Pytorch를 간단히 다루어본 적이 있는데, 앞으로의 연구에 익숙하게 활용하기 위해 Pytorch 내용을 정리해보려 한다.
대부분의 내용은 유튜브의 '모두를 위한 딥러닝 시즌2'를 참고하였다.
https://www.youtube.com/watch?v=St7EhvnFi6c&list=PLQ28Nx3M4JrhkqBVIXg-i5_CVVoS1UzAv&index=2
간단한 설명이 포함된 실습 자료는 다음 Github를 참조하자.
https://github.com/JJukE/Pytorch_DL_for_everyone
GitHub - JJukE/Pytorch_DL_for_everyone: 파이토치 익히기 위해 '모두를 위한 딥러닝' 수강
파이토치 익히기 위해 '모두를 위한 딥러닝' 수강. Contribute to JJukE/Pytorch_DL_for_everyone development by creating an account on GitHub.
github.com
1. Vector, Matrix and Tensor
딥러닝에서는 'Tensor'라는 데이터 단위를 사용한다. 이는 개념적으로 벡터, 행렬과 매우 유사하다.
데이터를 다룰 때에 이 Tensor의 크기(Size, Shape)가 매우 중요하므로, 개념을 잘 숙지해두자.

0차원 Tensor는 차원이 없는 값으로, Scalar에 해당한다.
1D Tensor는 Vector이고, 2D Tensor는 Matrix로 볼 수 있다.
이러한 방식으로 차원을 하나씩 추가해 나갈 때마다 3D, 4D, 5D Tensor 등이 된다.
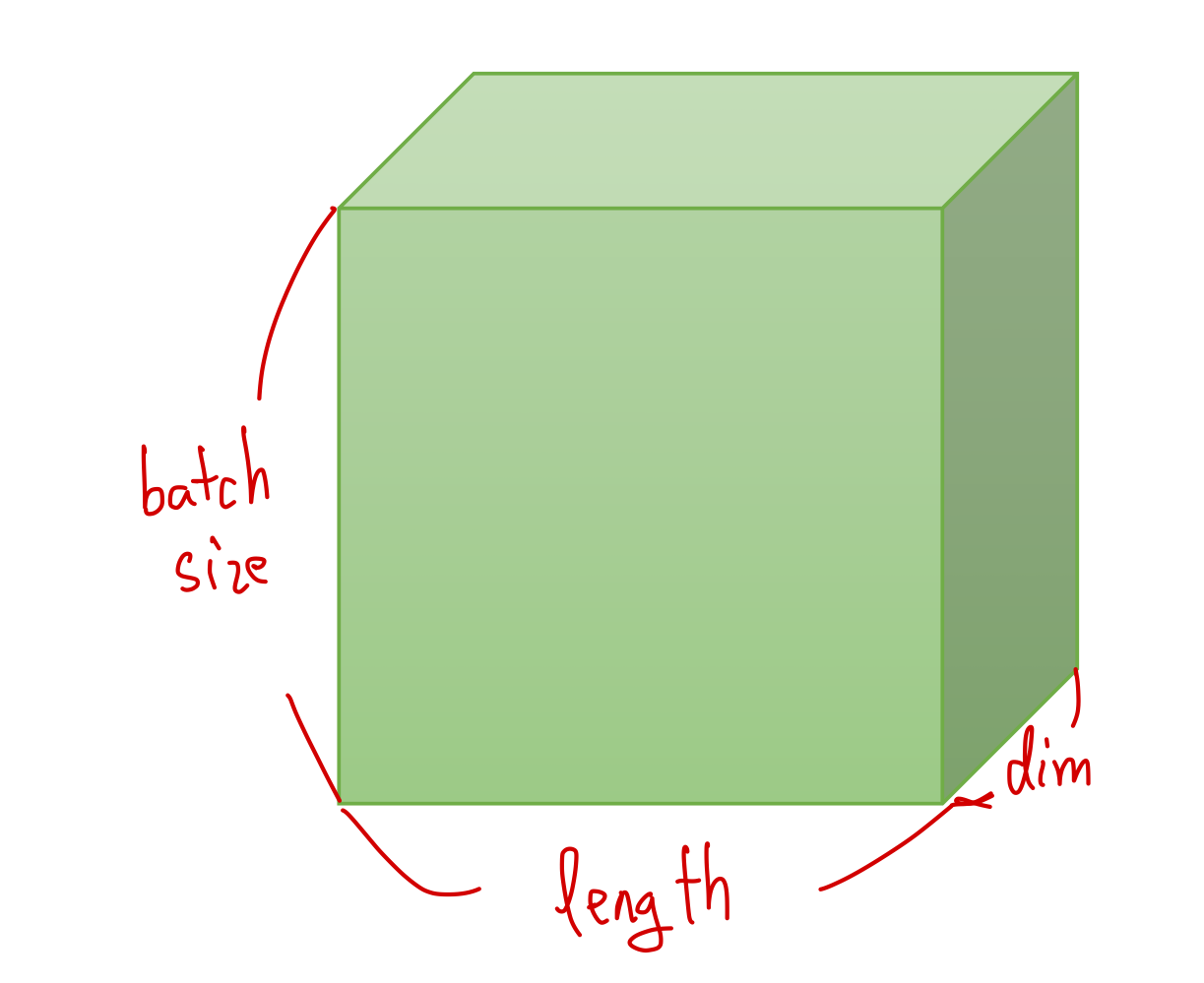
1) 2D Tensor (Typical Simple Setting)
2D Tensor의 전형적인 예는 'batch size', 'dimension'이라는 차원을 갖는 형태의 Tensor이다.
만약 batch size를 64, dimension이 256인 데이터가 있다면, 이를 '64 by 256 2D Tensor'라 한다.
2) 3D Tensor (Typical Computer Vision)
Computer Vision 분야에서 일반적으로 사용하는 3D Tensor를 살펴보자.

