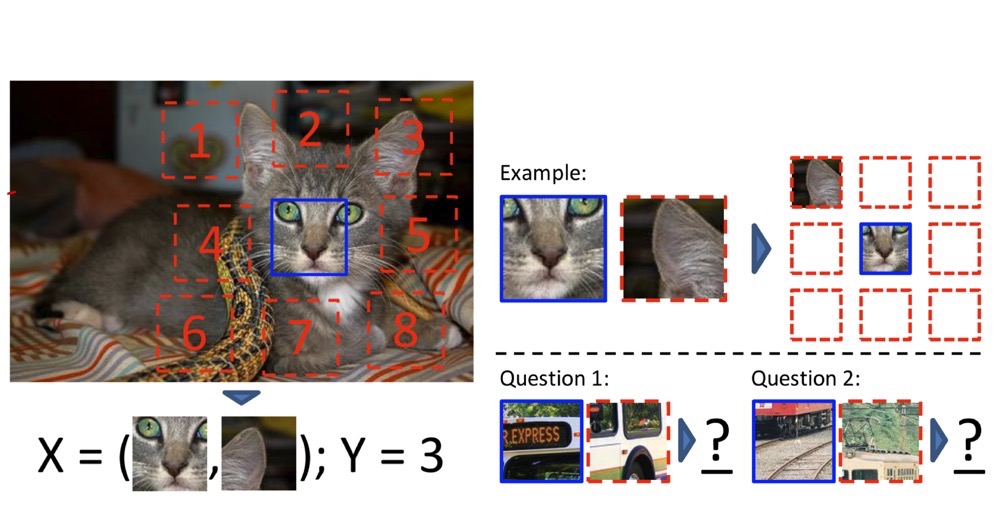
이미지에서 3 * 3 = 9개의 image patch를 가져와 중간 patch와 비교했을 때 다른 1개 patch의 위치가 어디인지 예측하는 pretext task이다.
Rotation Prediction
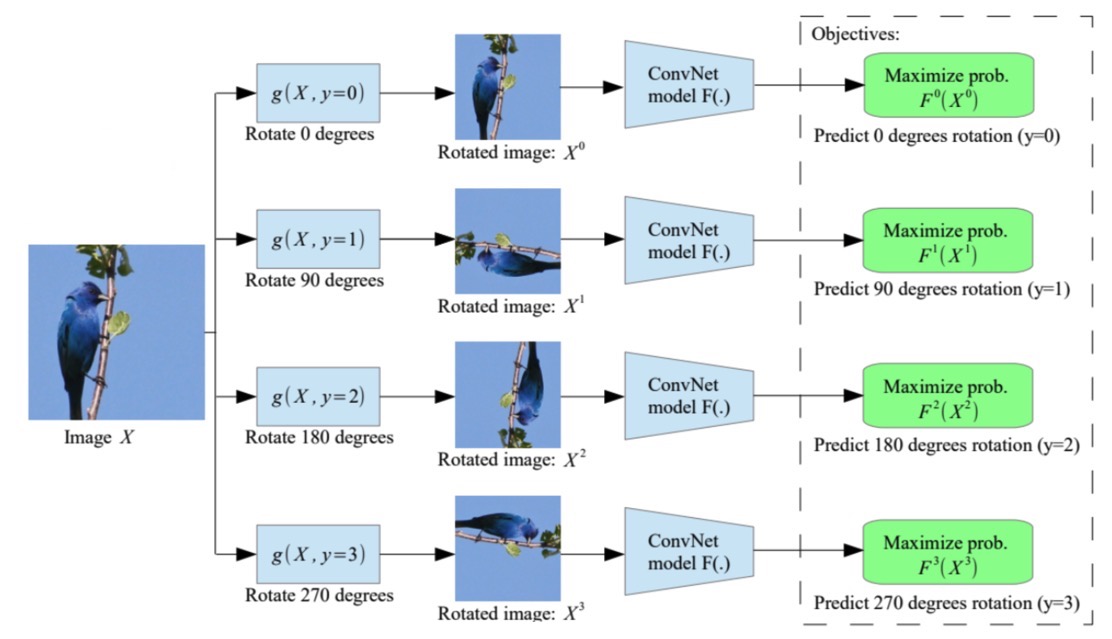
이미지가 \(0^\circ, 90^\circ, 180^\circ, 270^\circ\) 중 얼마나 회전한 이미지인지를 예측(4-class classification)하는 pretext task이다.
