목차
해당 카테고리에서는 Deep generative model 강의를 수강하고 주요 내용을 정리해두려 한다. 더 깊은 내용은 Jakub M. Tomczak의 'Deep Generative Modeling' 교재를 참고해보자.
주요 내용은 다음과 같다.
- Likelihood-based models
- Autoregressive generative models
- Flow-based models
- Latent variable models
- Variational learning
- Inference amortization
- Variational Autoencoder
- Implicit generative models
- Two sample tests, embeddings, F-divergences
- Generative Adversarial Networks
- Diffusion Models
Era of Deep Learning
몇년 전 AlphaGo에 세상이 놀라며 AI, 특히 딥러닝에 대한 관심이 아주 커졌다. 게다가 최근에는 ChatGPT가 등장하면서 그 관심과 발전 속도가 더더욱 빨라지고 있다.
딥러닝 모델의 궁극적인 목표는 사람처럼 복잡(complex)하고 체계화되지 않은(unstructured) 입력 데이터를 이해하는 것이다. 대표적인 활용 분야로는 Computer Vision, Natural Language Processing, Computational Speech, Robotics 등이 있다.
그렇다면 Computer Vision 도메인을 예로 들어, '사람처럼 본다'라는 것의 의미는 무엇일까?
사람은 image나 video에서 직관적인 특징을 쉽게 추출한다. 이를 모방하기 위해 20여년 전부터 Caltech-101, Pascal-VOC, LabelMe, ImageNet, COCO 등 다양한 dataset(benchmark)들이 등장했고, computer vision 모델들은 이러한 dataset을 목표로 (알고리즘, gpu 등의 하드웨어, 데이터의 양 등에 힘입어) 성공적인 학습을 했다. 이러한 모델의 대표적인 예로 Mask R-CNN(2017, object detection task)이 있다.
하지만, 해당 dataset의 distribution에 국한된 학습을 한다는 한계를 갖고 있다. Intelligence는 단순히 주어진 dataset에 대한 패턴을 파악하거나 decision boundary를 생성하는 것이 아니라, 우리가 사는 세계를 모델링(modeling the world)는 것이다. 세계를 모델링하기 위해 AI 모델들의 support를 받을 수 있다.
Generative Models
다양한 분야에서의 generative model의 의미를 알아보자.
Generative Modeling in Computer Graphics
Computer Graphics에서 말하는 Generative modeling이란, 컴퓨터로 어떻게 자연스러운 이미지를 생성할 지 모델링하는 과정이다.
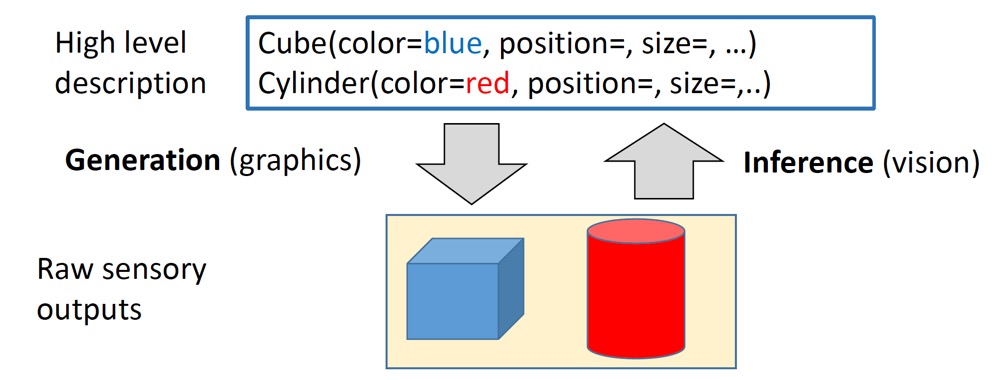
Fig 1에서 볼 수 있듯, high level에서 Cube, Cylinder를 정의해주었을 때 graphic(raw level)으로 생성하는 과정이 generation, graphic을 high level description으로 나타내는 과정이 inference 과정이다.
Deep learning에서 말하는 generative model 또한 이러한 generation과 inference의 과정을 갖고 있다.
Statistical Generative Models
Statistical generative model은 prior를 활용하여 data의 분포(probability distribution \(p(x)\))를 학습한다.
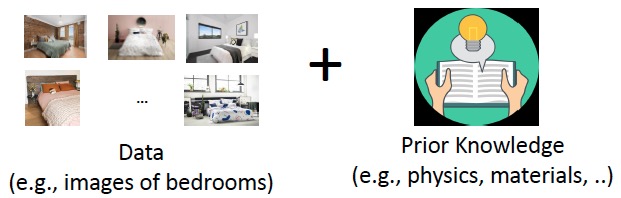
Deep generative model에서도 prior를 활용하지만, deep generative model은 data와 prior 중 data의 비율이 훨씬 높고, statistical generative model에서는 prior의 비율이 훨씬 많은 것으로 이해하면 된다.
Data는 training sample(example)으로 볼 수 있으며, prior knowledge는 Gaussian 등의 parametric form, maximum likelihood 등의 loss function, optimization 알고리즘 등의 형태로 나타난다.