위와 같이 이미지 하나가 (width, height)의 차원을 갖고, 이러한 이미지가 여러 장 모여 3D Tensor를 이루는 형태이다.
3) 3D Tensor (Typical Natural Language Processing)
이번에는 같은 3D Tensor이지만, 자연어 처리(Natural Language Processing) 분야에서 사용되는 시계열 데이터(Sequential Data)의 전형적인 형태를 살펴보자.
CV에서는 이미지가 한 층을 이루었으나, NLP에서의 Sequential Data는 한 문장이 한 층을 이루게 된다.
이러한 문장이 시간 순서대로 층을 이루어 쌓이면 위와 같은 3D Tensor 형태를 갖는다.
[Implementation]
1) Numpy Review, PyTorch Tensor 선언
PyTorch 실습에 앞서, 데이터를 다루어본 사람이라면 누구나 한 번쯤 써봤을 법한 'Numpy'를 간단하게 리뷰해보자.
벡터, 행렬, 스칼라를 다루는 데 있어 비슷한 방식을 사용하므로 Numpy를 사용해본 사람이라면 금방 PyTorch의 tensor를 다룰 수 있을 것이다.
(1) 1D, 2D Array with Numpy
numpy에서 1d 또는 2d array는 다음과 같이 선언한다.
t = np.array([0., 1., 2., 3., 4., 5., 6.]) # (7, ) 1d vector
t = np.array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.],
[10., 11., 12.]]) # 4 by 3 matrix
또한, 다음과 같이 차원(rank or dimension)과 크기(size or shape)를 나타낼 수 있다.
t.ndim
t.shape
그리고, 파이썬의 인덱싱을 사용하여 element를 표현하거나 slicing이 가능하다.
실습 결과는 다음과 같다.

(2) PyTorch Tensor
이를 이해한다면, PyTorch에서 Tensor를 선언하는 것도 금방 익숙해질 수 있다.
PyTorch에서 1D, 2D Tensor를 선언하는 방법은 다음과 같다. (datatype : float, 실제로 int, long, bool 등 다양한 datatype 존재)
t = torch.FloatTensor([0., 1., 2., 3., 4., 5., 6.]) # 1d tensor
t = torch.FloatTensor([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.],
[10., 11., 12.]]) # 2d tensor
또한, rank, shape, slicing 등 크기를 나타내거나 특정 부분을 인덱싱하는 방법이 numpy와 거의 비슷하다.
print(t.dim()) # rank
print(t.shape) # shape
print(t.size()) # shape
print(t[0], t[1], t[-1]) # element
print(t[2:5], t[4:-1]) # slicing
print(t[:2], t[3:]) # slicing
실행 결과는 다음과 같다.


