학교에서 수강한 강화학습 관련 과목을 수강하고, 그 내용을 정리해보고자 한다.
실습 내용은 아래 깃허브를 참조하자.
https://github.com/JJukE/ReinforcementLearning
GitHub - JJukE/ReinforcementLearning: Reinforcement Learning Course
Reinforcement Learning Course. Contribute to JJukE/ReinforcementLearning development by creating an account on GitHub.
github.com
목차
1. Machine Learning (ML)
강화학습이 무엇인지에 대해 알아보기 이전에 우선 우리가 알아두어야 할 개념이 있다. 요즘 매우 핫한, 다들 한번정도는 들어봤을 '머신러닝(Machine Learning, ML)'에 대한 개념이다. 한국어로 번역하면 기계학습이라고 말할 수 있다.
우선 머신러닝은 기본적으로 프로그램이 데이터를 통해 자동적으로 배우는 것이다.
따라서 어떠한 프로그램 또는 소프트웨어가 머신러닝 기법으로 학습이 되었다 라는 말은 곧 어떤 문제에 대한 데이터가 존재하는데, 그 데이터로부터 프로그램이 자동적으로 패턴 등을 학습하는 것이다.
여기서 자동적, 즉 Automatic하다는 말은 사람이 직접 데이터의 분포에 대해 모델링을 하는 것이 아니란 뜻이다.
그리고 머신러닝 알고리즘은 example들로부터 일반화함으로써 중요한 task들을 어떻게 수행할지 계획한다.
example은 data, sample과 통용되는 단어이다. 우리가 다루고 싶은 문제에 대한 예시값이 곧 데이터이고, 대부분의 데이터들은 모든 경우에 대한 데이터를 하나도 빠짐없이 모을 수 없는 경우가 많기 때문에 특정 샘플들을 취하므로 샘플이라고 볼 수 있는 것이다.
이때 수집한 샘플 데이터는 학습을 위한 데이터, 즉 training data라고 부른다.
다시말해 Machine Learning Algorithm은 어떤 문제를 해결하기 위해 수집한 데이터를 generalizing, 즉 일반화를 시키고 이를 통해 task를 수행한다. 우리는 모든 데이터에 대해 하나하나 다룰 수 없기 때문에, 전체 데이터에 대한 일부를 sampling한다고 하였다. 결국 우리가 표본으로 수집한 데이터를 최대한 일반화시켜 결국 우리가 수집하지 못한 데이터 혹은 아직 본 적 없는 데이터를 이 알고리즘으로 학습한 모델의 입력으로 넣었을 때 정답 값을 예측할 수 있는 것이다.
따라서 Machine Learning의 목표는 어떤 데이터를 일반화시키는 모델 하나를 만들어 내는것이다.
1) Types of Machine Learning Algorithm
머신러닝 알고리즘은 Supervised Learning, Unsupervised Learning, Reinforcement Learning으로, 크게 세 가지 카테고리로 나뉜다.
Supervised Learning은 우리가 친숙하게 알고 있는 바로 그 머신러닝 알고리즘이다.
y=f(x)에서의 f, 즉 mathematical model을 만드는 과정으로 볼 수 있는데, 이를 위해 데이터셋에 input(x)과 desired output(y)이 포함된다. 정답 값이 포함된 output이 주어진다는 점이 중요하다.
이에 반해 Unsupervised Learning은 어떠한 모델을 만들지만, 데이터셋에 정답 값이 포함되어있지 않다는 점이 다르다.
따라서 Unsupervised Learning은 mathematical model을 만들기 보다는 데이터의 structure를 찾는 과정이다. 여기서 structure란 data point들의 grouping, clustering 등을 말한다.
예를 들어, 우리가 바닷가에서 가져온 모래와 자갈이 섞인 흙 한 무더기를 갖고 있다고 생각해보자.
Supervised Learning에서는 '모래알은 지름이 A 이하이고, 자갈은 지름이 A 초과이다' 라는 등의 기준으로 이미 모든 알갱이들이 모래인지, 자갈인지 판별이 된 정답값이 존재하는 데이터가 주어져 있는 상태이다. 그러면 머신러닝 알고리즘은 데이터들의 패턴(모래와 자갈을 구분하는 기준 지름)을 학습하게 되고, 바닷가에서 다른 흙을 주워 왔을 때에도 그 기준을 적용하여 모래인지, 자갈인지 예측하는 모델을 만들어낼 수 있다.