예를 들어, Fig 3에서와 같이 image \(x\)라는 data 하나를 통해 probability distribution \(p(x)\)를 얻고, 이를 여러 data에 대해 반복하여 probability \(p(\mathbf{x})\)를 얻는다. 이러한 \(p(\mathbf{x})\)에서 새로운 image를 샘플링할 수 있기 때문에 'generative'라고 볼 수 있다.
Generative Model이란?
생성 모델(generative model)에 대해 좀 더 자세히 알아보자. Generative model은 주어진 train set에 대해 같은 distribution을 갖는 새로운 sample들을 생성하는 모델을 말한다.
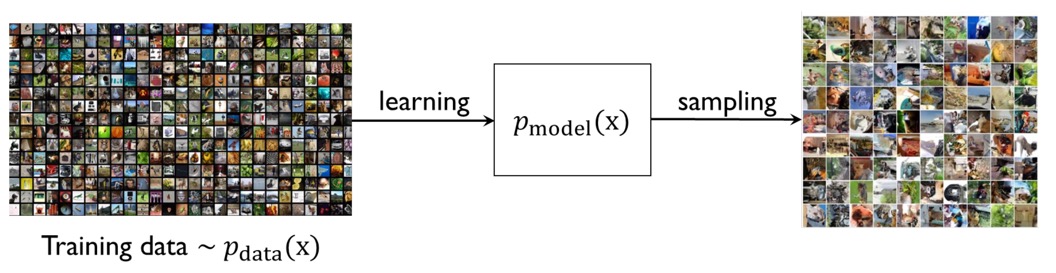
따라서 생성 모델의 목적은 data의 distribution (pdf) \(p_\text{data} (x)\)를 근사하는 \(p_\text{model}(x)\)를 학습하고, \(p_\text{model}(x)\)로부터 새로운 \(x\)를 샘플링하는 것이다.
Representation and Learning
생성모델의 representation과 learning에 대해 알아보자.
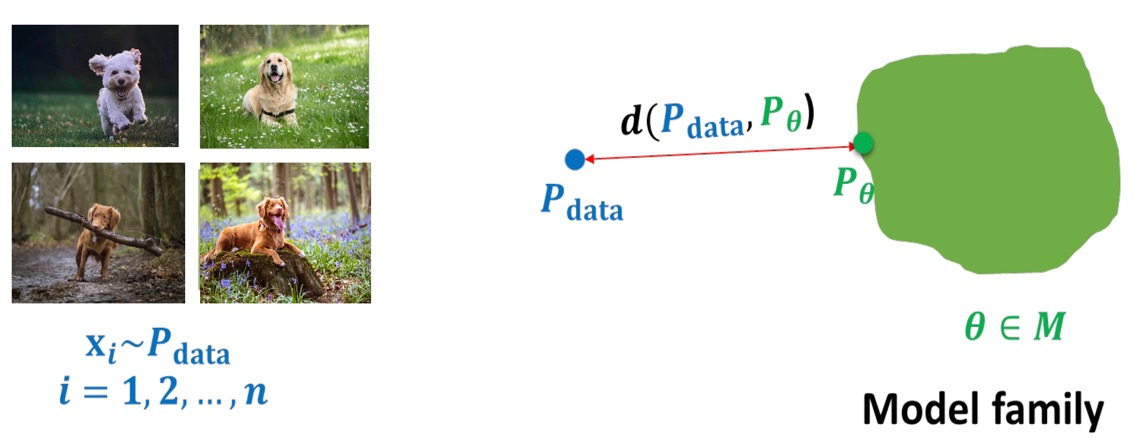
실제 데이터의 분포에서 샘플링한 random variables \(\mathbf{x}_i \sim p_\text{data}\)는 아주 다양할 것이다. Fig 5 왼쪽 사진에서 볼 수 있듯이, '강아지'라는 같은 label의 데이터라 해도 각각의 생김새(종)가 다르며, 배경도 천차만별이다.
학습을 위해서는 이러한 random variable들의 joint distribution을 수학적으로 모델링해야할 것인데, 이 과정을 representation이라 한다. 생성 성능을 높이기 위해서는 compact한 representation이 필요하다.
또한 학습(Learning) 과정은 data distribution \(p_\text{data}\)를 근사하는, 즉 Model familty \(M\)에 속하는 parameter \(\theta\) 중에서 \(p_\text{data}\)와 가장 거리가 가까운 \(\theta\)를 찾는 과정인데, 이를 위해서는 probability distribution을 어떻게 비교할지(어떻게 거리가 가까운지 측정(measure)할지)가 중요하다.
Inference
생성모델로 inference 할 수 있는 것은 다음과 같다.
Density estimation
\( p_\theta(\mathbf{x}) \)
Density estimation이란, datapoint \(\mathbf{x}\)가 주어졌을 때, model에 의해 정해지는 probability를 말한다.
Sampling
\( \mathbf{x}_\text{new} \sim p_\theta(\mathbf{x}) \)
Sampling이란, model의 distribution에서 새로운 datapoint를 생성하는 것을 말한다.
Unsupervised representation learning
Unsupervised representation learning이란, datapoint \(\mathbf{x}\)의 feature representation을 학습하는 것, 즉 data의 high level에서의 특징을 학습한다는 개념이다.
Discriminative vs Generative
머신러닝 모델은 크게 두 종류로 나뉘는데, discriminative model과 generative model이다. 두 모델의 차이점을 살펴보자.
Discriminative Classifiers vs Generative Classifiers
Classification task에 한정하였을 때, classifier로서 두 모델은 각각 discriminative classifier와 generative classifier로 불린다.
Prediction 과정은 수학적으로 입력 데이터 \(X\)와 class label \(Y\)에 대해 posterior \(P(Y|X)\)로 표현한다. (즉, prediction이란 주어진 입력 데이터에 대해 class label이 Y일 확률을 예측하는 것이다.) 두 classifier는 같은 목적으로 활용되지만 그 방법에서 차이를 보인다.
Discriminative classifier는 class를 구분하는 decision boundary를 직접적으로 모델링한다. 즉, \(P(Y|X)\)에 대한 함수를 가정하고, 학습 데이터 \(X\)로부터 직접 \(P(Y|X)\)를 추정한다.
이에 따라 outlier에 강인하지만, misclassification 문제가 존재한다는 단점이 있다.
이에 반해 generative classifier는 데이터셋의 각 class의 분포(패턴)를 모델링한다. 즉, \(P(Y|X)\)가 아니라 \(P(Y)\), \(P(X|Y)\)에 대한 함수를 가정하고, 학습 데이터로부터 우선 \(P(Y)\)와 \(P(X|Y)\)를 추정한 후에 아래와 같이 bayes rule을 활용하여 \(P(Y|X)\)를 계산한다.
\( \text{posterior} = \cfrac{\text{prior} \times \text{likelihood} }{\text{evidence}} \Rightarrow P(Y|X) = \cfrac{P(Y) \cdot P(X|Y)}{P(X)} \)
따라서 새로운 data를 생성할 수 있다는 특징을 갖지만, outlier에는 취약하다는 단점이 존재한다.
특히 generative classifier(naive Bayes model)는 충분히 많은 데이터로 학습을 진행했을 때 asymptotic error(수렴한 error)가 discriminative classifier(logistic regression model)에 비해 크지만( \(\epsilon \left( h_{\text{Gen}, \infty} \right) > \epsilon \left( h_{\text{Dis}, \infty} \right) \) ), 충분한 학습을 위한 학습 데이터 개수가 비교적 적다(각각 \(O(\log n)\), \(O(n)\)). 이론적인 확실한 분석을 알아보려면 AI, 딥러닝 분야의 거장이신 앤드류 응 교수님과 마이클 조던 교수님의 논문 "On Discriminative vs. Generative Classifiers: A comparison of Logistic Regression and Naive Bayes"을 참조하자.
Generative model은 새로운 \(X\)를 생성한다고 했는데, 그 과정은 어떻게 진행되는지 알아보자.