2) Broadcasting
행렬은 덧셈, 뺄셈 시에 크기(차원)가 같아야 한다. 또한, 행렬곱을 수행하려면 앞 행렬의 마지막 차원과 뒷 행렬의 첫 번째 차원이 같아야 한다.
하지만, Pytorch에서는 다른 크기의 행렬의 연산을 Broadcasting을 통해 자동으로 맞추어 진행해준다.
자동으로 실행되므로, 컴파일 오류는 나지 않지만 원하지 않는 결과를 낼 수 있으므로, 사용자의 주의가 필요하다.

3) Multiplication vs Matrix Multiplication
일반적인 'mul'함수의 경우 element-wise 곱을 하고, 'matmul'함수의 경우 행렬곱을 수행한다.
이에 따라 서로 다른 두 행렬에 대해 broadcasting이 일어날 수도, 일어나지 않을 수도 있다.
m1 = torch.FloatTensor([[1, 2], [3, 4]]) # 2 by 2
m2 = torch.FloatTensor([[1], [2]]) # 2 by 1
m1.mul(m2) # element-wise multiplication
m1.matamul(m2) # Matrix Multiplication

4) Mean
mean 함수는 default로 tensor 전체 element의 평균을 구한다. 여기서, 정수형 데이터타입에는 사용할 수 없음에 유의하자.
t = torch.FloatTensor([[1, 2], [3, 4]])
t.mean() # 전체 element의 평균
t.mean(dim=0) # dim 0을 없앰 (행 방향, 즉 상하방향의 element의 평균)
t.mean(dim=1) # dim 1을 없앰 (열 방향, 즉 좌우방향의 element의 평균)
t.mean(dim=-1) # 마지막 dimension을 없앰