똑같은 문제에 Unsupervised Learning 알고리즘을 적용한다면, 각 알갱이들이 모래인지, 자갈인지 모르는 상태에서 그 알갱이들을 특정 기준으로 Grouping 혹은 Clustering할 수 있다. 특정 크기의 구멍을 갖는 채가 있다고 하면, 그 채에 걸러지는 것은 모래, 걸러지지 않는 것은 자갈과 같이 두 가지 그룹으로 나눌 수 있는 것이다. 한마디로 정답값이 없는 input이 주어졌을 때, 그 데이터의 structure를 찾아내는 것이다.
이에 비해 Reinforcement Learning(강화학습)은 전혀 다른 개념이다. 사전적 개념을 살펴보면, 'How agents ought to take actions in an environment so as to maximize some notion of cumulative reward.'와 같다. 위 두가지 개념과 가장 두드러지게 다른 점은 'data'라는 말이 없다는 것이다.
그럼 대체 어떻게, 무엇을 학습을 한다는 걸까?
강화학습에서는 Agent가 특정 환경(Environment)에서 Action을 취한다. Agent가 취할 수 있는 Action의 종류는 많은데, 그 중에서 Reward를 최대로 받을 수 있는 Action을 함으로써 학습을 하게 되는 것이다.
데이터가 없음에도 불구하고, 강화학습 또한 머신러닝 알고리즘이다. 왜냐하면 특정 소프트웨어 또는 하드웨어인 Agent가 학습 알고리즘이 진행됨에 따라 지능적으로 행동을 하게 되기 때문이다.
아래 소분류에서 각각에 대한 대표적인 예시들로 간단히 이해해보자.
(1) Supervised Learning
Supervised Learning 내에도 수많은 기법들이 있다. 그중에서도 가장 유명한 Regression과 Classification에 대해 간단하게 소개한다.

어떤 지역의 집값을 예측하고 싶다. 이를 우해 우리는 위 사진에서 X로 표현된 data들을 모았다. 여기서 Input은 size, Output은 Price이다. 이에 따라 y=f(x)라는 수학적 모델을 만들고 싶은데, 각 데이터들의 실제 값들이 주어져있다.
수학적 모델을 만드는 목표는 무엇일까?
바로 새로운(본 적 없는) 데이터의 집값을 예측해보고 싶은 것이다.
그러기 위해서는 현재 데이터들의 '경향성'을 파악해야 한다. 이를 위해 위 f(x)식을 일차식으로 표현하여 위 사진의 blue line을 생성할 수도 있고, f(x)식을 이차식으로 표현하여 위 사진의 red line을 생성할 수도 있다. 여러 line들 중 가장 전체 데이터를 일반화할 수 있는 line을 모델로 선택해야 한다.
위에서 주어진 조건들로는 무엇이 더 잘맞는지는 아직 알 수 없다. 왜냐하면 새로운 입력 data가 주어지지 않아, 모델을 평가할 수 없기 때문이다.
여기서 중요한 점은, Supervised Learning이기 때문에 집의 size라는 input값과 집값이라는 desired output 값이 모두 주어져있다는 것이다.
다음으로 Classification에 대해 알아보자.