Contrastive Learning
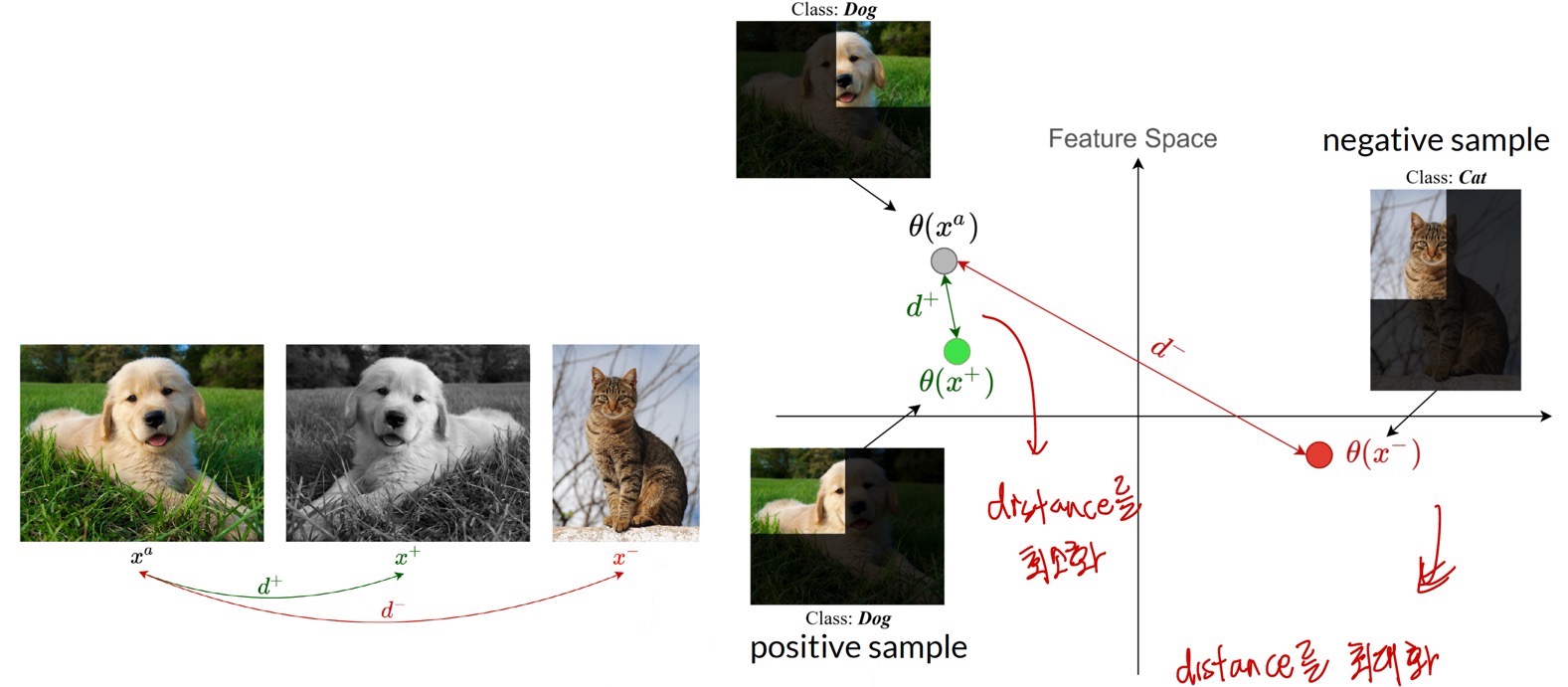
Contrastive learning은 representation space 상에서 어떤 기준 데이터(anchor)와 비슷한 데이터(positive sample)는 가까이, 다른 데이터(negative sample)는 멀리 feature가 존재하도록 학습하는 방법이다.
이외에도 Image domain에서는 colorization, generative modeling 등, video domain에서는 tracking, frame sequence 등, control(RL) domain에서는 goal generation 등의 다양한 pretext task가 존재한다.
Self-supervised learning pipeline
Self-supervised learning의 과정은 다음과 같이 이루어진다.
1. Pre-training
Label이 없는 데이터를 사용하여 연구자가 정한 pretext task로 representation을 학습한다.
이때, 데이터를 적절히 변형하여 이를 supervision으로 사용한다. (label과는 다른 개념이다.)

Fig 6과 같이 pretext task로 rotation prediction task를 사용하였다고 해보자.
2. Transfer Learning
Pre-trained model을 사용하여 downstream task에 대해 (linear) probing 혹은 fine-tuning을 진행한다. 두 방법은 transfer 방식에 따라 나뉜다.