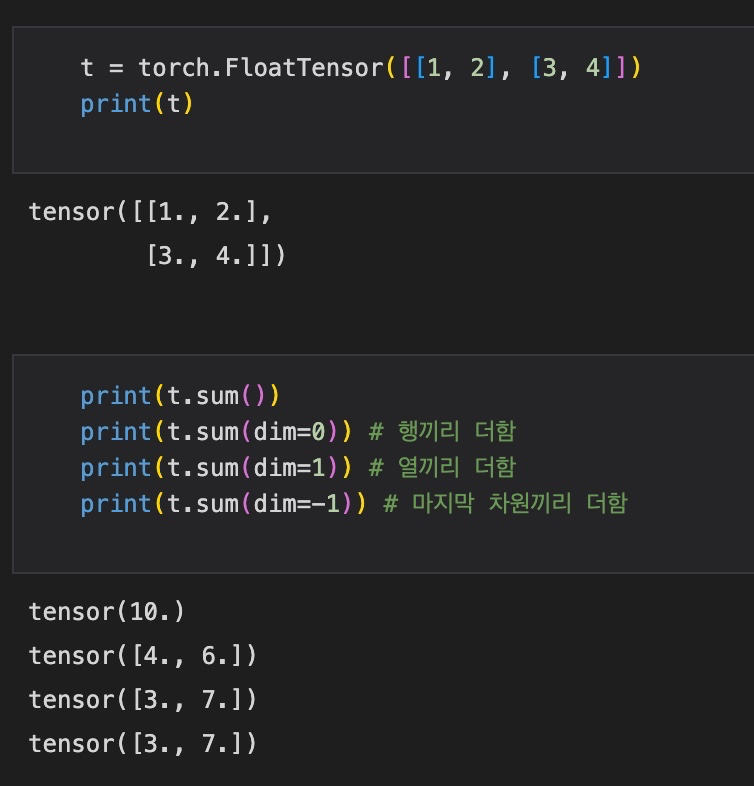
5) Sum
Sum 함수도 마찬가지로, default로 모든 element의 합을 구해주고, dim=0 옵션 부여 시 행끼리, dim=1 옵션 부여 시 열끼리 더해준다.
t = torch.FloatTensor([[1, 2], [3, 4]])
t.sum()
t.sum(dim=0) # 행끼리 더함
t.sum(dim=1) # 열끼리 더함
t.sum(dim=-1) # 마지막 차원끼리 더함
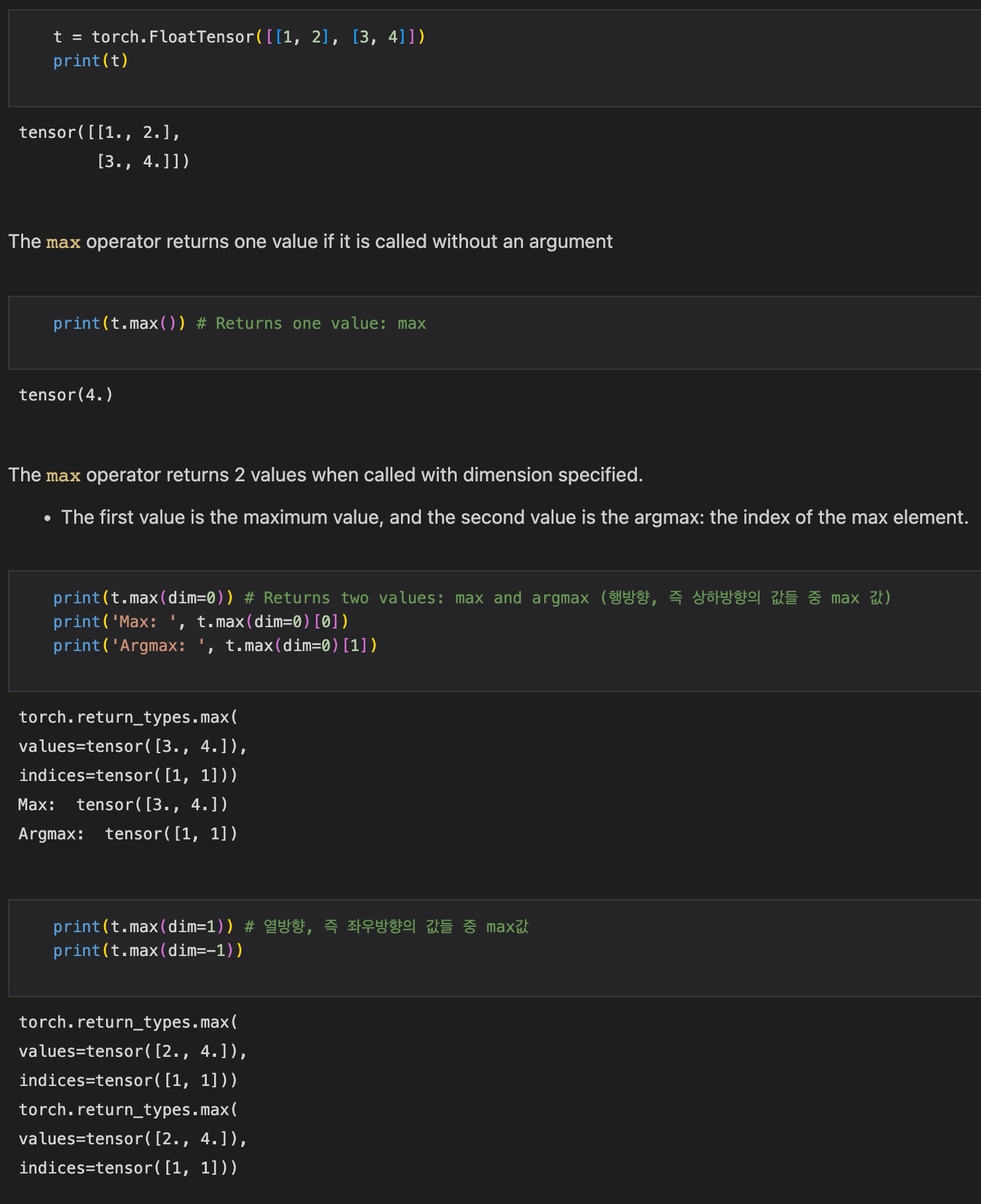
6) Max and Argmax
max operator는 인자 없이 호출될 경우 단순히 모든 요소 중 최댓값을 반환하고, dimension을 인자로 넘겨줄 경우, 2가지 값을 반환한다. 첫 번째 값은 최댓값, 두 번째 값은 최댓값의 index이다.
t = torch.FloatTensor([[1, 2], [3, 4]])
t.max()
t.max(dim=0) # 행방향, 즉 상하 방향의 값들 중 max 값과 argmax 반환
t.max(dim=1) # 열방향, 즉 좌우 방향의 값들 중 max 값과 argmax 반환
t.max(dim=-1) # 마지막 dimension에 맞추어 max 값과 argmax 반환
7) View
PyTorch에서의 View함수는 Numpy의 Reshape와 같은 역할을 한다.
즉, tensor의 크기를 수정할 수 있다. 이때 변동 가능한 차원을 '-1'로 표시하는데, 전체 shape의 차원의 곱이 같아야 한다.
t = torch.FloatTensor([[[0, 1, 2],
[3, 4, 5]],
[[6, 7, 8],
[9, 10, 11]]]) # 2 by 2 by 3
t.view([-1, 3])
t.view([-1, 1, 3])