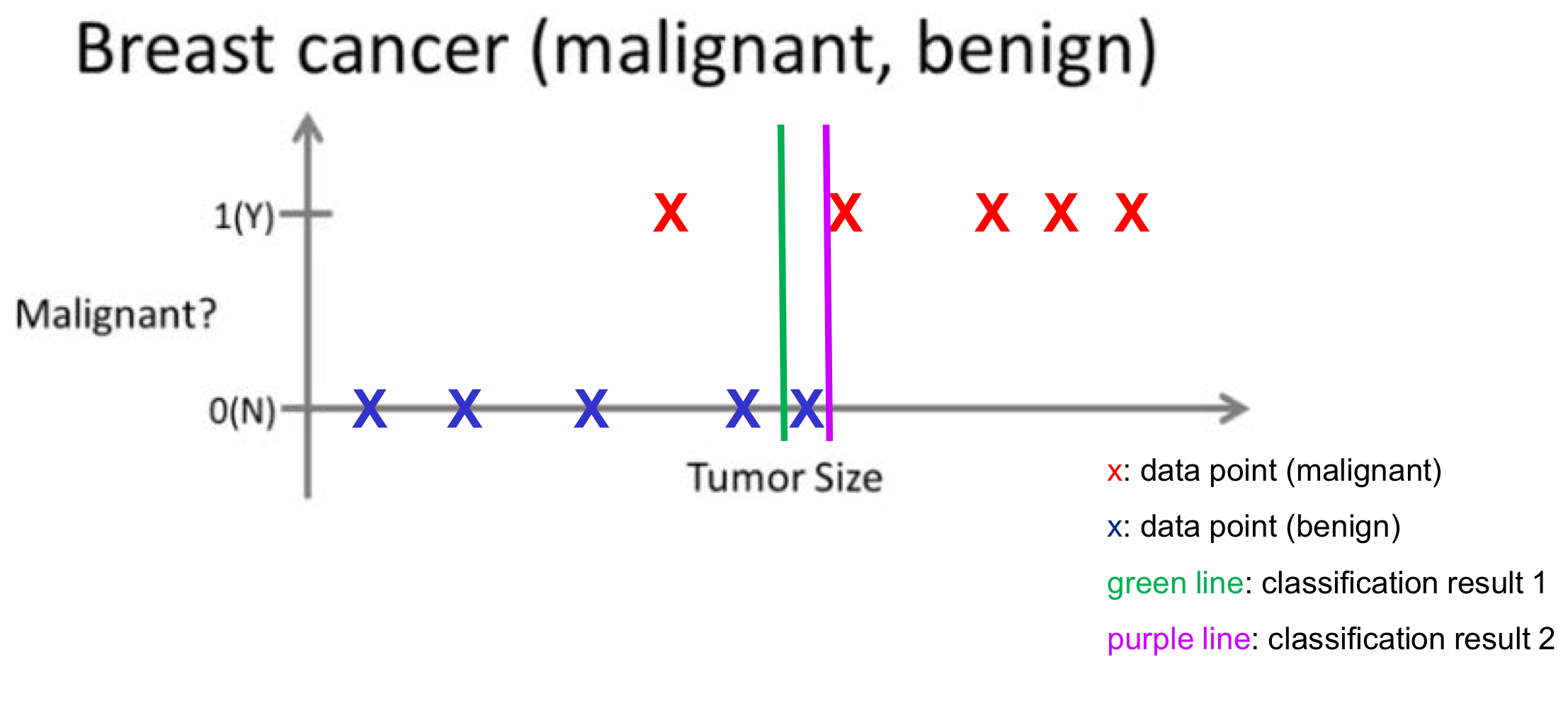
Classification은 데이터 포인트들을 분류하는 것이다. Regression에서는 새로운 입력이 들어가면 그에 따른 실수값(real value)이 결과값으로 도출되지만, Classification에서는 새로운 입력이 들어가면 해당 데이터가 어떤 Class에 속하는지, 즉 클래스의 종류가 결과값으로 출력된다. 한마디로 Regression은 Continuous Value가, Classification은 Descret Value가 나오게 된다.
위 예시에서는 종양의 size에 따라 그 종양이 악성(maligant) 종양인지, 양성(benign) 종양인지 판단하는 모델을 만들어 보려고 한다. Regression에서의 예시와 마찬가지로 주어진 데이터 포인트들은 각각이 양성인지 악성인지 정답값이 주어져 있다.
따라서 종양의 size의 특정 값을 기준으로 green line, purple line 등 수많은 판단 기준이 생길 수 있다. 그 중에서 일반화 성능이 가장 좋은 모델을 선택해야 할 것이다.
참고로 위 예시에서는 판단 기준이, 즉 input value의 종류가 Tumor Size 하나이다. 따라서 Classification Boundary(그림의 line)가 매우 단순하고, 오류도 클 것이다. 하지만 변수들이 늘어남에 따라 계산량은 복잡하지만 더 정확한 Classification을 할 수 있는 Boundary를 생성해 낼 것이다.
그럼 Supervised Learning에 비교해서 우리가 배우게 될 Reinforcement Learning는 어떤 차이점을 갖고 있을까?