input \(X\)가 주어지지 않은 상황이고, 이때 generative model은 joint distribution \(P(Y,X)\)를 모델링한다.
Conditional distribution을 joint distribution에 대해 써보면,
\(P(Y|X) = \cfrac{P(Y,X)}{P(X)}\)이고, 아래와 같은 그림으로 나타낼 수 있다.
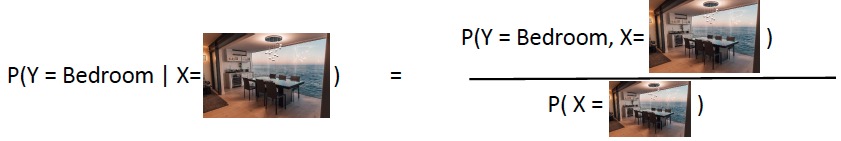
여기서 generation이란, \(P(Y|X)\)와 \(P(Y,X) (=P(Y) \cdot P(X|Y) )\)가 주어졌을 때 \(P(X)\)를 구하는 것으로 이해할 수 있다.
Discriminative model의 경우 \(X\)가 항상 주어지므로, \(P(X)\)를 모델링할 필요가 없다. 따라서 \(X\)의 데이터가 missing된다면(이미지 일부가 훼손되거나 주어지지 않는다면) \(P(Y|X)\)를 모델링할 수 없다.