먼저 linear probing이란, 사전 학습된 weight(parameter)는 모두 freeze한 상태로 downstream task에서 feature가 적절한지를 입증(모델을 평가)하는 방법이다.
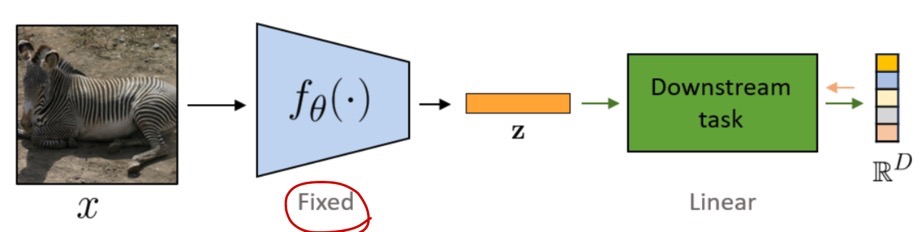
이는 pre-training 과정, 즉 representation 학습이 잘 되었는지를 평가하는 개념이다. weight update를 하지 않으므로 과정이 매우 빠르다.
그리고 fine-tuning이란, 구체적인 downstream task에 pre-training 과정에서 학습한 representation을 활용하고, weight(parameter)를 좀 더 학습시키는 개념이다.
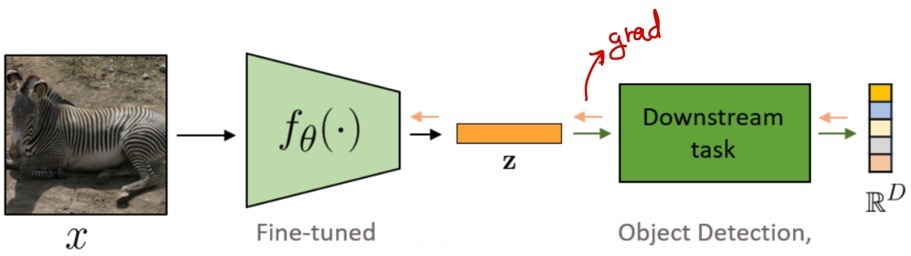
Pretraining for Representation Learning in NLP
실제 NLP domain에서 transformer와 self-supervised learning을 어떻게 활용했는지 알아보자.
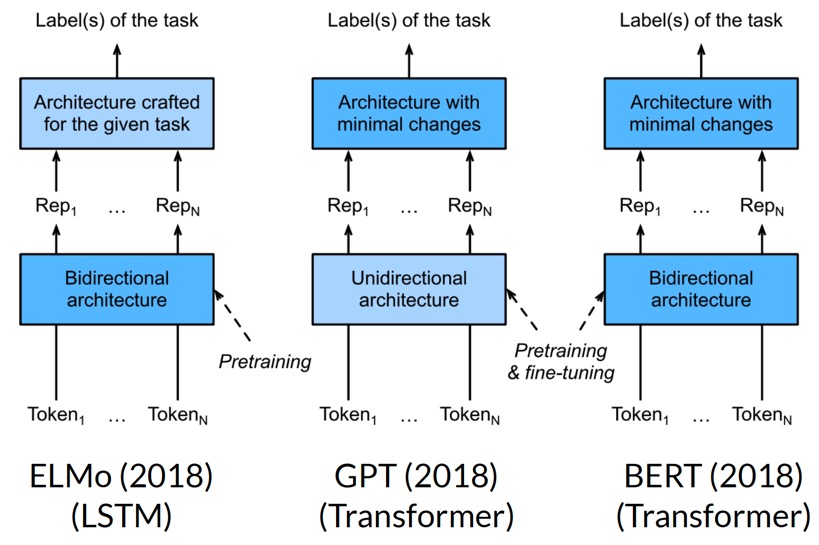
위 Fig 9의 세 모델 모두 NLP에서 매우 좋은 성능을 낸 유명한 모델인데, 구조적인 차이가 있다.
ELMo라는 모델은 bidirectional LSTM모델을 pre-training하였다. 하지만 linear probing을 통해 학습하였으므로 특정 task에만 한정적으로 사용할 수 있는 모델이다. (task-specific architecture)
GPT는 context가 왼쪽에서 오른쪽으로만, 즉 undirectional한 transformer decoder를 pre-training하였다. 하지만, fine-tuning을 통해 task에 상관없이 일반적으로 사용할 수 있는 모델이다. (task-agnostic architecture)
BERT(Bidirectional Encoder Representations from Transformers)는 이름에서도 알 수 있듯, bidirectional RNN의 개념을 사용하여 GPT에 bidirectional 개념을 추가한 모델이다.(Bidirectional의 개념을 사용한 것이지, RNN을 사용한 것은 아님에 주의하자. 대표적인 Transformer 기반 모델이다.) Bidirectional RNN을 사용하면 sequence 양쪽에서의 정보(즉, 과거와 미래의 정보)를 모두 사용할 수 있다.