먼저 Supervised Learning은 Training Data로부터 Machine이 배우는 것이며, 이 Data들은 모두 정답 값을 갖고 있다. 이를 '레이블 된(labeled) 데이터셋'이라 한다.
그리고 Supervised Learning의 목적은 Extrapolate와 Generalize이다. 즉, 아직 보지 못한 새로운 데이터를 잘 예측하는 모델을 만드는 것이다.
예를 들어, Supervised Learning은 강아지에게 캐치볼을 가르칠 때 '왼쪽으로 돌아서 두 발 앞으로 갔다가, 오른쪽으로 다섯 발 가서 공을 물고 ...' 등의 명시적인 데이터로 가르쳐야 한다.
하지만 Reinforcement Learning은 강아지가 공을 잘 가져올 경우 간식을 주는 등의 보상을 주어서 그 행동을 하도록 유도한다.
(2) Unsupervised Learning
다음으로 Unsupervised Learning의 대표적인 기법인 Clustering에 대해 간단히 살펴보자.

Supervised Learning에서와는 달리, Input은 존재하지만 desired output이 없다. Supervised Learning의 Classification 예시에서는 데이터의 색깔로 각 데이터가 어느 그룹에 속하는지에 대한 정해진 정답이 존재했었다. 하지만 Unsupervised Learning에서는 data가 단순히 점으로 표현되어, 기준인 x1, x2에 따라 모델 설계자가 직접 Cluster의 개수(Group의 개수)를 설정하고, 알고리즘을 작성하여 데이터를 분류해 주어야 한다.
클러스터의 개수 또한 정해진 바가 없다.
위 예시에서는 누가봐도 간단히 Cluster의 개수를 2개로 만들면 되겠다는 직관적인 판단을 할 수 있겠지만, 실제 상황에서 Unspervised Learning을 사용할 때에는 Application 종류에 따라 cluster가 존재하거나 loss를 찾아보며 elbow point를 찾아 그를 통해 cluster 개수를 정하는 등의 방법을 통해 적절한 cluster 개수를 알아볼 수 있다.
그렇다면 Unsupervised Learning과 Reinforcement Learning의 차이점을 간단히 살펴보자.
Unsupervised Learning 또한 데이터를 통해 모델을 학습시킨다. 하지만 Supervised Learning과는 달리 정답 값, 즉 데이터의 output이 존재하지는 않는다.
그리고 학습의 목적은 입력(input)에 대한 숨은 패턴을 찾아 모델이 학습하도록 하는 것이다. 이때문에 마치 강화학습은 Unsupervised Learning의 일종이라고 생각할 수 있지만, 개념이 완전 다르다.
Unsupervised Learning은 데이터들의 숨은 패턴, 즉 구조를 학습하는 것이고, RL은 보상을 최대화하도록 모델을 학습시키는 것이다.
영화를 추천한다고 생각해보자.
Unsupervised Learning의 경우, 어떤 사람이 이전에 봤던 영화들의 특징들을 분석하여 비슷한 특징을 가진 다른 영화들을 추천하는 방식을 사용한다.
하지만 Reinforce Learning은 어떤 사람에게 끊임없이 영화에 대한 피드백을 받고, 그 피드백(별점 등)을 기준으로 그 사람의 preference를 학습한다. 결론적으로 feedback이 좋아지도록(좋은 피드백이 결국 보상이 된다.) preference에 입각하여 새로운 영화를 추천한다.
2. Reinforcement Learning (RL)
아까도 언급했듯이, 우리의 주제인 강화학습은 Machine Learning에 포함되지만 학습할 data가 없다는 특징을 갖는다.
예를 들어, 앞서 간단하게 예를 들었듯이, 강아지에게 캐치볼을 가르친다고 생각해보자.
강아지는 인간의 말을 이해할 수 없기 때문에, 우리는 강아지에게 캐치볼에 대해 명시적으로(explicitly), 즉 말로 명확하게 설명을 해줄 수가 없다.
대신에, 공을 던지고, 강아지(Agent)가 공을 가져온다면(Action) 그 때마다 쿠키(Positive Reward)를 줄 수 있다.
그리고 공을 가져오지 않거나 실패한다면 쿠키를 주지 않을 것(Negative Reward)이다.
이러한 과정을 반복하다보면, 강아지는 자연스럽게 쿠키를 많이 받기 위해(to Maximize Reward) 공을 물어와야 한다는 것을 학습할 것이다. 이를 강화학습, Reinforcement Learning, RL이라 한다.