Fig 8에서 알 수 있듯, 사람은 noise가 조금 추가된 이미지도 고양이임을 쉽게 알아보지만, 엄격한 decision boundary를 갖는 discriminative model의 경우 missclassification의 문제가 생긴다.
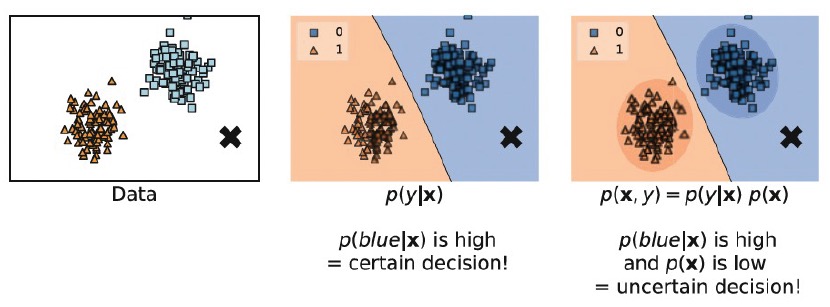
위와 같은 데이터가 주어졌을 때, discriminative model과 generative model이 x표시된 data point가 어디에 속하는지를 판단하는 과정을 살펴보자.
먼저 discriminative model은 decision boundary를 통해 x표시된 지점이 파란 label일 것이라고 확정한다. 하지만, generative model은 x표시된 지점이 blue일 확률이 높지만, 동시에 x의 확률 분포 \(p(x)\)의 값이 낮다는 점도 고려한다. 즉, decision 자체가 확실치 않다(uncertain)는 것을 고려한다는 의미이다.
Conditional Generative Models
Generative model의 이러한 decision making 과정 특성 상, label class를 조건(condition)으로 주었을 때 원하는 데이터를 생성할 수도 있다.
\( P(X|Y) \)
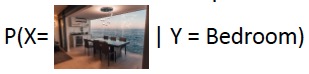
Fig 10은 class label \(Y\)로 'bedroom'이라는 condition을 주어 그에 해당하는 데이터(이미지) \(X\)를 생성하는 예시이다.
\(Y\)에 간단한 class label 대신에 "A black table with 6 chairs" 등의 구체적인 caption(description)을 주어 text-to-image generation을 할 수도 있을 것이다.
Examples of Generative Models
Generation 관련 task에는 도메인에 따라 어떤 것이 있는지 간단하게 살펴보자.
Image Generation


Text Generation

Audio Generation

Image Super Resolution
Super resolution은 이미지의 화질을 좋게 해주는 것으로, 다음과 같은 conditional generative model을 활용한다.
\( P(\text{high resolution image} | \text{low resolution image} ) \)

Imitation Learning
강화학습에도 다음과 같이 conditional generative model이 활용될 수 있다.
\( P( \text{actions} | \text{past observations}) \)








최근댓글