GPT는 transformer decoder 기반(masked self-attention), BERT는 transformer encoder 기반(self-attention)이다.
BERT도 GPT처럼 fine-tuning을 사용하지만, pre-training 방식, 즉 pretext task가 조금 다르다.
Pre-training of BERT
BERT를 pre-train할 때 MLM과 NSP를 사용한다. 위에서 pretext task의 분류를 설명할 때 잠깐 언급했는데, 조금 더 구체적으로 살펴보자.
Masked Language Modeling (MLM)
Masked language modeling은 context를 양방향으로(bidirectionally) 인코딩하기 위해 사용하는 pretext task이다.
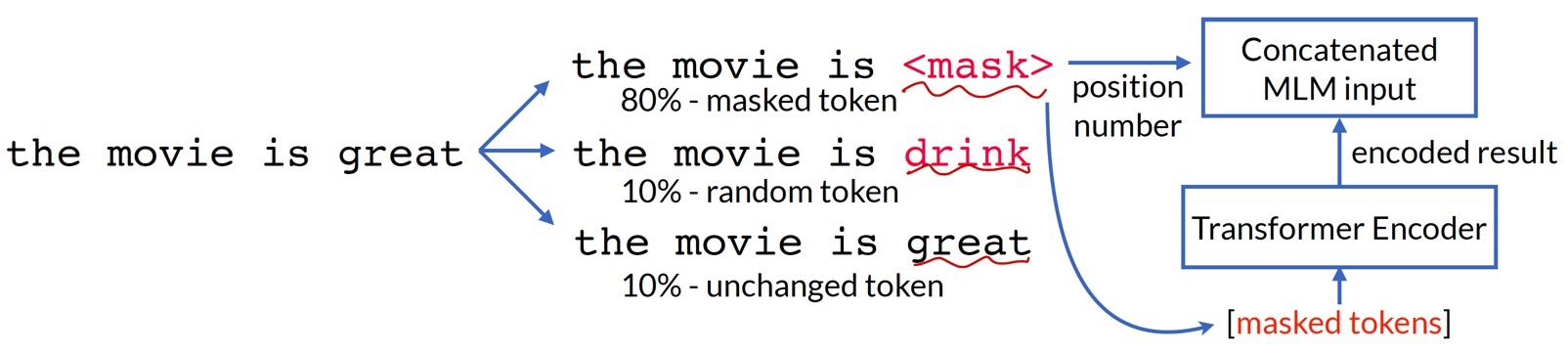
Fig 10과 같이 Transformer encoder에 일부 token을 랜덤하게 마스킹한 데이터를 입력하고, 그 token을 예측하도록 하는 task를 진행한다. 예측할 때 모델이 양방향 context(앞, 뒤 문맥을 모두 활용)를 활용하게 된다.
Distribution-shift를 피하기 위해 noisy label(다른 token)도 사용한다.
MLM은 BERT 모델의 핵심으로, 성능을 끌어올린 주된 성공 요인이다.
Next Sequence Prediction (NSP)
Next sequence prediciton은 문장(sequence)의 논리적 관계(logical relations)를 이해하도록 하기 위한 pretext task이다.
방법은 간단하다. BERT에 text 쌍(2개)을 입력한 후, binary classification을 통해 두 text 간에 연결관계가 있다면 True, 없으면 False를 출력하도록 학습시킨다.
Pre-training 과정에서 MLM에 대한 loss function과 NSP에 대한 loss function을 결합하여 multi-task learning을 진행한다. (실험적으로 downstream task에 따라 둘 다 사용했을 때가 좋은 경우도 있고, MLM만 사용했을 때 좋은 경우도 있다.)