전체 프로세스에 데이터라는 말이 없다. 대신에 강아지, 공을 가져오는 액션, 쿠키 등의 구성 요소가 있다.
RL 환경에서는 agent를 직접 학습시키지 않는다. 대신 agent가 특정 action을 취하였을 때 reward를 maximize하도록, error를 minimize하도록 학습시킨다. 그리고 학습 시 action에 따른 reward를 주는 행위를 반복하므로 RL은 trial and error process라 볼 수 있다.
또한 모든 step마다 reward를 주지는 않아야 하는 경우도 있다. 예를 들어 강아지가 최종적으로 공을 물어 왔을 때에 쿠키를 주는 것이지, 공에 가까운 방향으로 갈 때마다 쿠키를 주지는 않는다. 이를 'Delayed Rewards'라고 한다. 다시말해 reward는 한 task가 완료된 후에만 주어지는 상황을 말한다.
물론 반대로 모든 step에서 reward를 주는 경우도 application에 따라 존재할 수 있다.
1) Robot Example
좀 더 상세한 예시를 들어보자.

산에 부딪히지 않고 로봇(Agent)이 움직이도록 학습시키고자 한다. 로봇은 주변 환경에 대해 모르는 상태이다.
이를 위해 로봇이 산을 치거나 산에 막히면(Action) -10 Point를 준다(Negative Reward).
그리고 로봇이 산의 반대방향으로 움직이게 되면(Action) +20 Point를 준다(Positive Reward).
이 과정을 반복하면 로봇은 '아! 왼쪽 방향으로 가는 것보다 오른쪽 방향으로 가는 것이 reward를 더 많이 받는구나!'라는 것을 학습하게 되어 Reward를 maximize하기 위해 산의 반대방향으로 가게 될 것이다. 이 과정이 바로 맞는 방향으로 가게 되는 행동이 '강화'되는 학습의 과정이다.
2) 강화학습의 두 가지 전략 (Strategies)
강화학습에서 Agent가 취할 수 있는 두 가지 전략이 있다.
하나는 Explore로, 더 좋은 reward가 있을 수도 있으므로 새로운 도전을 해보는 것이다.
또 하나는 Exploit로, agent가 이미 good reward를 받을 수 있다고 학습한 행동을 계속 하는 것이다.
위 예시 문제를 좀 더 확장시켜서, 로봇이 이번에는 화면을 뚫는 방향, 화면에서 나오는 방향으로도 움직일 수 있다고 가정해 보자. 그리고 목적지가 화면에서 나오는 방향에 존재한다고 생각해보자. 왼쪽, 오른쪽에 대한 reward는 어느정도 학습을 했는데, 이제 로봇은 고민을 하게 된다.
여기서 오른쪽 방향으로 움직이는 Strategy가 Exploit이다. 이미 오른쪽으로 가면 +20 Point를 받는 것을 알고 있으므로, 그쪽을 계속해서 갈 수 있을 것이다.
그런데 로봇이 화면에서 나오는 방향으로 움직이게 되면 +50 Point를 받는다. Exploit 전략만 계속해서 사용하게 되면 이 사실을 모르겠지만, Action을 취하기 전에 로봇은 항상 Explore 전략도 고민하게 된다. 이전과 다른 Action을 탐험해보며 그 행동이 더 좋은 Reward를 주는지 알아보는 과정이다. 하지만 잘못 Explore를 했다가 화면을 뚫는 방향으로 움직이게 되면 -30 Point를 받게 된다.
따라서 로봇은 매 순간 두 가지 전략 중 하나를 고민하며, reward를 maximize하고자 한다. 이때 Explore의 비율이 지나치게 높다면 좋은 reward를 받을 확률도 있지만, 나쁜 reward를 받을 확률 또한 높아진다. 모든 상황이 항상 좋은 reward만 가질 것이라는 보장이 없기 때문이다.
반대로 Exploit의 비율이 지나치게 높다면 적당히 좋은 reward를 받을 수는 있겠지만, 훨씬 좋은 reward를 받을 기회를 놓치게 된다.
Explore과 Exploit은 항상 Trade-off 관계를 가지며, 따라서 적절한 비율을 선택해야 한다.