두 번째 셀을 살펴보면, (2, 2, 3) 크기의 3D Tensor를 (변동 가능한 값, 3) 크기의 2D Tensor로 변환한다.
세 번째 셀에서도 마찬가지로 (변동 가능한 값, 1, 3) 크기의 3D Tensor로 변환한다.
이때 세 Tensor 모두 차원의 곱이 12로 같음을 확인할 수 있다.
8) Squeeze
Squeeze는 영어 단어 자체로 '짜낸다'라는 의미를 갖는다. dimension이 1인 경우 그것을 없애면서 tensor의 rank를 낮춰준다.
이때 dimension을 지정해주게 되면 해당 dimension이 1이 아니면 변화가 없고, 1이면 없애준다.
ft = torch.FloatTensor([[0], [1], [2]]) # size: (3, 1)
ft.squeeze() # size: (3, )
ft.squeeze(dim=0) # size: (3, 1) -> 아무 반응 x
ft.squeeze(dim=1) # size: (3, ) -> ft.squeeze()와 같은 결과

9) Unsqueeze
Squeeze의 반대로, 원하는 dimension을 추가해줄 수 있다. 추가해줄 dimension을 인자로 꼭 명시해주어야 한다.
ft = torch.Tensor([0, 1, 2]) # size: (3, )
ft.unsqueeze(0) # size: (1, 3)
ft.view(1, -1) # size: (1, 3) -> 위와 같은 결과
ft.unsqueeze(1) # size: (3, 1)
ft.unsqueeze(-1) # size: (3, 1)

10) Type Casting
Tensor의 datatype을 명시적으로 바꿔줄 수 있다.

11) Concatenating, Stacking
여러 Tensor를 이어붙이는 방법은 concatenate, stacking 등의 방법이 있다.
먼저 concatenate를 살펴보자.
dim=0의 경우, 행 방향(상하방향)으로 이어주고, dim=1인 경우 열 방향(좌우방향)으로 이어준다.
x = torch.FloatTensor([[1, 2], [3, 4]])
y = torch.FloatTensor([[5, 6], [7, 8]])
print(torch.cat([x, y], dim=0)) # 행을 concat
print(torch.cat([x, y], dim=1)) # 열을 concat