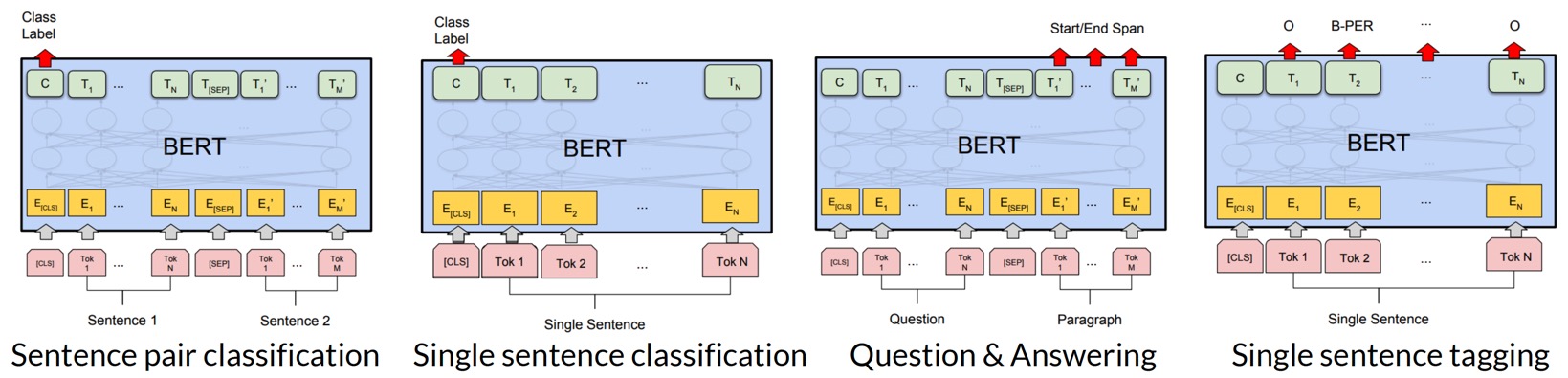
Fine-tuning of BERT
이번에는 fine-tuning 방법을 알아보자. Pre-training 과정에서는 unlabeled data로 학습하지만, fine-tuning 과정에서는 구체적인 downstream task 종류에 따라 적은 양의 labeled data를 활용하여 parameter를 좀 더 tuning한다.
Linear Probing vs Fine-Tuning
Distribution shift가 발생한 경우에는 fine-tuning보다 linear probing이 더 좋다. 우선 distribution shift를 간단히 이해해보자.
흔히 supervised learning에서 input \(X\)와 output \(Y\)가 있을 때, training data는 수학적으로 joint distribution \(P(X, Y)\)로 표현되고, 머신러닝 모델은 수식 \(P(Y|X)\)를 모델링한다.
이때 joint distribution \(P(X, Y)\)는 conditional probability를 사용하여 \(P(Y|X) P(X) \)와 \(P(X|Y) P(Y)\)로 표현 가능하다. 여기서 \(P(X)\)는 input의 probability density, \(P(Y)\)는 output의 probability density를 뜻한다. 이에 따라 data distribution shift의 종류인 Covariate shift, Label shift, Concept drift를 다음과 같이 정의할 수 있다.
- Covariate shift : \(P(X)\)가 바뀌는데도 \(P(Y|X)\)가 그대로인 것
- 즉 input distribution이 바뀌는데도 ML 모델이 그대로인 경우
- 독립변수들의 covariate(공변량)의 분포가 변하는 현상이다.
- Label shift (Prior shift) : \(P(Y)\)가 바뀌는데도 \(P(X|Y)\)는 그대로인 것
- output distribution이 바뀌었는데도 주어진 output을 구할 때의 input distribution이 그대로인 경우
- Covariate shift의 반대 상황으로, 서로 관련이 많음
- Concept drift (Posterior shift) : \(P(Y|X)\)가 바뀌는데도 \(P(X)\)는 그대로인 것
- ML 모델이 바뀌는데도 input distribution이 그대로인 경우
자세한 내용은 링크(영문)를 참조하자.
복잡하게 얘기했는데, 단순히 요약하자면 data distribution shift란 dataset의 distribution이 바뀌어 out-of-distribution error가 생기는 현상을 말한다. 여기서 out-of-distribution 데이터란 학습 데이터의 분포와 다른 분포를 갖는 데이터를 의미한다. 예를 들어, CIFAR-10 데이터(in-distribution)로 학습한 모델의 입장에서 SVHN 데이터는 out-of-distribution이다.

Fine-tuning은 distribution shift에 취약하다. Fig 12와 같이 Linear probing은 weight을 정해두지만, fine-tuning은 weight을 update하므로 feature distortion이 생길 수 있기 때문이다.
기존의 fine-tuning에서는 random하게 head를 initialize하는데, 위와 같은 문제점을 해결하기 위해 linear probing의 head initialization을 사용하고, feature를 refine하는 데 fine-tuning을 진행한다. 이를 LP-FT(Linear Probing then Fine Tuning)라 한다.









최근댓글