300x250
목차
3. 리스트(List) 자료형
1) 리스트는 어떻게 만들고 사용할까?
- 대괄호로 감싸주고, 각 요소값은 쉼표로 구분해준다

- 리스트는 비어있을 수도 있고, 숫자, 문자열, 다른 리스트를 포함할 수도 있다.
- 앞서 얘기했던 문자열의 인덱싱, 슬라이싱과 같은 방법으로 인덱싱, 슬라이싱 할 수 있다.


- 리스트 컴프리헨션 : 리스트를 초기화할 때, 대괄호 안에 조건문이나 반복문 등을 적용하여 리스트를 초기화하는 방법을 말한다.
# 0부터 9까지의 수를 포함하는 리스트 초기화
array = [i for i in range(10)]
print(array)
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [i for i in range(20) if i % 2 == 1]
# 1부터 9까지의 수들의 제곱 값을 포함하는 리스트
array = [i * i for i in range(1,10)]
# 4 * 3 크기의 2차원 리스트 초기화
n = 4
m = 3
array = [[0] * m for _ in range(n)]
# [[0,0,0], [0,0,0], [0,0,0], [0,0,0]]
2) 리스트 연산하기
(1) 리스트 더하기(+) : 2개의 리스트를 합한다.

(2) 리스트 반복하기(*)

(3) 리스트 길이 구하기

3) 리스트의 수정과 삭제
(1) 리스트에서 값 수정

(2) 리스트 요소 삭제 : del 함수로 리스트의 특정 요소를 삭제한다.


4) 리스트 관련 함수
(1) 요소 추가 : append (리스트의 맨 마지막에 요소 또는 리스트를 추가한다.)


(2) 리스트 정렬 : sort(list) (리스트의요소를 순서대로 정렬한다. - 기본적으로 오름차순, 알파벳순으로 정렬한다.)

(3) 리스트 뒤집기 : reverse(list) (현재 리스트 순서를 역순으로 뒤집는다.)

(4) 위치 반환 : index(x)

(5) 리스트에 요소 삽입 : insert(a, b) (리스트 a번째 위치에 b를 삽입한다.)

(6) 리스트 요소 제거 : remove(x) (리스트에서 첫 번째로 나오는 x를 삭제한다.)
- 두 번째 x부터는 삭제하지 않는다. → 삭제하려면 별도로 함수를 작성해야 한다.

# 리스트에서 특정 값을 갖는 원소를 모두 제거하기
a = [1, 2, 3, 4, 5, 5, 5]
remove_set = {3, 5} # 집합 자료형
# remove_set에 포함되지 않은 값만 저장
result = [i for i in a if i not in remove_set]
# 결과 : [1, 2, 4]
(7) 리스트 요소 끄집어내기 : pop() (리스트의 맨 마지막 요소 반환 후, 그 요소를 삭제한다.)

pop(x) (리스트의 x번째 요소를 반환 후, 그 요소를 삭제한다.)

(8) 리스트에 포함된 요소 x의 개수 세기 : count(x)

(9) 리스트 확장 : extend(x) (x는 리스트만 가능하고, 원래 리스트에 x라는 리스트를 더하는 개념이다.)

4. 튜플 자료형
- 튜플과 리스트의 차이점
1. 리스트는 []로, 튜플은 ()로 둘러싼다.
2. 리스트는 그 값의 생성, 삭제, 수정이 가능하지만, 튜플은 값을 바꿀 수 없다.
3. 튜플은 한 개의 요소를 가질 때에는 요소 뒤에 콤마를 반드시 붙여야 한다.
4. 튜플은 괄호를 생략해도 된다.

