<이론> 1. Introduction


<실습>
1. Naive Bayes Classifier
- 필요한 라이브러리 불러오기
|
import pandas as pd
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
|
cs |
- GaussianNB : Gaussian Naive Bayes Classifier
- Data 불러오기
|
# data 불러오기
data = pd.read_csv("credit_data.csv")
features = data[["income", "age", "loan"]]
target = data.default
print(features.corr())
feature_train, feature_test, target_train, target_test = train_test_split(features, target, test_size=0.3)
model = GaussianNB()
|
cs |
- print(features.corr())의 결과

- 서로 다른 feature 사이에는 연관이 모두 있음. (0이 아니므로)
- 연관이 있지만 (독립이 아니지만) Naive Bayes Classifier 잘 동작함.
- Fit the Model
|
model = GaussianNB()
fittedModel = model.fit(feature_train, target_train)
predictions = fittedModel.predict(feature_test)
print(confusion_matrix(target_test, predictions))
print(accuracy_score(target_test, predictions))
|
cs |
- print(confusion_matrix(target_test, predictions)의 결과

- print(accuracy_score(target_test, predictions)의 결과 : 정확도 93%

<이론> 2. Text Clustering

<실습> 2. Text Clustering
|
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(["I like machine learning and clustering algorithms",
"Apples, oranges and any kind of fruits are healthy",
"Is it feasible with machine learning algorithm?",
"My family is happy because of the healthy fruits"])
print(tfidf.A)
#print((tfidf*tfidf.T).A) # similarity matrix
|
cs |
- TfidfVectorizer() : transformation 실행
- 4개의 문장 (documents) : 첫 번째와 세 번째는 machine learning 관련, 두 번째와 네 번째는 health 관련 문장
- print(tfidf.A)의 결과

- 4개의 문장 각각 하나의 matrix로 표현됨
- 판단하기 복잡 -> similarity matrix 실행
- print((tfidf*tfidf.T).A)의 결과
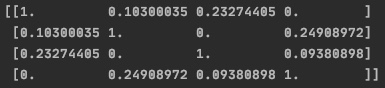
- 'a행 b열 요소 = a번째 문장과 b번째 문장의 similarity'
- 첫 번째 문장은 세 번째와, 두 번째 문장은 네 번째와 비슷함을 알 수 있음
<실습> 2. Text Clustering - 2) Clustering News
- 필요한 라이브러리
|
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
|
cs |
- 20newsgroups : sklearn에서 제공하는 20개의 다른 주제를 갖는 뉴스 데이터셋
http://qwone.com/~jason/20Newsgroups/
Home Page for 20 Newsgroups Data Set
20 Newsgroups The 20 Newsgroups data set The 20 Newsgroups data set is a collection of approximately 20,000 newsgroup documents, partitioned (nearly) evenly across 20 different newsgroups. To the best of my knowledge, it was originally collected by Ken Lan
qwone.com
- CountVectorizer, TfidfTransformer : 이론 필기 참고!
- data training
|
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
training_data = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, random_state=42)
print("\n".join(training_data.data[10].split("\n")[:30])) # 10 번째 data, 30줄까지만
print("Target is:", training_data.target_names[training_data.target[10]]) # 10 번째 data의 주제
|
cs |
- categories : 4개 주제만 가져옴
- shuffle : 섞어서 가져옴
- random_state : value값은 아무거나
- print 내용 : 10 번째 data를 30줄까지 불러옴 / 10 번째 data의 주제를 보여줌
- print 결과
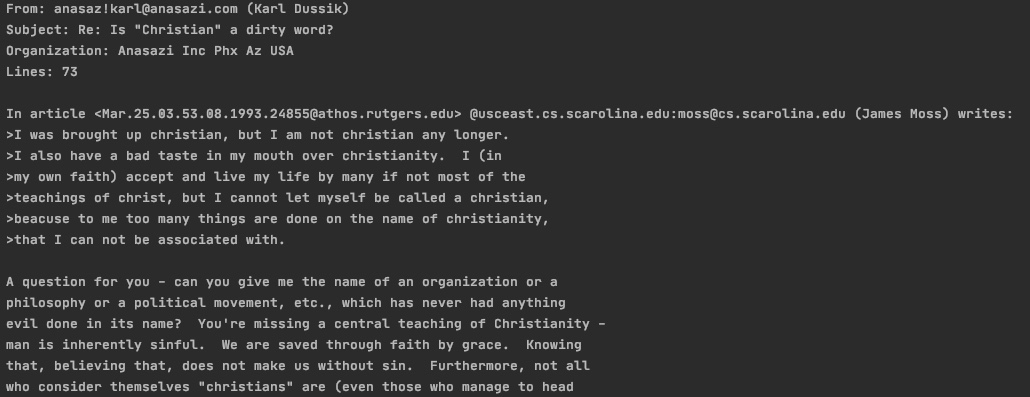

- 10 번째 data의 주제는 'soc.religion.christian' !!
- Counting, Transforming into tf-idf
|
# Counting the word occurrences
count_vector = CountVectorizer()
x_train_counts = count_vector.fit_transform(training_data.data)
# Transforming the word occurences into tf-idf
# TfidfVectorizer = CountVectorizer + TfidfTransformer
tfidf_transformer = TfidfTransformer()
x_train_tfidf = tfidf_transformer.fit_transform(x_train_counts)
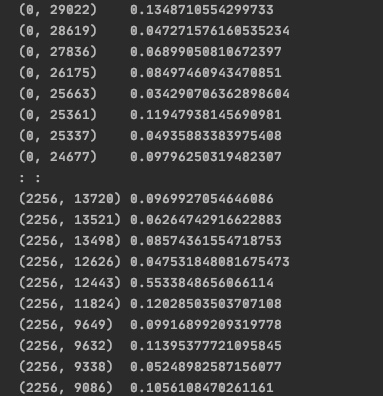
print(x_train_tfidf)
|
cs |
- x_train_counts : training_data를 count한 것
- x_train_tfidf : x_train_counts를 tf-idftransform한 것
- print의 결과 : tf-idf values
- Multinomial Gaussian NB Classifier
|
# Multinomial Gaussian NB Classifier
model = MultinomialNB().fit(x_train_tfidf, training_data.target)
# test
new = ['My favourite topic has something to do with quantum physics and quantum mechanics',
'This has nothing to do with church or religion',
'Software engineering is getting hotter and hotter']
x_new_counts = count_vector.transform(new)
x_new_tfidf = tfidf_transformer.transform(x_new_counts)
predicted = model.predict(x_new_tfidf)
print(predicted)
# 숫자로 분류된 것을 문자로 표현해줌
for doc, category in zip(new, predicted):
print('%r -----------> %s' % (doc, training_data.target_names[category]))
|
cs |
- model을 통해 학습시킨 후, new로 test함
- 결과

- 첫 번째 문장은 'physics'와 관련된 문장인데, 애초에 위의 'categories'에서 physics가 없었음.
- NB Classifier의 문제점 : Supervised Learning, 즉 카테고리를 분류해주지 않으면 엉뚱한 결과가 나옴
- K-means Clustering 을 사용하면 더 powerful한 text clustering 가능해짐.
- 두 번째 문장, 세 번째 문장은 잘 분류되었음
- 위의 [0 3 1]은 print(predicted)의 결과이고, 이를 아래와 같이 직관적으로 보기 위해 for문 사용하였음








최근댓글