3) RL Algorithm
강화학습 알고리즘은 보편적으로 다음과 같은 과정을 따른다
- Agent가 Action을 수행하며 특정 환경(Environment)과 상호작용한다.
- Agent가 한 State에서 다른 State로 움직인다.
- Action에 따른 Reward를 받는다.
- Reward에 따라 Agent는 좋은 Action과 나쁜 Action을 구분하고 이해한다.
- Positive Reward를 받았다면(Good Action이었다면), Agent는 그 Action을 수행하기를 원할 것이고(Exploitation), 아니면 Agent는 다른 Action을 수행(Exploration)하며 Positive Reward를 받을 수 있도록 할 것이다.
3. Elements of Reinforcement Learning
다음으로 강화학습을 구성하는 주요 요소들은 어떤 것이 있는지 좀 더 자세히 알아보자
1) Agent
먼저, 학습의 주체인 Agent에 대해 알아보자.
Agent란, Reinforcement Learning에서 지능적인 결정을 내리고 학습하는 Software Program이다.
Agent는 주어진 환경과 상호작용하면서 Action을 취하고, 그에 따른 보상(Reward)을 받는다.
2) Policy
Policy가 어떤 것인지 알아보자.
Policy는 주어진 환경 내에서 Agent의 행동을 정의해준다. 즉, Agent가 어떤 Action을 수행할지 Policy에 따라 결정되는 것이다.
예를 들어, 어떤 Agent가 사무실에서 집까지 가고싶어 한다고 하자. 그렇다면 집까지 가는 길이 무수히 많을텐데, 여기서의 '길', 즉 route가 Policy에 해당한다. 집까지 간다는 목적을 달성하기 위해 A길, B길, C길이 있다면 A길을 선택한다는 Policy, B길을 선택한다는 Policy, C길을 선택한다는 Policy 중 하나를 선택하여 Action을 취하는 것이기 때문이다.
Policy는 lookup table이나 search tree의 형태로 나타나며, 표시는 'π'로 한다.
3) Value Function
Value Function에서 Value는 곧 Reward를 의미한다.
따라서 Value Function이란, 특정 State에 존재하는 것이 Agent에게 얼마나 좋은지를 나타내며, Agent가 어떤 Policy에 따라 Action을 취함으로써 얻는 총 Reward와 같다.
따라서 Policy마다 각각의 Value Function이 존재하게 된다.
Value Function은 'v(s)'로 나타내며, 여기서 s는 State를 말한다.
또한 Optimal Value Function이란, 다른 Value Function들에 비해 가장 좋은 Value를 갖는 것을 말한다.
그리고 Optimal Policy는 Optimal Value Function을 갖는 Policy를 의미한다.
따라서, 강화학습의 최종 목표가 Reward를 최대화하는 것이므로, 이는 곧 Optimal Policy를 찾는 것과 같은 의미이다.
4) Model
Model이란, Agent가 인식하는 환경에 대한 표현이다.
RL은 Model의 유무에 따라 'Model-based Learning', 'Model-free Learning'으로 나뉘는데,
Model-based Learning에서는 Agent가 Model을 사용하여 Agent의 행동에 따라 State가 어떻게 바뀔지 알 수 있는 것이다.
이에 비해 Model-free Learning에서는 Agent가 모델 없이, 그저 Trial-and-error로 시도를 반복하면서 경험에만 의존하여 학습한다.
예를 들어, 우리는 처음 가는 곳에 갈 때, 지도를 활용하여 특정 위치에 더 빨리 가는 방법을 고안한다. (Model-based Learning) 여기서 지도가 바로 환경에 대한 표현으로 생각할 수 있다.
하지만 만약 지도가 전혀 없다면, 우리는 그곳에 빠르게 가는 길을 찾으려면 여러 번 시도를 거쳐 다른 길들을 다녀보면서 직접 학습해야 할 것이다.