→ 이외에 인덱싱, 슬라이싱, 더하기, 곱하기, 길이 구하기 등의 방법은 리스트와 모두 같다.
<튜플을 사용하면 좋은 경우>
- 서로 다른 성질의 데이터를 묶어서 관리할 경우
- 최단 경로 알고리즘에서 (비용, 노드 번호)의 형태로 튜플 자료형을 자주 사용한다.
- 데이터의 나열을 Hashing의 키 값으로 사용해야 할 때
- 튜플은 변경이 불가능하다. 따라서 리스트와 달리 키 값으로 사용할 수 있다.
- 리스트보다 메모리를 효율적으로 사용해야 할 때 사용한다.
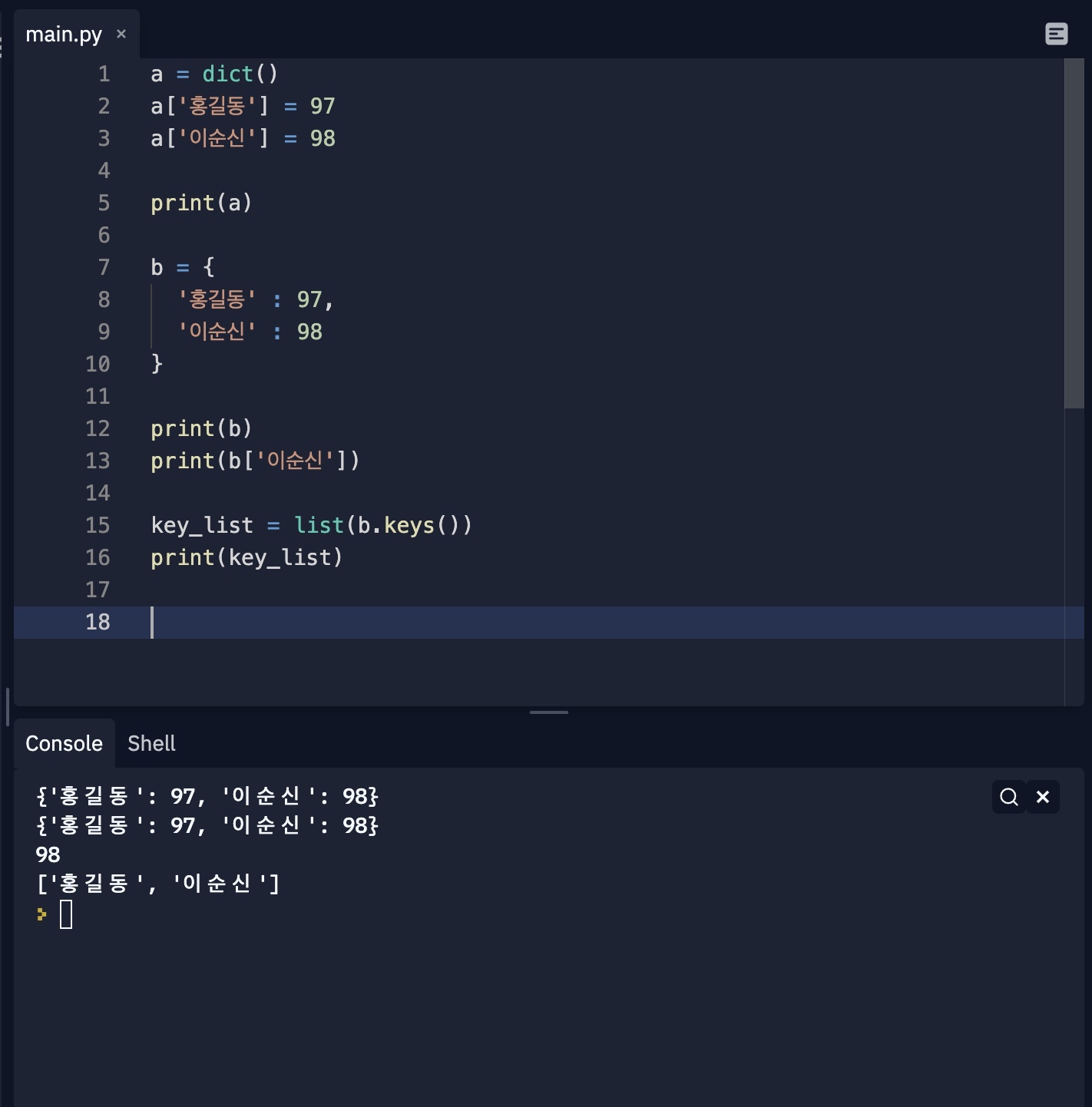
5. 딕셔너리 자료형 : Key를 통해 Value를 얻음
1) 딕셔너리의 모습

- Key와 Value 여러 쌍이 {}로 둘러쌓인다.
- Value에 리스트도 넣을 수 있다. (Key에는 불가능)
- 쌍을 추가하거나 del로 삭제할 수 있다.
- 관련 함수는 다음과 같다.
- keys(), values(), items(), clear(), get(key), [key] in [list]
2) 딕셔너리의 특징
- 리스트, 튜플이 값을 순차적으로 저장하는 것과 달리, Key와 Value의 쌍을 데이터로 가진다.
- 원하는 'Immutable(변경 불가능한) 자료형'을 Key로 사용할 수 있음
- 파이썬의 딕셔너리 자료형은 Hash Table을 이용하므로 데이터의 조회 및 수정에 있어 O(1)의 시간에 처리할 수 있다.
- 문자열 등의 Key를 이용하여 데이터를 관리 및 저장할 때 List보다 훨씬 효율적으로 사용할 수 있다.
- 키와 값을 별도로 뽑아내기 위한 메서드를 지원한다.
- keys() : 키 데이터만 뽑아 리스트로 이용한다.
- values() : 값 데이터만 뽑아 리스트로 이용한다.

7. 집합 자료형
1) 집합 자료형의 특징
- 중복을 허용하지 않는다.
- 순서가 없다.
- 리스트 or 문자열을 이용하여 초기화가 가능하다.
- 이때, set() 함수를 사용한다.
- 중괄호 '{}' 안에 각 원소를 콤마를 기준으로 구분하여 삽입하여 초기화할 수 있다.
- 데이터의 조회 및 수정에 있어 O(1)의 시간에 처리가 가능하다.

2) 집합 자료형의 연산 : 합집합, 교집합, 차집합 연산 사용 가능
- 합집합 : |
- 교집합 : &
- 차집합 : -

3) 집합 자료형 관련 메소드
- add() : 새로운 원소를 추가한다.
- updata() : 새로운 원소 여러 개를 추가한다.
- remove() : 특정 값을 갖는 원소를 삭제한다.

<사전(딕셔너리) 자료형 & 집합 자료형의 특징>
- 리스트나 튜플은 순서가 있어 인덱싱을 통해 자료형의 값을 얻는다.
- 사전 자료형과 집합 자료형은 순서가 없어 인덱싱으로 값을 얻을 수 없다.
- 사전의 키(Key) 혹은 집합의 원소(Element)를 이용해 O(1)의 시간복잡도로 조회한다.
7. 변수
1) 변수를 만드는 여러가지 방법
>>> a, b = ('python', 'life')
>>> (a, b) = 'python', 'life'튜플을 통해 a, b에 값을 대입한다. (두 방법이 완전히 똑같음)
>>> [a, b] = ['python', 'life']위와 같이 리스트로 변수를 만들 수 있다.
>>> a = b = 'python'위와 같이 여러 개의 변수에 같은 값을 대입할 수 있다.
728x90








최근댓글