다음으로, Stacking을 살펴보자.
Stack은 여러 tensor를 쌓을 때, concat보다 좀 더 편하게 이어줄 수 있는 함수이다.
예를 들어 1D tensor 여러 개를 2D tensor로 쌓아주는 경우, cat 함수를 사용하려면 unsqueeze를 통해 차원을 확장시킨 후에 이어줄 수 있다.
하지만 Stack을 사용하면 간단하게 리스트로 묶어주어 바로 연결시켜줄 수 있다.
# 3 개의 1D vector (2, )에 대해
x = torch.FloatTensor([1, 4])
y = torch.FloatTensor([2, 5])
z = torch.FloatTensor([3, 6])
# Stacking
print(torch.stack([x, y, z])) # 쌓을 방향은 default가 행방향
print(torch.stack([x, y, z], dim=1)) # 열 방향으로 쌓음
# Concatenating
print(torch.cat([x.unsqueeze(0), y.unsqueeze(0), z.unsqueeze(0) ], dim=0))

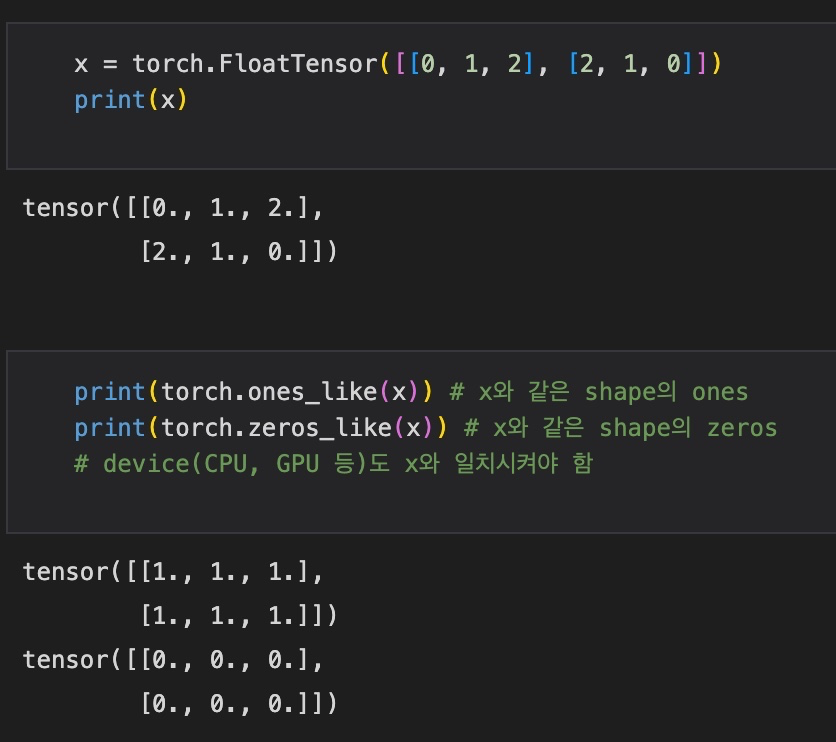
12) Ones and Zeros
ones는 모든 요소가 1인 행렬을 생성하는 것이고, zeros는 모든 요소가 0인 행렬을 생성해주는 함수이다.
PyTorch에서는 특정 행렬 x에 대해 x와 같은 크기의 ones 또는 zeros를 생성해줄 수 있다.
x = torch.FloatTensor([[0, 1, 2], [2, 1, 0]])
print(torch.ones_like(x)) # x와 같은 shape의 ones
print(torch.zeros_like(x)) # x와 같은 shape의 zeros
# device(CPU, GPU 등)도 x와 일치시켜야 함
13) In-place Operation
보통 위에서 언급한 함수들을 포함하여 대부분의 PyTorch 내에서 Tensor를 다루는 함수들은 새로운 메모리를 할당하여 그 결과를 저장하고, 원래 tensor는 변하지 않는다.
하지만, 함수 뒤에 '_'를 포함하여 사용하면 해당 tensor 자체에 연산을 적용시켜 tensor를 변환시킨다. (하지만, PyTorch 자체에 garbage collector가 잘 설계되어 있어, 연산 속도가 크게 차이나지는 않는다고 한다.)

14) 기타 기억해야 할 함수들 (계속 추가할 예정)
(1) Tensor.item()
Tensor의 값을 표준 파이썬 number로 반환해준다.
텐서가 스칼라(element가 한 개)일 때에만 사용 가능하다. (여러 개인 경우 tolist()함수 사용하여 표현)








최근댓글