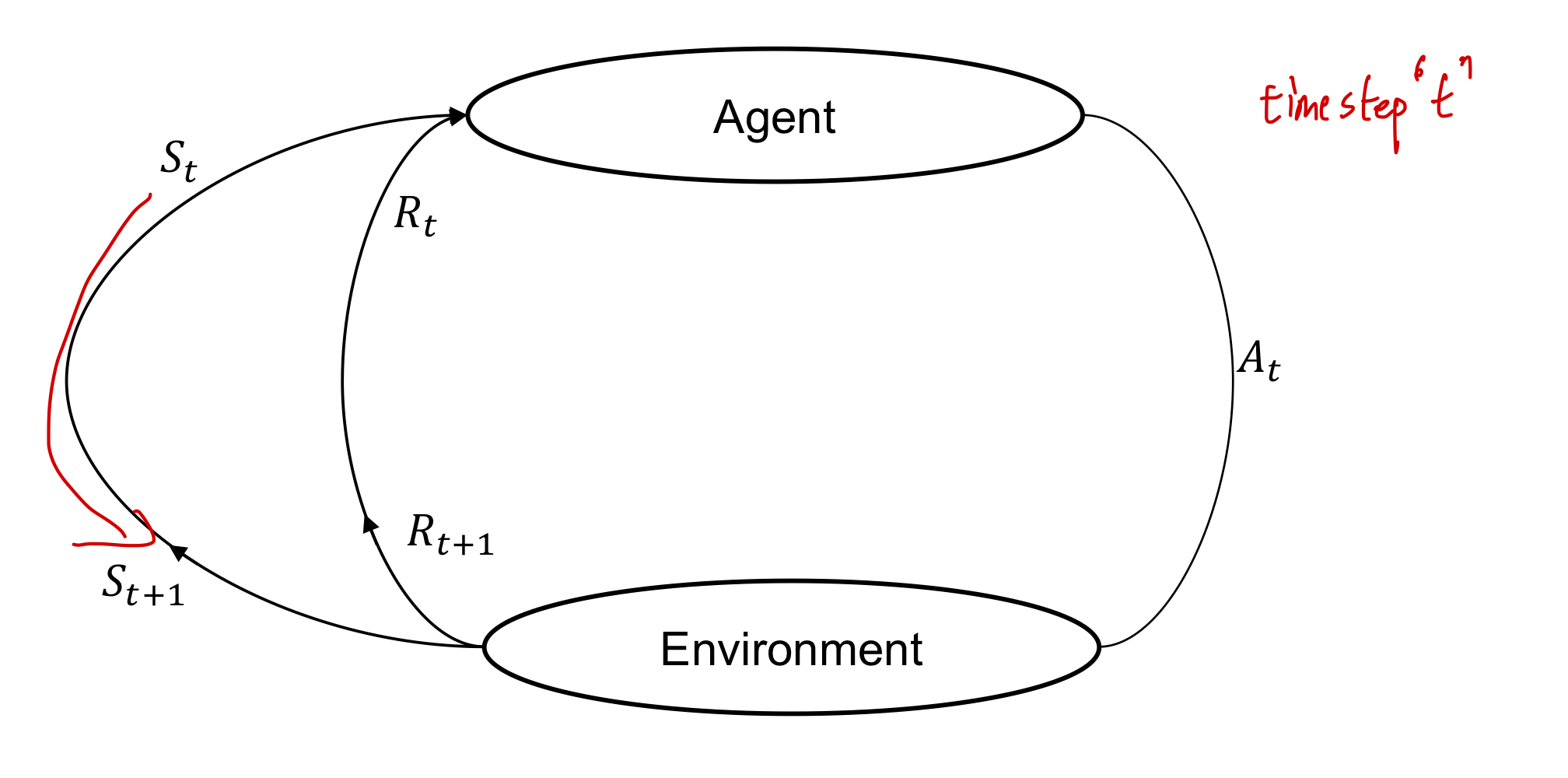
5) Agent와 Environment간의 Interface
Agent는 time step $t$에서 Action $A_t$를 함으로써 State $S_t$에서 다른 State $S_{t+1}$로 넘어가게 된다.
이에 따라 Agent는 Reward $R$을 받게 된다.
예를 들어, 아래와 같은 미로찾기 게임을 생각해보면, 각 요소들은 다음과 같이 주어질 것이다.

- Agent : 미로를 탐험하게 될 점
- Environment : 미로
- State : 점이 현재 존재하는 위치(position)
- Reward : 아무런 벽에 막히지 않으면 Positive Reward, 벽에 막혀 목적지에 도달할 수 없게 되면 Negative Reward
- Goal : 목적지를 빠져나오는 것








최근댓글